 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Self-Supervised Multimodal Representation Learning and Foundation Models
Nov 29, 2022
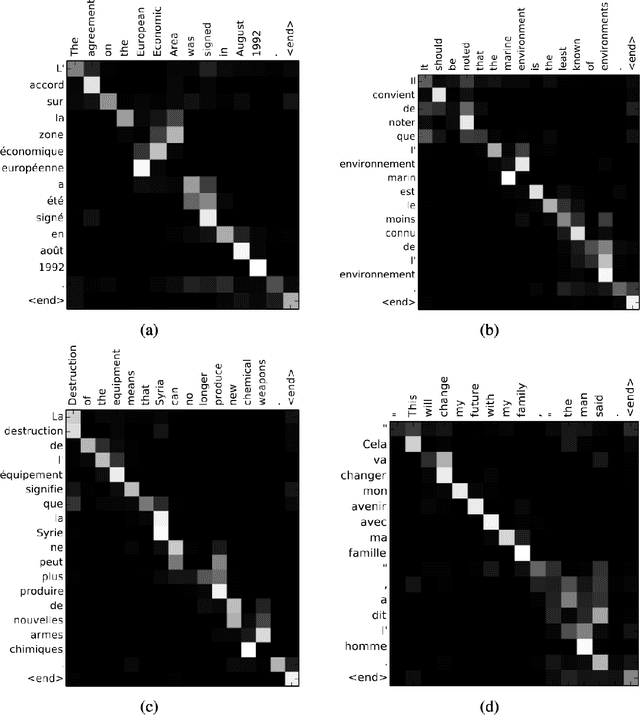
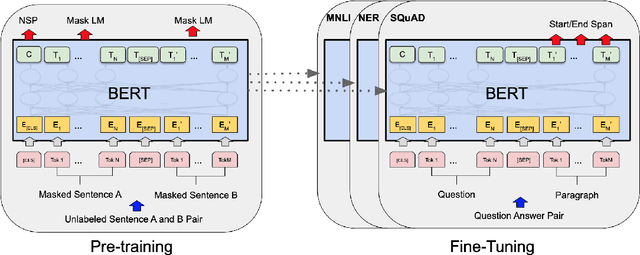
Deep learning has been the subject of growing interest in recent years. Specifically, a specific type called Multimodal learning has shown great promise for solving a wide range of problems in domains such as language, vision, audio, etc. One promising research direction to improve this further has been learning rich and robust low-dimensional data representation of the high-dimensional world with the help of large-scale datasets present on the internet. Because of its potential to avoid the cost of annotating large-scale datasets, self-supervised learning has been the de facto standard for this task in recent years. This paper summarizes some of the landmark research papers that are directly or indirectly responsible to build the foundation of multimodal self-supervised learning of representation today. The paper goes over the development of representation learning over the last few years for each modality and how they were combined to get a multimodal agent later.
On effects of Knowledge Distillation on Transfer Learning
Oct 18, 2022

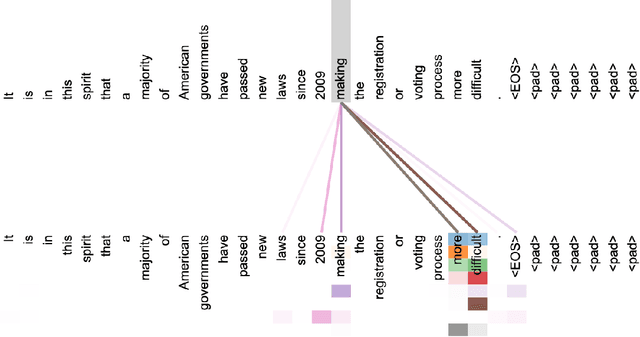
Knowledge distillation is a popular machine learning technique that aims to transfer knowledge from a large 'teacher' network to a smaller 'student' network and improve the student's performance by training it to emulate the teacher. In recent years, there has been significant progress in novel distillation techniques that push performance frontiers across multiple problems and benchmarks. Most of the reported work focuses on achieving state-of-the-art results on the specific problem. However, there has been a significant gap in understanding the process and how it behaves under certain training scenarios. Similarly, transfer learning (TL) is an effective technique in training neural networks on a limited dataset faster by reusing representations learned from a different but related problem. Despite its effectiveness and popularity, there has not been much exploration of knowledge distillation on transfer learning. In this thesis, we propose a machine learning architecture we call TL+KD that combines knowledge distillation with transfer learning; we then present a quantitative and qualitative comparison of TL+KD with TL in the domain of image classification. Through this work, we show that using guidance and knowledge from a larger teacher network during fine-tuning, we can improve the student network to achieve better validation performances like accuracy. We characterize the improvement in the validation performance of the model using a variety of metrics beyond just accuracy scores, and study its performance in scenarios such as input degradation.
An Effective Baseline for Robustness to Distributional Shift
May 15, 2021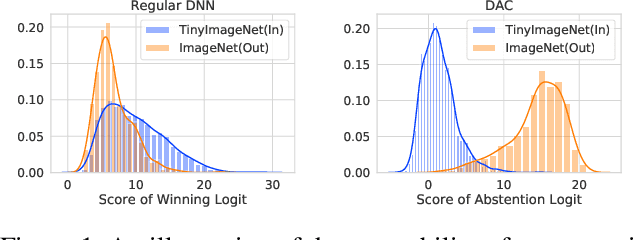
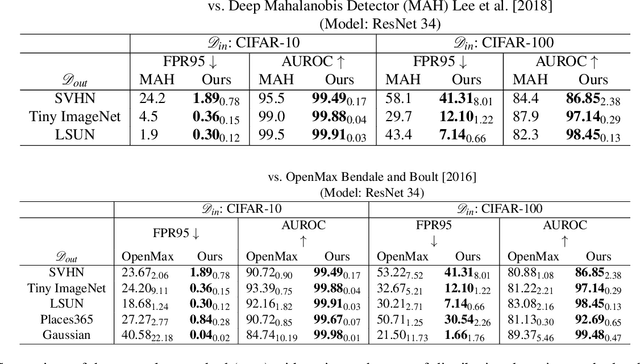
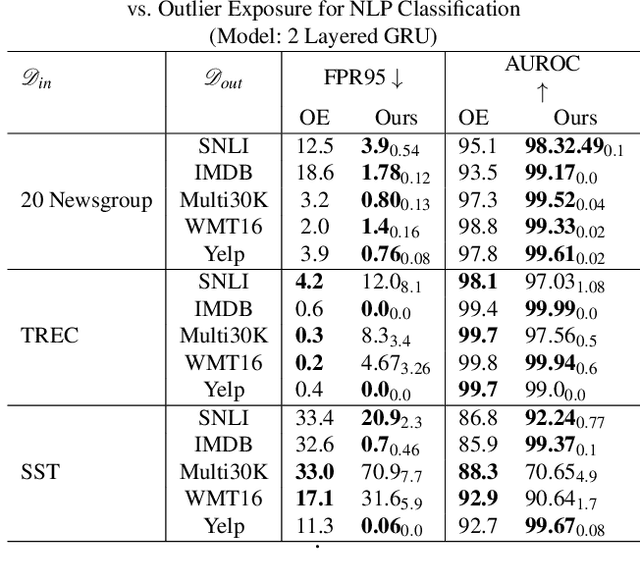
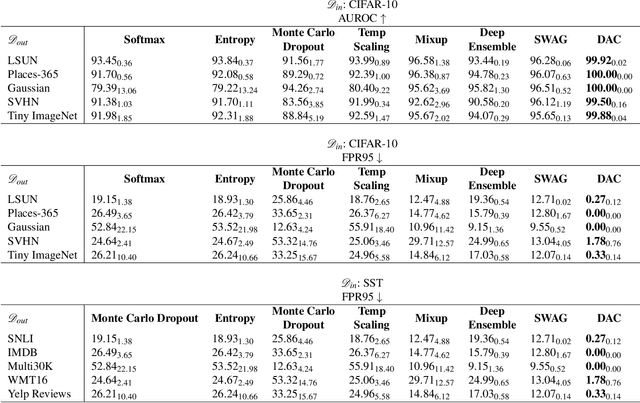
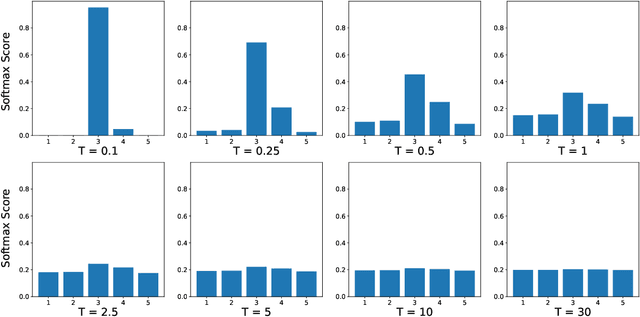
Refraining from confidently predicting when faced with categories of inputs different from those seen during training is an important requirement for the safe deployment of deep learning systems. While simple to state, this has been a particularly challenging problem in deep learning, where models often end up making overconfident predictions in such situations. In this work we present a simple, but highly effective approach to deal with out-of-distribution detection that uses the principle of abstention: when encountering a sample from an unseen class, the desired behavior is to abstain from predicting. Our approach uses a network with an extra abstention class and is trained on a dataset that is augmented with an uncurated set that consists of a large number of out-of-distribution (OoD) samples that are assigned the label of the abstention class; the model is then trained to learn an effective discriminator between in and out-of-distribution samples. We compare this relatively simple approach against a wide variety of more complex methods that have been proposed both for out-of-distribution detection as well as uncertainty modeling in deep learning, and empirically demonstrate its effectiveness on a wide variety of of benchmarks and deep architectures for image recognition and text classification, often outperforming existing approaches by significant margins. Given the simplicity and effectiveness of this method, we propose that this approach be used as a new additional baseline for future work in this domain.