 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn effects of Knowledge Distillation on Transfer Learning
Paper and Code

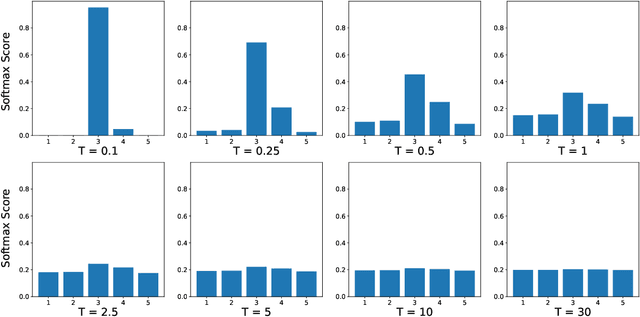

Knowledge distillation is a popular machine learning technique that aims to transfer knowledge from a large 'teacher' network to a smaller 'student' network and improve the student's performance by training it to emulate the teacher. In recent years, there has been significant progress in novel distillation techniques that push performance frontiers across multiple problems and benchmarks. Most of the reported work focuses on achieving state-of-the-art results on the specific problem. However, there has been a significant gap in understanding the process and how it behaves under certain training scenarios. Similarly, transfer learning (TL) is an effective technique in training neural networks on a limited dataset faster by reusing representations learned from a different but related problem. Despite its effectiveness and popularity, there has not been much exploration of knowledge distillation on transfer learning. In this thesis, we propose a machine learning architecture we call TL+KD that combines knowledge distillation with transfer learning; we then present a quantitative and qualitative comparison of TL+KD with TL in the domain of image classification. Through this work, we show that using guidance and knowledge from a larger teacher network during fine-tuning, we can improve the student network to achieve better validation performances like accuracy. We characterize the improvement in the validation performance of the model using a variety of metrics beyond just accuracy scores, and study its performance in scenarios such as input degradation.