 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChimera: A Block-Based Neural Architecture Search Framework for Event-Based Object Detection
Dec 27, 2024



Event-based cameras are sensors that simulate the human eye, offering advantages such as high-speed robustness and low power consumption. Established Deep Learning techniques have shown effectiveness in processing event data. Chimera is a Block-Based Neural Architecture Search (NAS) framework specifically designed for Event-Based Object Detection, aiming to create a systematic approach for adapting RGB-domain processing methods to the event domain. The Chimera design space is constructed from various macroblocks, including Attention blocks, Convolutions, State Space Models, and MLP-mixer-based architectures, which provide a valuable trade-off between local and global processing capabilities, as well as varying levels of complexity. The results on the PErson Detection in Robotics (PEDRo) dataset demonstrated performance levels comparable to leading state-of-the-art models, alongside an average parameter reduction of 1.6 times.
A Recurrent YOLOv8-based framework for Event-Based Object Detection
Aug 09, 2024



Object detection is crucial in various cutting-edge applications, such as autonomous vehicles and advanced robotics systems, primarily relying on data from conventional frame-based RGB sensors. However, these sensors often struggle with issues like motion blur and poor performance in challenging lighting conditions. In response to these challenges, event-based cameras have emerged as an innovative paradigm. These cameras, mimicking the human eye, demonstrate superior performance in environments with fast motion and extreme lighting conditions while consuming less power. This study introduces ReYOLOv8, an advanced object detection framework that enhances a leading frame-based detection system with spatiotemporal modeling capabilities. We implemented a low-latency, memory-efficient method for encoding event data to boost the system's performance. We also developed a novel data augmentation technique tailored to leverage the unique attributes of event data, thus improving detection accuracy. Our models outperformed all comparable approaches in the GEN1 dataset, focusing on automotive applications, achieving mean Average Precision (mAP) improvements of 5%, 2.8%, and 2.5% across nano, small, and medium scales, respectively.These enhancements were achieved while reducing the number of trainable parameters by an average of 4.43% and maintaining real-time processing speeds between 9.2ms and 15.5ms. On the PEDRo dataset, which targets robotics applications, our models showed mAP improvements ranging from 9% to 18%, with 14.5x and 3.8x smaller models and an average speed enhancement of 1.67x.
Thermal Heating in ReRAM Crossbar Arrays: Challenges and Solutions
Dec 28, 2022Increasing popularity of deep-learning-powered applications raises the issue of vulnerability of neural networks to adversarial attacks. In other words, hardly perceptible changes in input data lead to the output error in neural network hindering their utilization in applications that involve decisions with security risks. A number of previous works have already thoroughly evaluated the most commonly used configuration - Convolutional Neural Networks (CNNs) against different types of adversarial attacks. Moreover, recent works demonstrated transferability of the some adversarial examples across different neural network models. This paper studied robustness of the new emerging models such as SpinalNet-based neural networks and Compact Convolutional Transformers (CCT) on image classification problem of CIFAR-10 dataset. Each architecture was tested against four White-box attacks and three Black-box attacks. Unlike VGG and SpinalNet models, attention-based CCT configuration demonstrated large span between strong robustness and vulnerability to adversarial examples. Eventually, the study of transferability between VGG, VGG-inspired SpinalNet and pretrained CCT 7/3x1 models was conducted. It was shown that despite high effectiveness of the attack on the certain individual model, this does not guarantee the transferability to other models.
Resistive Neural Hardware Accelerators
Sep 08, 2021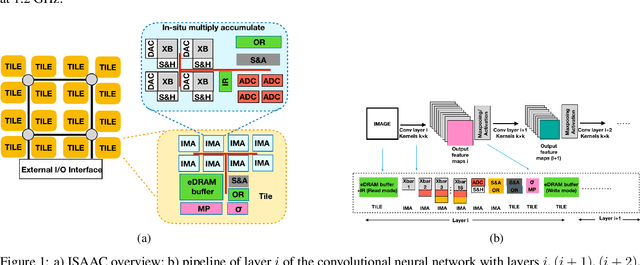
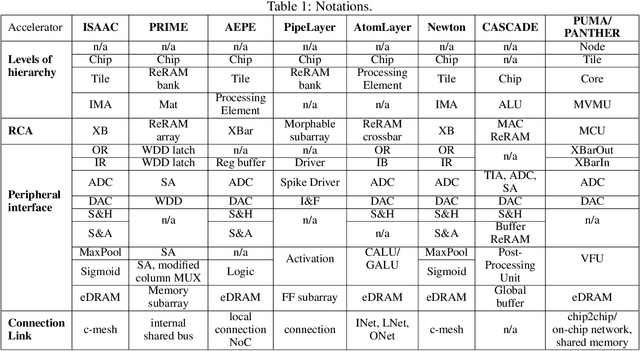
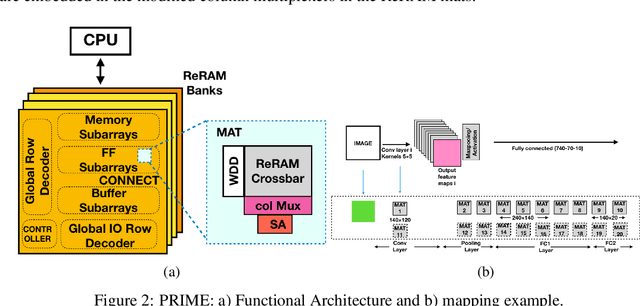
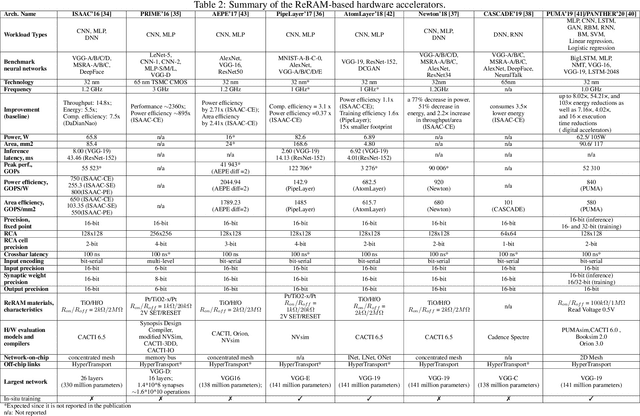
Deep Neural Networks (DNNs), as a subset of Machine Learning (ML) techniques, entail that real-world data can be learned and that decisions can be made in real-time. However, their wide adoption is hindered by a number of software and hardware limitations. The existing general-purpose hardware platforms used to accelerate DNNs are facing new challenges associated with the growing amount of data and are exponentially increasing the complexity of computations. An emerging non-volatile memory (NVM) devices and processing-in-memory (PIM) paradigm is creating a new hardware architecture generation with increased computing and storage capabilities. In particular, the shift towards ReRAM-based in-memory computing has great potential in the implementation of area and power efficient inference and in training large-scale neural network architectures. These can accelerate the process of the IoT-enabled AI technologies entering our daily life. In this survey, we review the state-of-the-art ReRAM-based DNN many-core accelerators, and their superiority compared to CMOS counterparts was shown. The review covers different aspects of hardware and software realization of DNN accelerators, their present limitations, and future prospectives. In particular, comparison of the accelerators shows the need for the introduction of new performance metrics and benchmarking standards. In addition, the major concerns regarding the efficient design of accelerators include a lack of accuracy in simulation tools for software and hardware co-design.
Wafer Quality Inspection using Memristive LSTM, ANN, DNN and HTM
Sep 27, 2018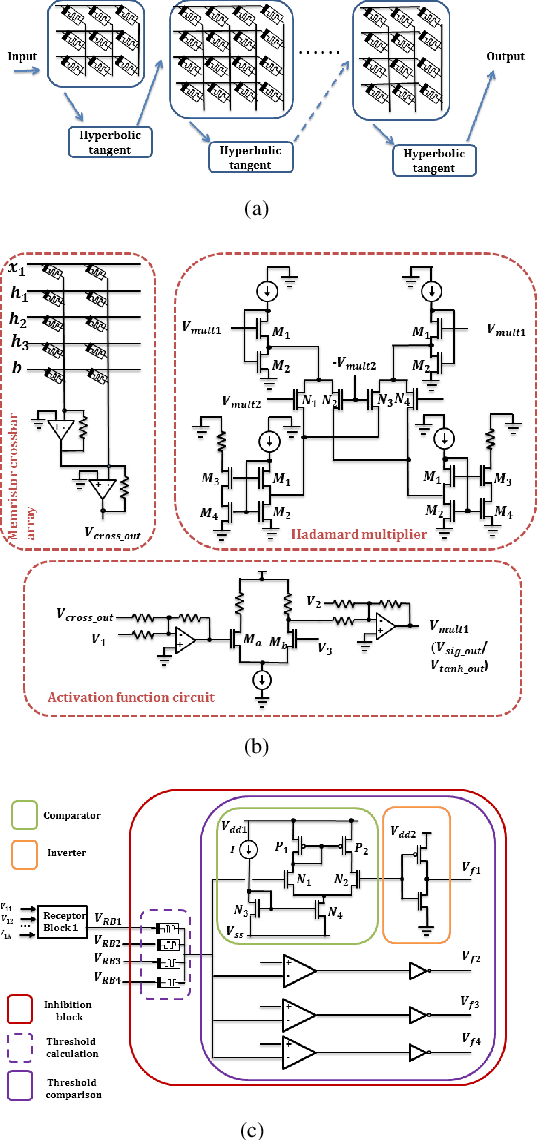
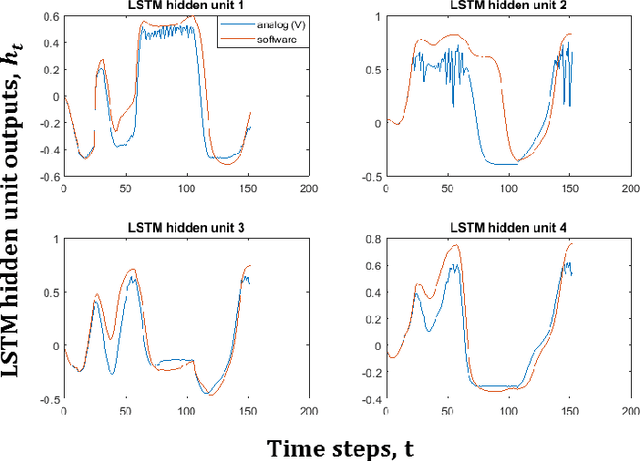
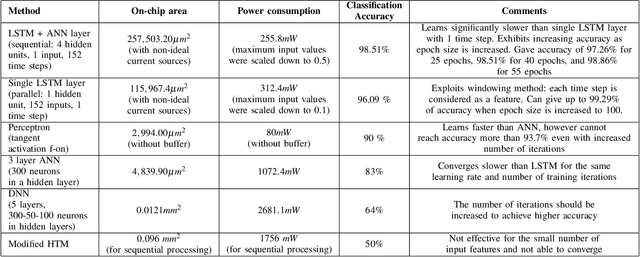
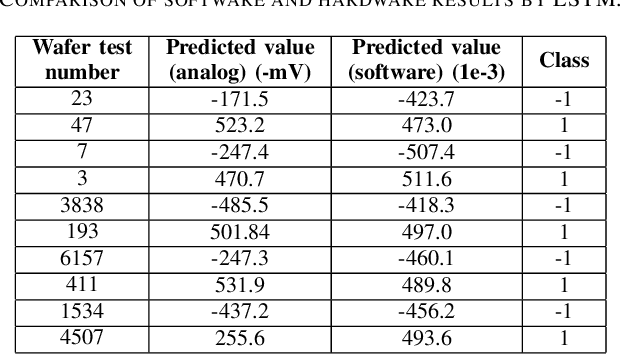
The automated wafer inspection and quality control is a complex and time-consuming task, which can speed up using neuromorphic memristive architectures, as a separate inspection device or integrating directly into sensors. This paper presents the performance analysis and comparison of different neuromorphic architectures for patterned wafer quality inspection and classification. The application of non-volatile memristive devices in these architectures ensures low power consumption, small on-chip area scalability. We demonstrate that Long-Short Term Memory (LSTM) outperforms other architectures for the same number of training iterations, and has relatively low on-chip area and power consumption.
Memristive LSTM network hardware architecture for time-series predictive modeling problem
Sep 10, 2018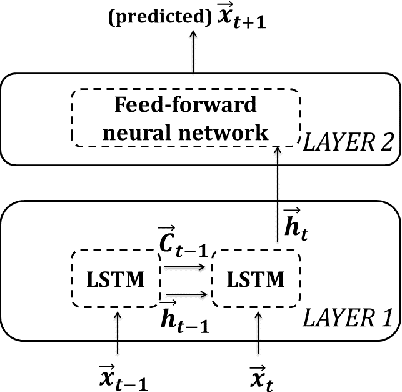
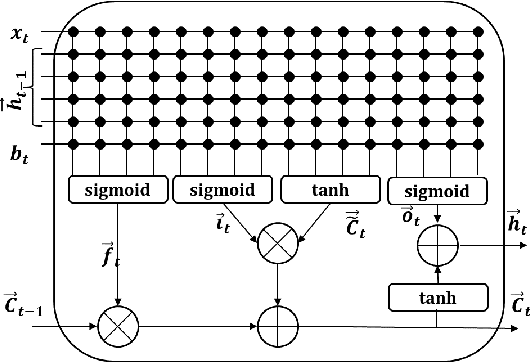
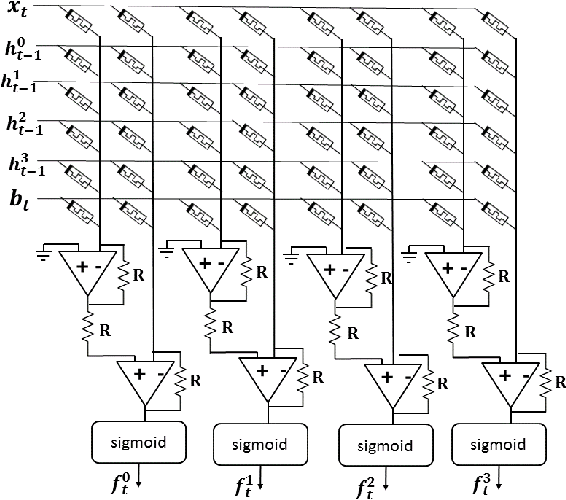
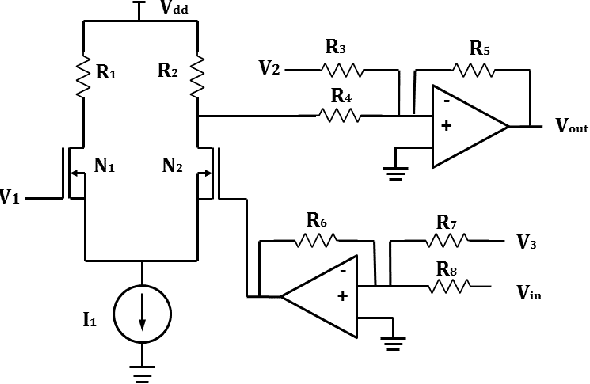
Analysis of time-series data allows to identify long-term trends and make predictions that can help to improve our lives. With the rapid development of artificial neural networks, long short-term memory (LSTM) recurrent neural network (RNN) configuration is found to be capable in dealing with time-series forecasting problems where data points are time-dependent and possess seasonality trends. Gated structure of LSTM cell and flexibility in network topology (one-to-many, many-to-one, etc.) allows to model systems with multiple input variables and control several parameters such as the size of the look-back window to make a prediction and number of time steps to be predicted. These make LSTM attractive tool over conventional methods such as autoregression models, the simple average, moving average, naive approach, ARIMA, Holt's linear trend method, Holt's Winter seasonal method, and others. In this paper, we propose a hardware implementation of LSTM network architecture for time-series forecasting problem. All simulations were performed using TSMC 0.18um CMOS technology and HP memristor model.