 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble-based Transfer Learning for Low-resource Machine Translation Quality Estimation
Paper and Code
May 17, 2021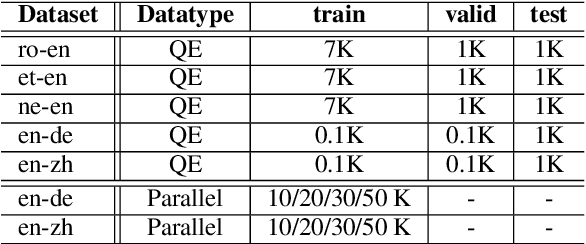

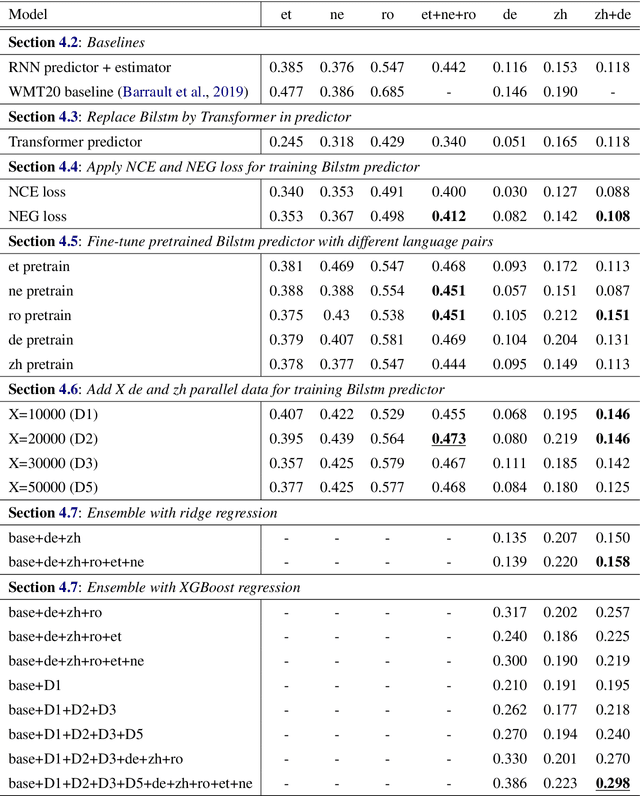
Quality Estimation (QE) of Machine Translation (MT) is a task to estimate the quality scores for given translation outputs from an unknown MT system. However, QE scores for low-resource languages are usually intractable and hard to collect. In this paper, we focus on the Sentence-Level QE Shared Task of the Fifth Conference on Machine Translation (WMT20), but in a more challenging setting. We aim to predict QE scores of given translation outputs when barely none of QE scores of that paired languages are given during training. We propose an ensemble-based predictor-estimator QE model with transfer learning to overcome such QE data scarcity challenge by leveraging QE scores from other miscellaneous languages and translation results of targeted languages. Based on the evaluation results, we provide a detailed analysis of how each of our extension affects QE models on the reliability and the generalization ability to perform transfer learning under multilingual tasks. Finally, we achieve the best performance on the ensemble model combining the models pretrained by individual languages as well as different levels of parallel trained corpus with a Pearson's correlation of 0.298, which is 2.54 times higher than baselines.