 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy I'm not Answering: Understanding Determinants of Classification of an Abstaining Classifier for Cancer Pathology Reports
Paper and Code
Sep 24, 2020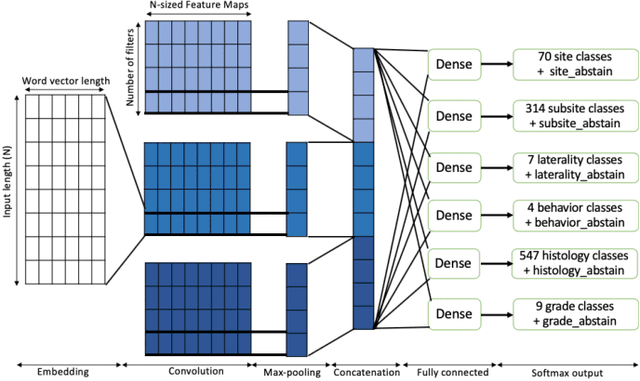

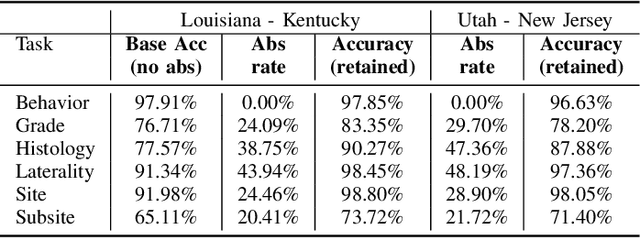
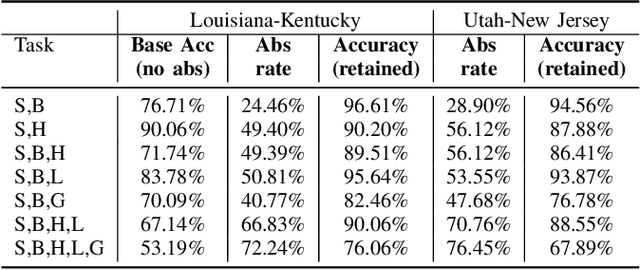
Safe deployment of deep learning systems in critical real world applications requires models to make few mistakes, and only under predictable circumstances. Development of such a model is not yet possible, in general. In this work, we address this problem with an abstaining classifier tuned to have $>$95% accuracy, and identify the determinants of abstention with LIME (the Local Interpretable Model-agnostic Explanations method). Essentially, we are training our model to learn the attributes of pathology reports that are likely to lead to incorrect classifications, albeit at the cost of reduced sensitivity. We demonstrate our method in a multitask setting to classify cancer pathology reports from the NCI SEER cancer registries on six tasks of greatest importance. For these tasks, we reduce the classification error rate by factors of 2-5 by abstaining on 25-45% of the reports. For the specific case of cancer site, we are able to identify metastasis and reports involving lymph nodes as responsible for many of the classification mistakes, and that the extent and types of mistakes vary systematically with cancer site (eg. breast, lung, and prostate). When combining across three of the tasks, our model classifies 50% of the reports with an accuracy greater than 95% for three of the six tasks and greater than 85% for all six tasks on the retained samples. By using this information, we expect to define work flows that incorporate machine learning only in the areas where it is sufficiently robust and accurate, saving human attention to areas where it is required.