 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Causal Intervention Meets Image Masking and Adversarial Perturbation for Deep Neural Networks
Paper and Code
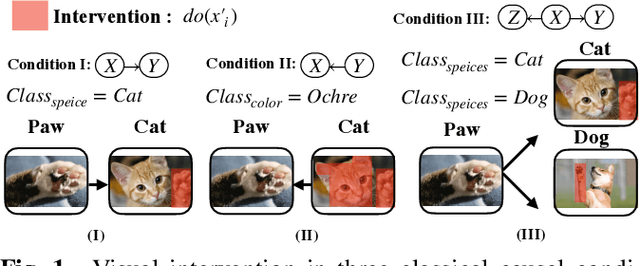
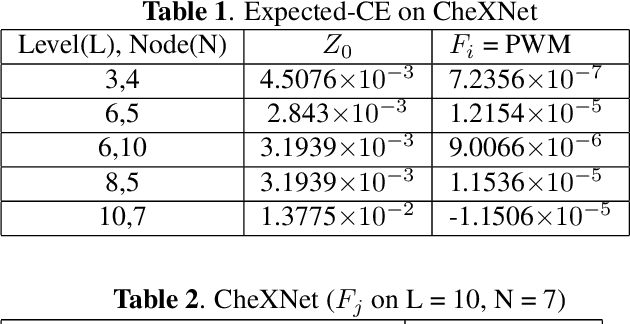
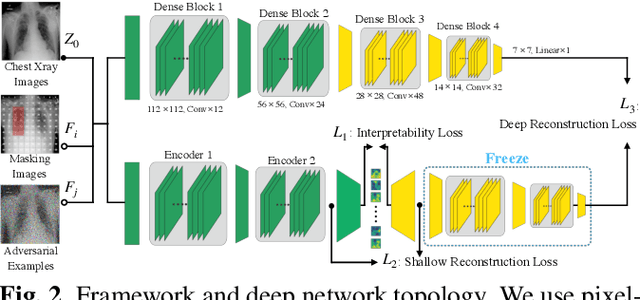

Discovering and exploiting the causality in deep neural networks (DNNs) are crucial challenges for understanding and reasoning causal effects (CE) on an explainable visual model. "Intervention" has been widely used for recognizing a causal relation ontologically. In this paper, we propose a causal inference framework for visual reasoning via do-calculus. To study the intervention effects on pixel-level feature(s) for causal reasoning, we introduce pixel-wise masking and adversarial perturbation. In our framework, CE is calculated using features in a latent space and perturbed prediction from a DNN-based model. We further provide a first look into the characteristics of discovered CE of adversarially perturbed images generated by gradient-based methods. Experimental results show that CE is a competitive and robust index for understanding DNNs when compared with conventional methods such as class-activation mappings (CAMs) on the ChestX-ray 14 dataset for human-interpretable feature(s) (e.g., symptom) reasoning. Moreover, CE holds promises for detecting adversarial examples as it possesses distinct characteristics in the presence of adversarial perturbations.