 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022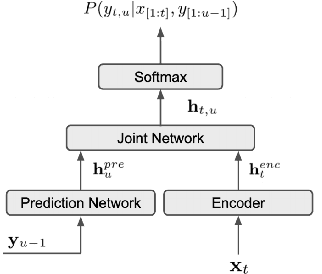
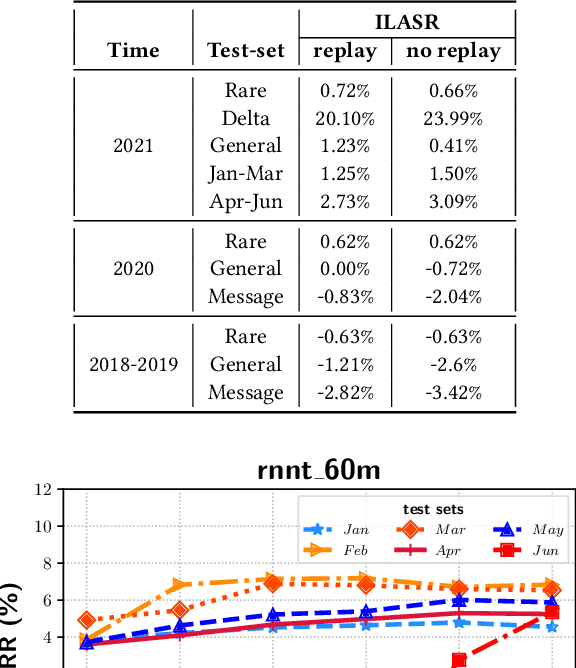
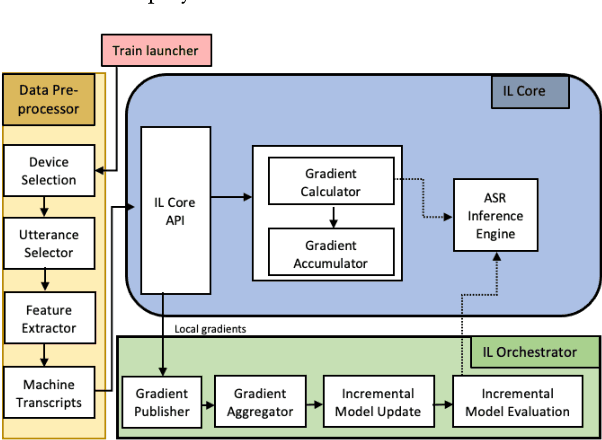
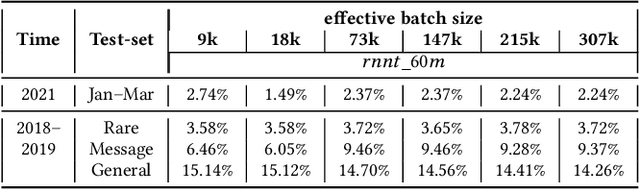
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.