 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Self-Supervised Multimodal Representation Learning and Foundation Models
Paper and Code
Nov 29, 2022
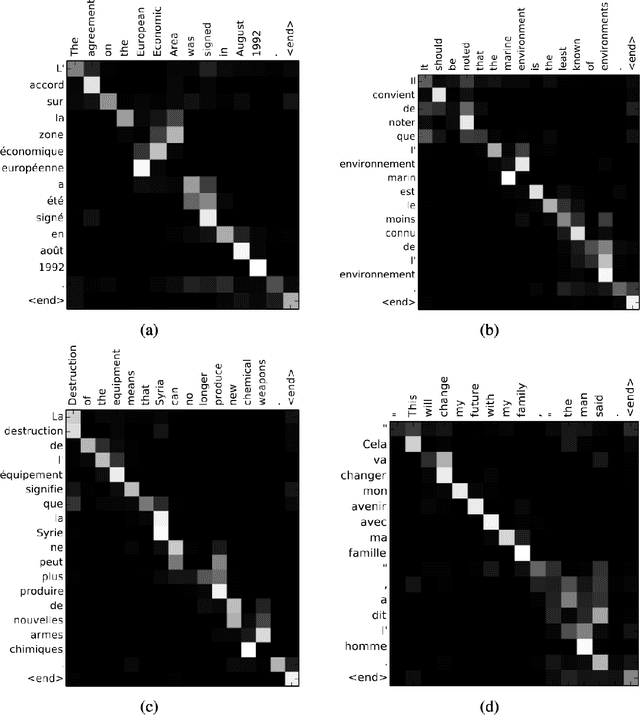
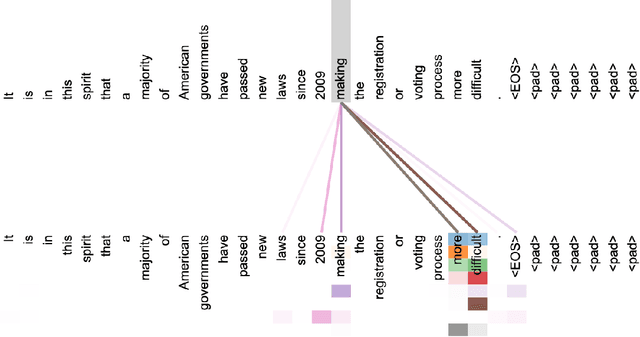
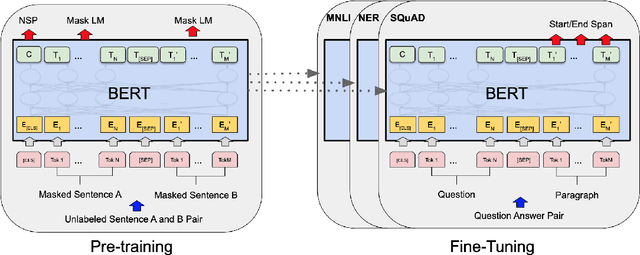
Deep learning has been the subject of growing interest in recent years. Specifically, a specific type called Multimodal learning has shown great promise for solving a wide range of problems in domains such as language, vision, audio, etc. One promising research direction to improve this further has been learning rich and robust low-dimensional data representation of the high-dimensional world with the help of large-scale datasets present on the internet. Because of its potential to avoid the cost of annotating large-scale datasets, self-supervised learning has been the de facto standard for this task in recent years. This paper summarizes some of the landmark research papers that are directly or indirectly responsible to build the foundation of multimodal self-supervised learning of representation today. The paper goes over the development of representation learning over the last few years for each modality and how they were combined to get a multimodal agent later.