 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Neural Networks: A Survey
Paper and Code

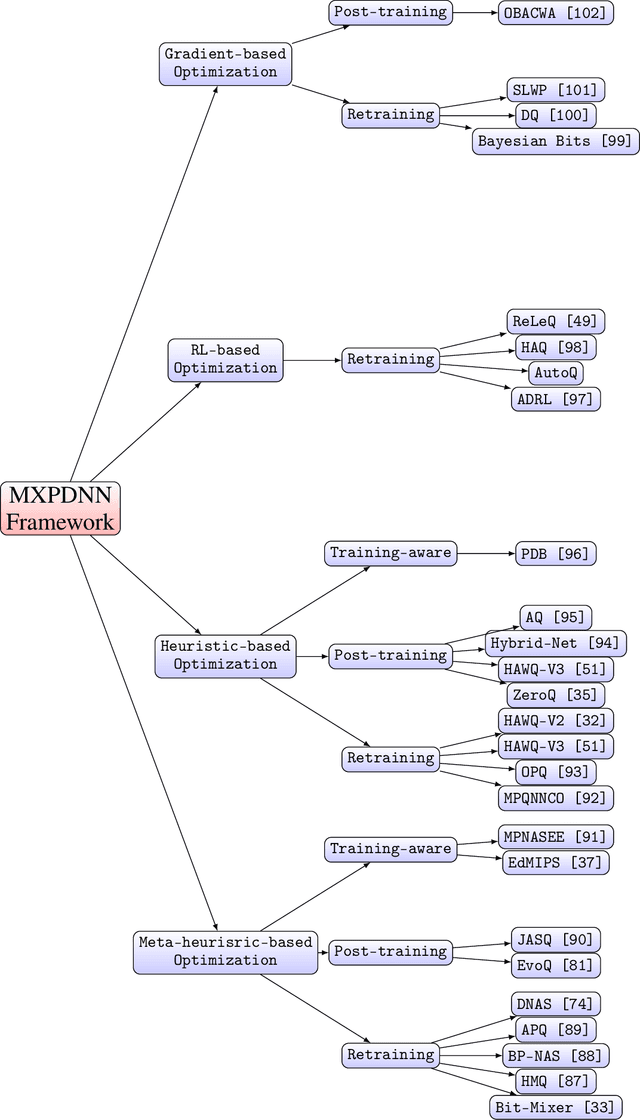

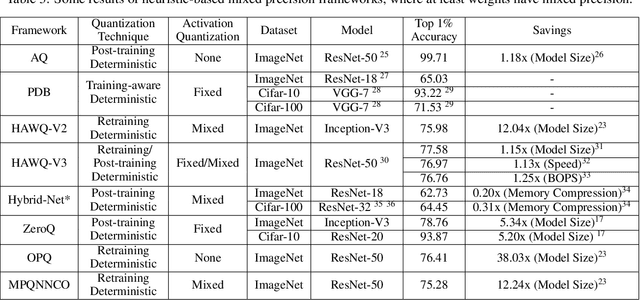
Mixed-precision Deep Neural Networks achieve the energy efficiency and throughput needed for hardware deployment, particularly when the resources are limited, without sacrificing accuracy. However, the optimal per-layer bit precision that preserves accuracy is not easily found, especially with the abundance of models, datasets, and quantization techniques that creates an enormous search space. In order to tackle this difficulty, a body of literature has emerged recently, and several frameworks that achieved promising accuracy results have been proposed. In this paper, we start by summarizing the quantization techniques used generally in literature. Then, we present a thorough survey of the mixed-precision frameworks, categorized according to their optimization techniques such as reinforcement learning and quantization techniques like deterministic rounding. Furthermore, the advantages and shortcomings of each framework are discussed, where we present a juxtaposition. We finally give guidelines for future mixed-precision frameworks.