 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResistive Neural Hardware Accelerators
Paper and Code
Sep 08, 2021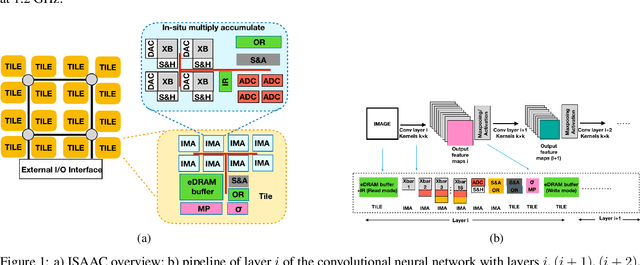
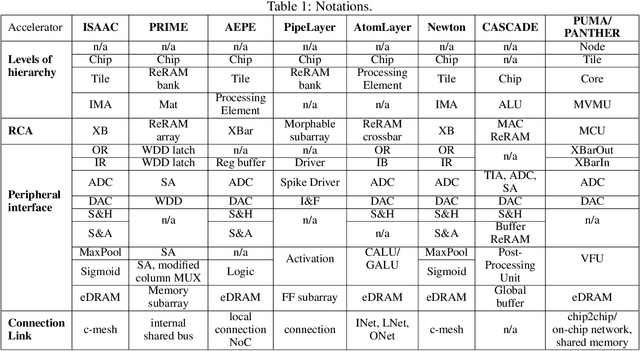
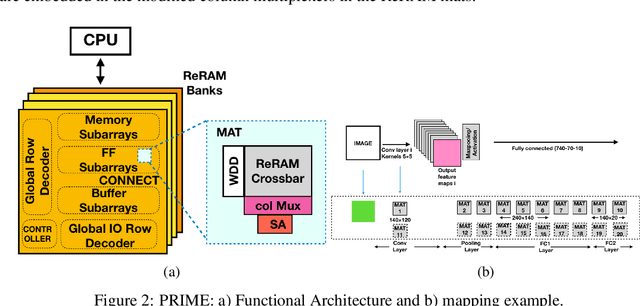
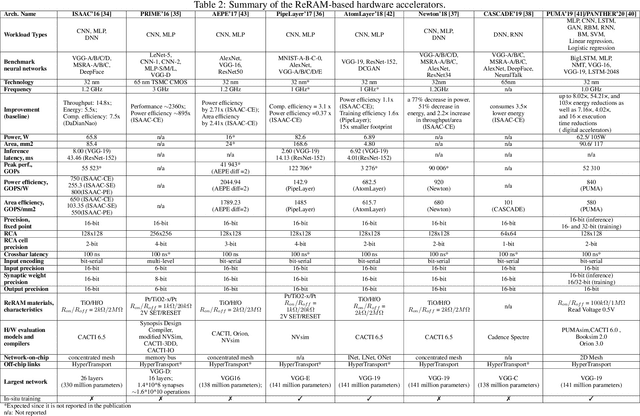
Deep Neural Networks (DNNs), as a subset of Machine Learning (ML) techniques, entail that real-world data can be learned and that decisions can be made in real-time. However, their wide adoption is hindered by a number of software and hardware limitations. The existing general-purpose hardware platforms used to accelerate DNNs are facing new challenges associated with the growing amount of data and are exponentially increasing the complexity of computations. An emerging non-volatile memory (NVM) devices and processing-in-memory (PIM) paradigm is creating a new hardware architecture generation with increased computing and storage capabilities. In particular, the shift towards ReRAM-based in-memory computing has great potential in the implementation of area and power efficient inference and in training large-scale neural network architectures. These can accelerate the process of the IoT-enabled AI technologies entering our daily life. In this survey, we review the state-of-the-art ReRAM-based DNN many-core accelerators, and their superiority compared to CMOS counterparts was shown. The review covers different aspects of hardware and software realization of DNN accelerators, their present limitations, and future prospectives. In particular, comparison of the accelerators shows the need for the introduction of new performance metrics and benchmarking standards. In addition, the major concerns regarding the efficient design of accelerators include a lack of accuracy in simulation tools for software and hardware co-design.