 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Self-Attention Temporal Reasoning for Driving Behavior Understanding
Paper and Code
Nov 06, 2019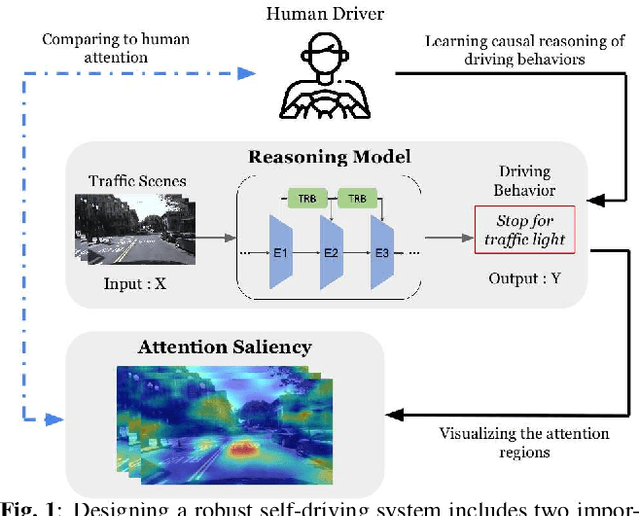
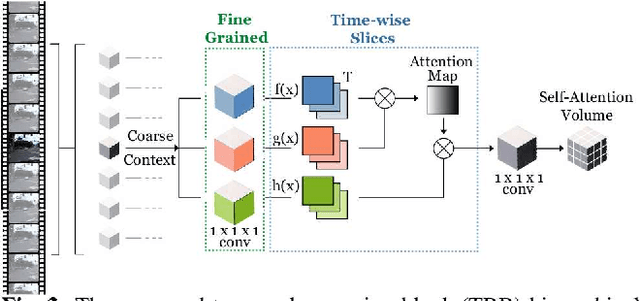
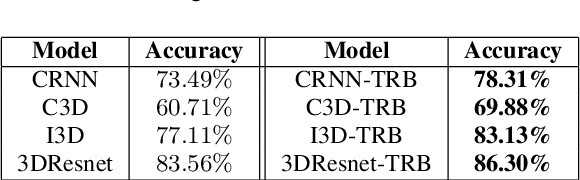
Performing driving behaviors based on causal reasoning is essential to ensure driving safety. In this work, we investigated how state-of-the-art 3D Convolutional Neural Networks (CNNs) perform on classifying driving behaviors based on causal reasoning. We proposed a perturbation-based visual explanation method to inspect the models' performance visually. By examining the video attention saliency, we found that existing models could not precisely capture the causes (e.g., traffic light) of the specific action (e.g., stopping). Therefore, the Temporal Reasoning Block (TRB) was proposed and introduced to the models. With the TRB models, we achieved the accuracy of $\mathbf{86.3\%}$, which outperform the state-of-the-art 3D CNNs from previous works. The attention saliency also demonstrated that TRB helped models focus on the causes more precisely. With both numerical and visual evaluations, we concluded that our proposed TRB models were able to provide accurate driving behavior prediction by learning the causal reasoning of the behaviors.