 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Representation Learning for Automatic Speech Recognition
Aug 07, 2023



Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Learning When to Trust Which Teacher for Weakly Supervised ASR
Jun 21, 2023



Automatic speech recognition (ASR) training can utilize multiple experts as teacher models, each trained on a specific domain or accent. Teacher models may be opaque in nature since their architecture may be not be known or their training cadence is different from that of the student ASR model. Still, the student models are updated incrementally using the pseudo-labels generated independently by the expert teachers. In this paper, we exploit supervision from multiple domain experts in training student ASR models. This training strategy is especially useful in scenarios where few or no human transcriptions are available. To that end, we propose a Smart-Weighter mechanism that selects an appropriate expert based on the input audio, and then trains the student model in an unsupervised setting. We show the efficacy of our approach using LibriSpeech and LibriLight benchmarks and find an improvement of 4 to 25\% over baselines that uniformly weight all the experts, use a single expert model, or combine experts using ROVER.
Federated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023



Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
Can Calibration Improve Sample Prioritization?
Oct 12, 2022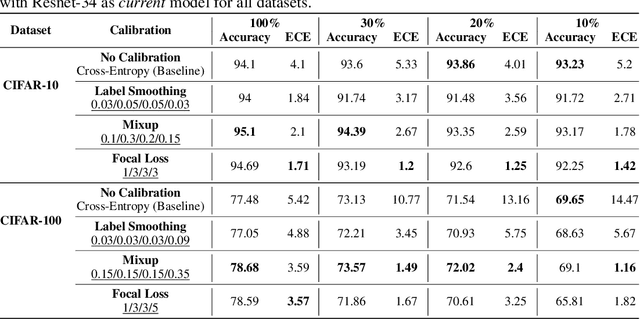
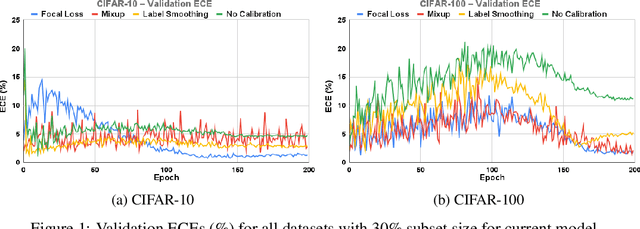
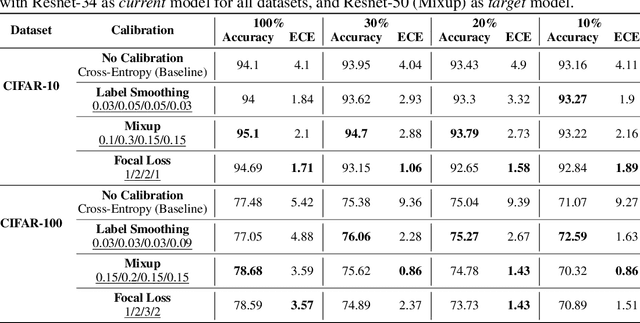
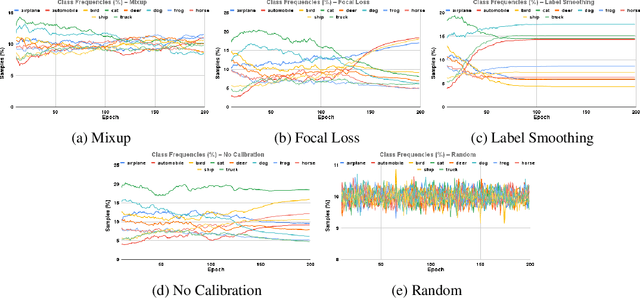
Calibration can reduce overconfident predictions of deep neural networks, but can calibration also accelerate training by selecting the right samples? In this paper, we show that it can. We study the effect of popular calibration techniques in selecting better subsets of samples during training (also called sample prioritization) and observe that calibration can improve the quality of subsets, reduce the number of examples per epoch (by at least 70%), and can thereby speed up the overall training process. We further study the effect of using calibrated pre-trained models coupled with calibration during training to guide sample prioritization, which again seems to improve the quality of samples selected.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022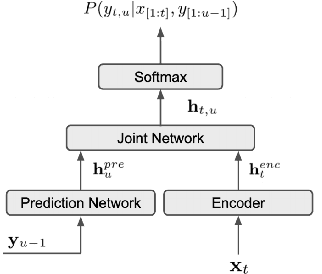
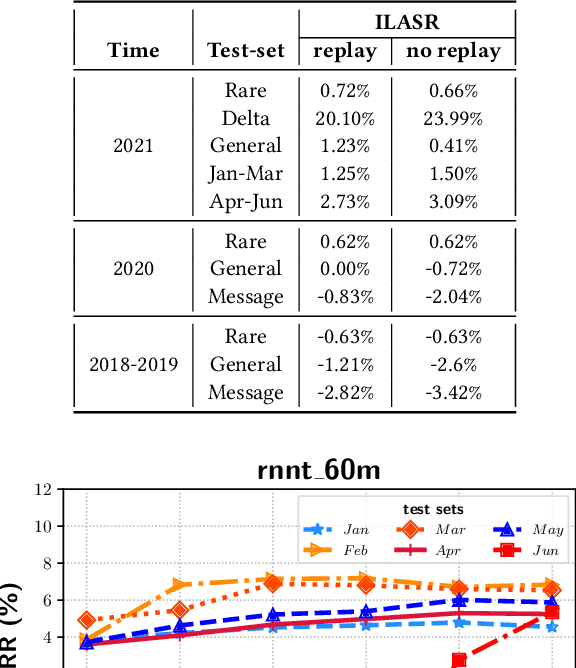
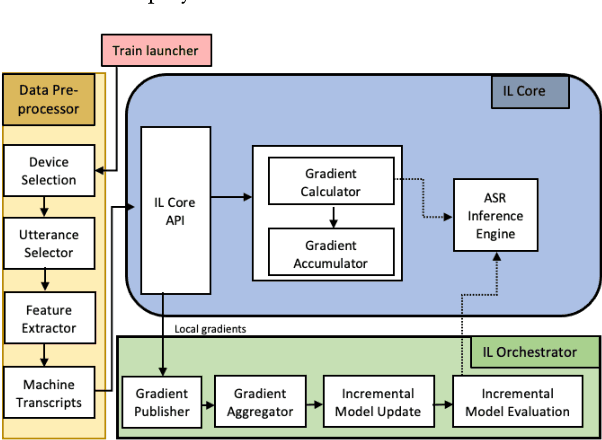
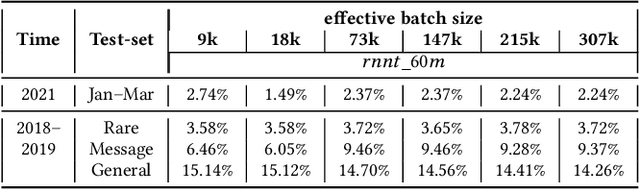
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
BB-ML: Basic Block Performance Prediction using Machine Learning Techniques
Feb 18, 2022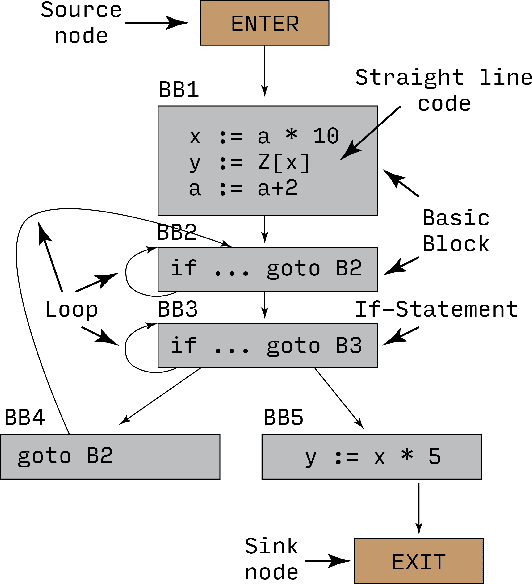
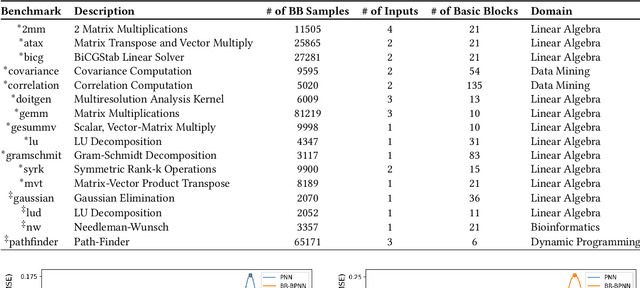
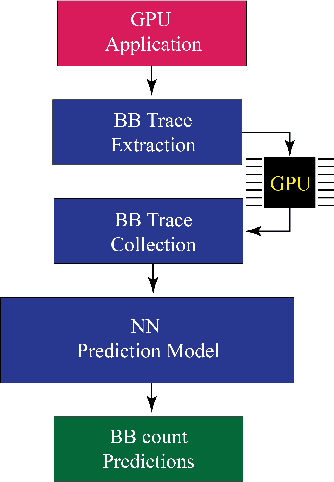
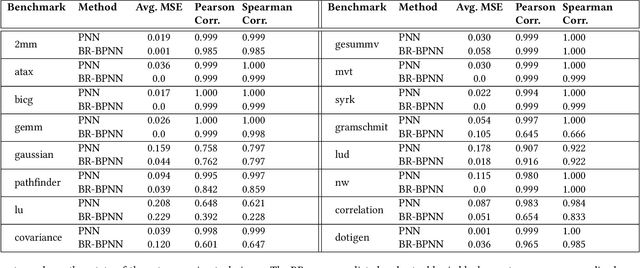
Recent years have seen the adoption of Machine Learning (ML) techniques to predict the performance of large-scale applications, mostly at a coarse level. In contrast, we propose to use ML techniques for performance prediction at much finer granularity, namely at the levels of Basic Block (BB), which are the single entry-single exit code blocks that are used as analysis tools by all compilers to break down a large code into manageable pieces. Utilizing ML and BB analysis together can enable scalable hardware-software co-design beyond the current state of the art. In this work, we extrapolate the basic block execution counts of GPU applications for large inputs sizes from the counts of smaller input sizes of the same application. We employ two ML models, a Poisson Neural Network (PNN) and a Bayesian Regularization Backpropagation Neural Network (BR-BPNN). We train both models using the lowest input values of the application and random input values to predict basic block counts. Results show that our models accurately predict the basic block execution counts of 16 benchmark applications. For PNN and BR-BPNN models, we achieve an average accuracy of 93.5% and 95.6%, respectively, while extrapolating the basic block counts for large input sets when the model is trained using smaller input sets. Additionally, the models show an average accuracy of 97.7% and 98.1%, respectively, while predicting basic block counts on random instances.
An Effective Baseline for Robustness to Distributional Shift
May 15, 2021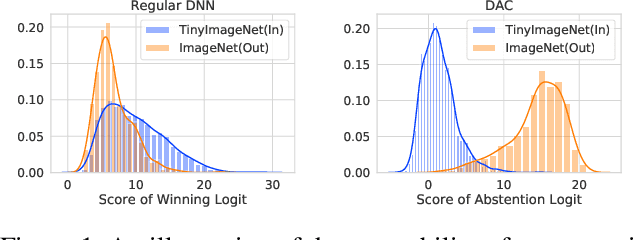
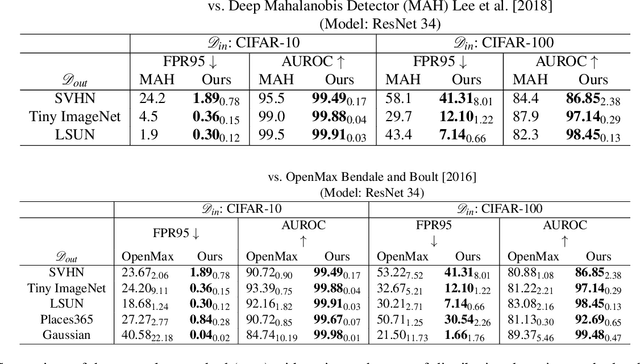
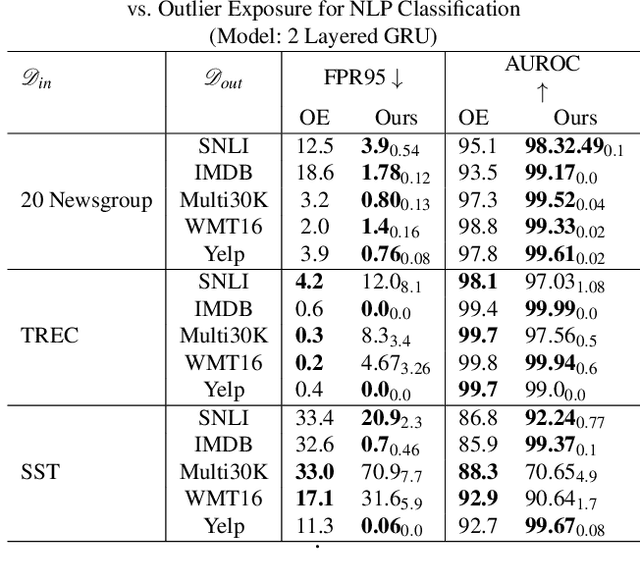
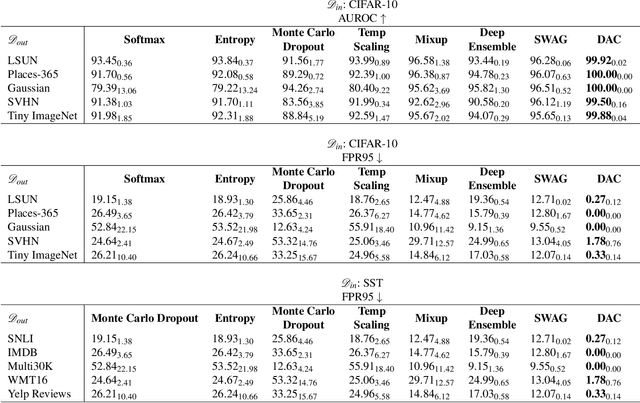
Refraining from confidently predicting when faced with categories of inputs different from those seen during training is an important requirement for the safe deployment of deep learning systems. While simple to state, this has been a particularly challenging problem in deep learning, where models often end up making overconfident predictions in such situations. In this work we present a simple, but highly effective approach to deal with out-of-distribution detection that uses the principle of abstention: when encountering a sample from an unseen class, the desired behavior is to abstain from predicting. Our approach uses a network with an extra abstention class and is trained on a dataset that is augmented with an uncurated set that consists of a large number of out-of-distribution (OoD) samples that are assigned the label of the abstention class; the model is then trained to learn an effective discriminator between in and out-of-distribution samples. We compare this relatively simple approach against a wide variety of more complex methods that have been proposed both for out-of-distribution detection as well as uncertainty modeling in deep learning, and empirically demonstrate its effectiveness on a wide variety of of benchmarks and deep architectures for image recognition and text classification, often outperforming existing approaches by significant margins. Given the simplicity and effectiveness of this method, we propose that this approach be used as a new additional baseline for future work in this domain.
Decoy Selection for Protein Structure Prediction Via Extreme Gradient Boosting and Ranking
Oct 03, 2020
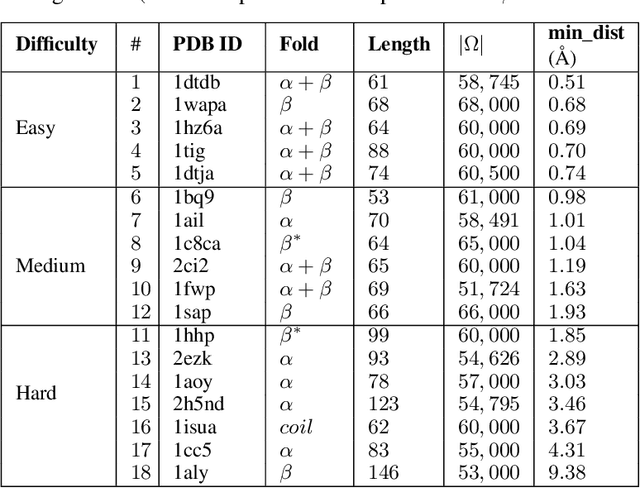
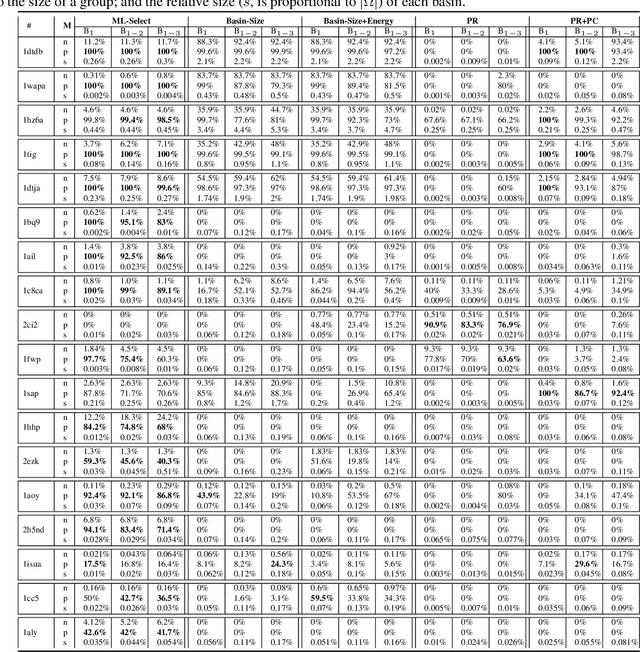
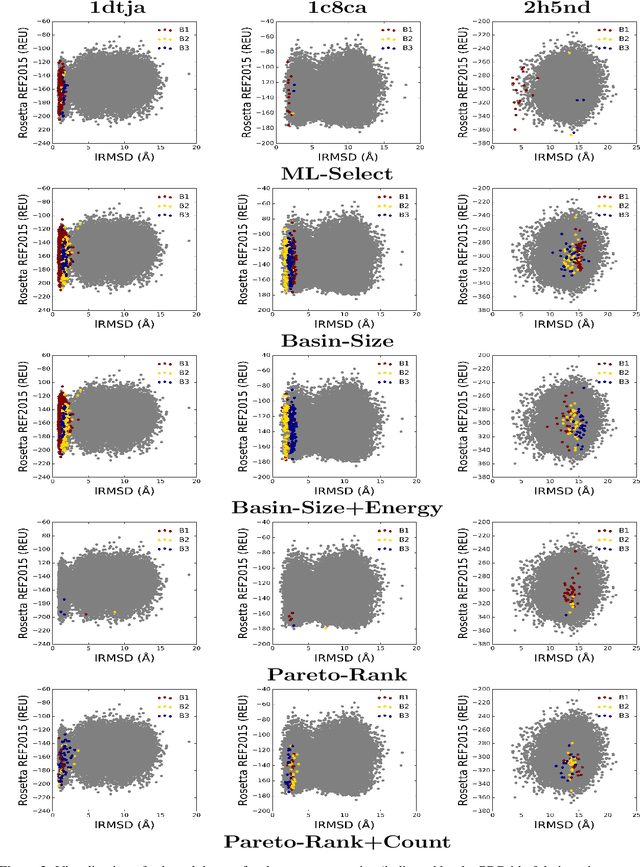
Identifying one or more biologically-active/native decoys from millions of non-native decoys is one of the major challenges in computational structural biology. The extreme lack of balance in positive and negative samples (native and non-native decoys) in a decoy set makes the problem even more complicated. Consensus methods show varied success in handling the challenge of decoy selection despite some issues associated with clustering large decoy sets and decoy sets that do not show much structural similarity. Recent investigations into energy landscape-based decoy selection approaches show promises. However, lack of generalization over varied test cases remains a bottleneck for these methods. We propose a novel decoy selection method, ML-Select, a machine learning framework that exploits the energy landscape associated with the structure space probed through a template-free decoy generation. The proposed method outperforms both clustering and energy ranking-based methods, all the while consistently offering better performance on varied test-cases. Moreover, ML-Select shows promising results even for the decoy sets consisting of mostly low-quality decoys. ML-Select is a useful method for decoy selection. This work suggests further research in finding more effective ways to adopt machine learning frameworks in achieving robust performance for decoy selection in template-free protein structure prediction.
Why I'm not Answering: Understanding Determinants of Classification of an Abstaining Classifier for Cancer Pathology Reports
Sep 24, 2020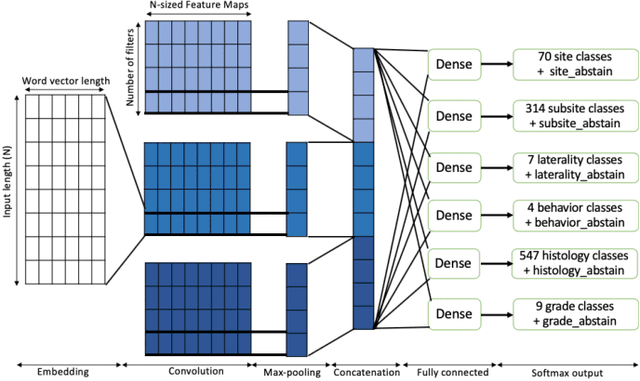

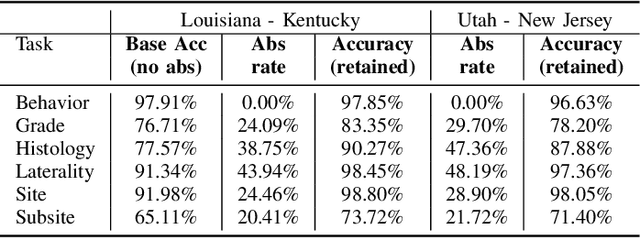
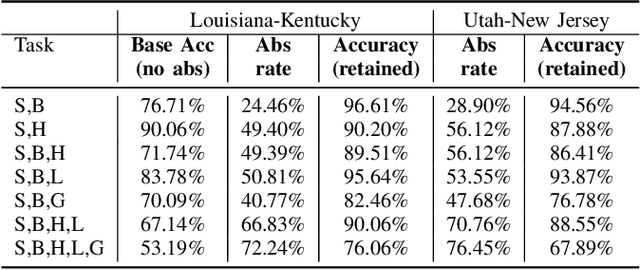
Safe deployment of deep learning systems in critical real world applications requires models to make few mistakes, and only under predictable circumstances. Development of such a model is not yet possible, in general. In this work, we address this problem with an abstaining classifier tuned to have $>$95% accuracy, and identify the determinants of abstention with LIME (the Local Interpretable Model-agnostic Explanations method). Essentially, we are training our model to learn the attributes of pathology reports that are likely to lead to incorrect classifications, albeit at the cost of reduced sensitivity. We demonstrate our method in a multitask setting to classify cancer pathology reports from the NCI SEER cancer registries on six tasks of greatest importance. For these tasks, we reduce the classification error rate by factors of 2-5 by abstaining on 25-45% of the reports. For the specific case of cancer site, we are able to identify metastasis and reports involving lymph nodes as responsible for many of the classification mistakes, and that the extent and types of mistakes vary systematically with cancer site (eg. breast, lung, and prostate). When combining across three of the tasks, our model classifies 50% of the reports with an accuracy greater than 95% for three of the six tasks and greater than 85% for all six tasks on the retained samples. By using this information, we expect to define work flows that incorporate machine learning only in the areas where it is sufficiently robust and accurate, saving human attention to areas where it is required.
Distributed Non-Negative Tensor Train Decomposition
Aug 04, 2020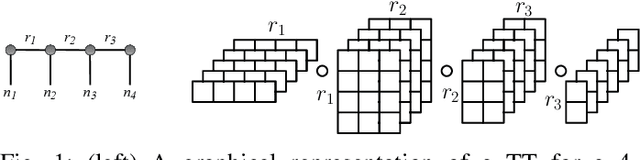
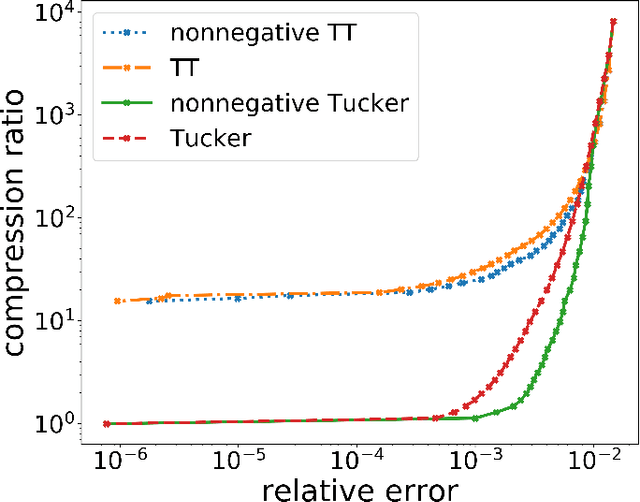
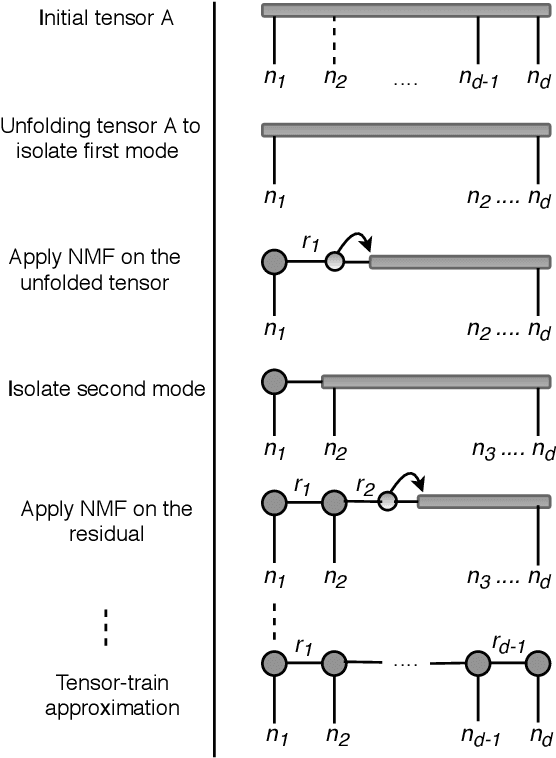
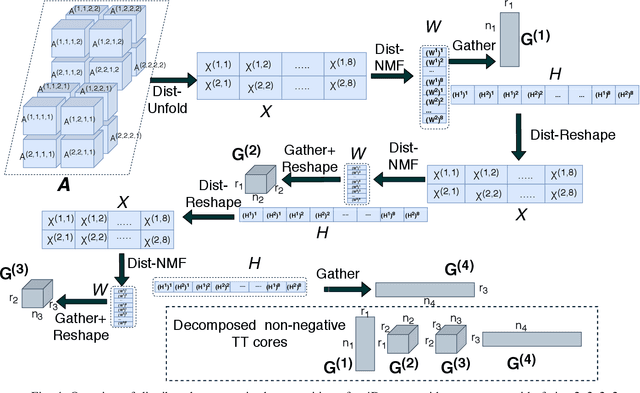
The era of exascale computing opens new venues for innovations and discoveries in many scientific, engineering, and commercial fields. However, with the exaflops also come the extra-large high-dimensional data generated by high-performance computing. High-dimensional data is presented as multidimensional arrays, aka tensors. The presence of latent (not directly observable) structures in the tensor allows a unique representation and compression of the data by classical tensor factorization techniques. However, the classical tensor methods are not always stable or they can be exponential in their memory requirements, which makes them not suitable for high-dimensional tensors. Tensor train (TT) is a state-of-the-art tensor network introduced for factorization of high-dimensional tensors. TT transforms the initial high-dimensional tensor in a network of three-dimensional tensors that requires only a linear storage. Many real-world data, such as, density, temperature, population, probability, etc., are non-negative and for an easy interpretation, the algorithms preserving non-negativity are preferred. Here, we introduce a distributed non-negative tensor-train and demonstrate its scalability and the compression on synthetic and real-world big datasets.