 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025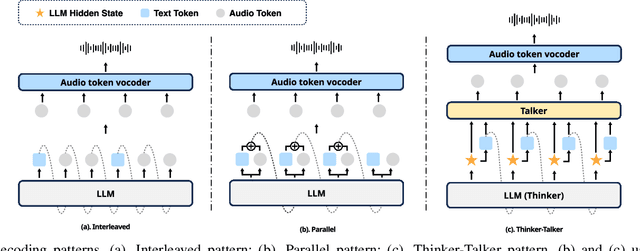
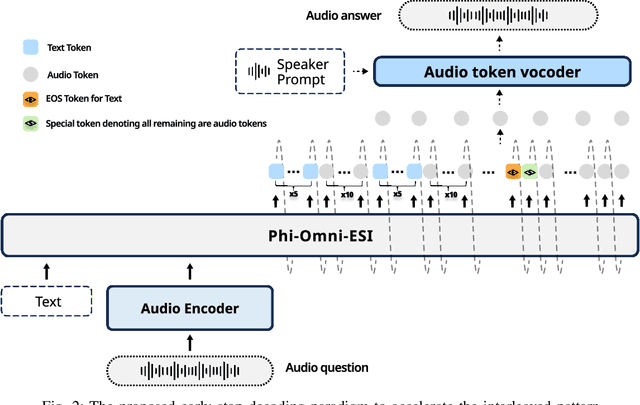


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Deploying self-supervised learning in the wild for hybrid automatic speech recognition
May 17, 2022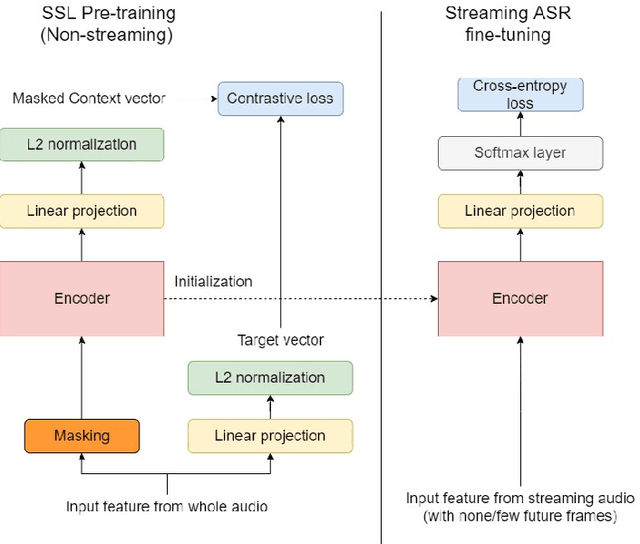
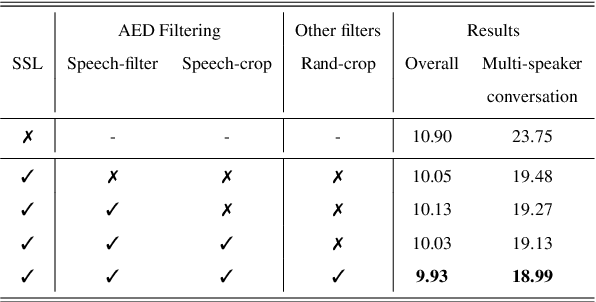
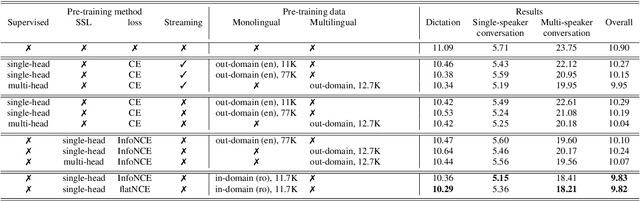
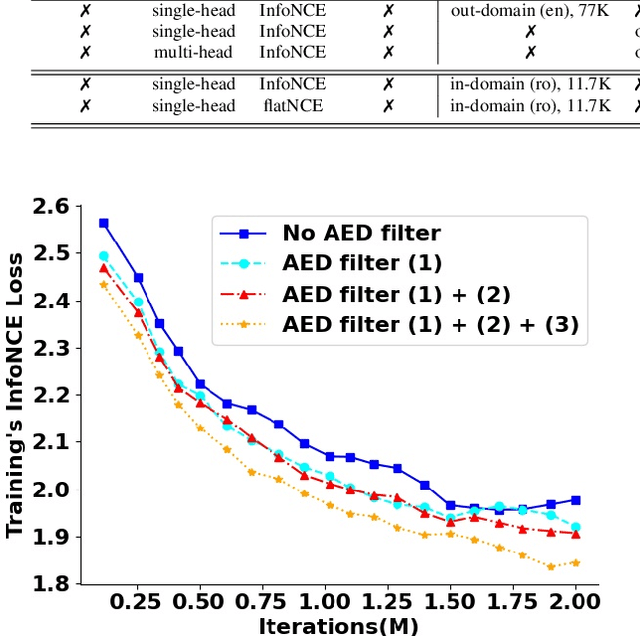
Self-supervised learning (SSL) methods have proven to be very successful in automatic speech recognition (ASR). These great improvements have been reported mostly based on highly curated datasets such as LibriSpeech for non-streaming End-to-End ASR models. However, the pivotal characteristics of SSL is to be utilized for any untranscribed audio data. In this paper, we provide a full exploration on how to utilize uncurated audio data in SSL from data pre-processing to deploying an streaming hybrid ASR model. More specifically, we present (1) the effect of Audio Event Detection (AED) model in data pre-processing pipeline (2) analysis on choosing optimizer and learning rate scheduling (3) comparison of recently developed contrastive losses, (4) comparison of various pre-training strategies such as utilization of in-domain versus out-domain pre-training data, monolingual versus multilingual pre-training data, multi-head multilingual SSL versus single-head multilingual SSL and supervised pre-training versus SSL. The experimental results show that SSL pre-training with in-domain uncurated data can achieve better performance in comparison to all the alternative out-domain pre-training strategies.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022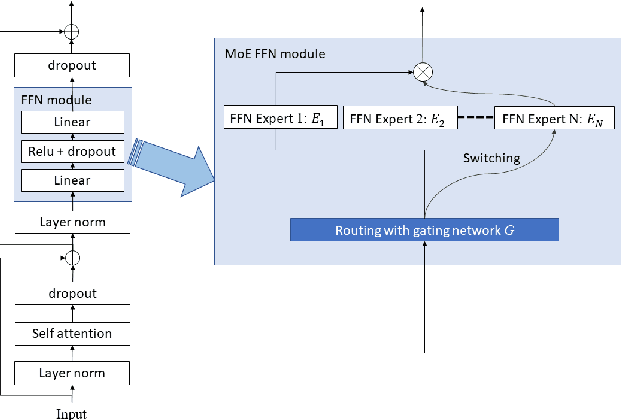
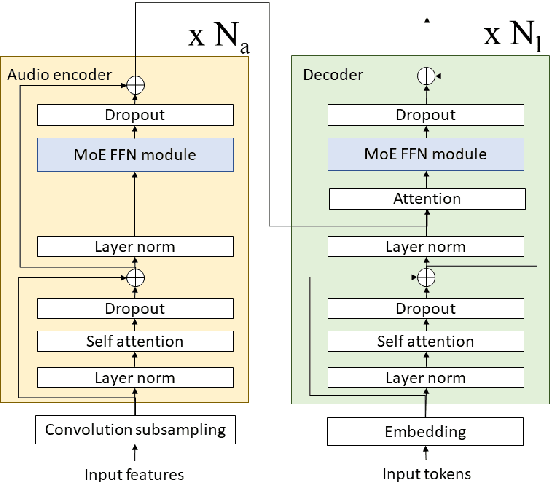
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021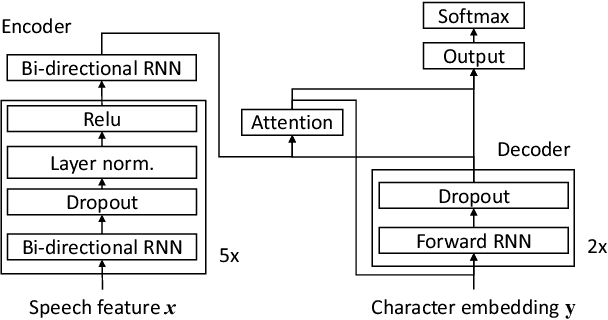
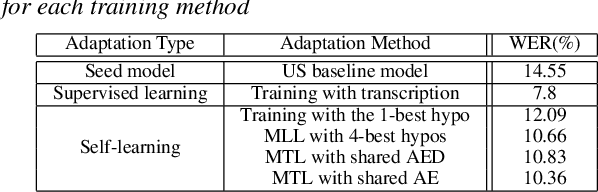
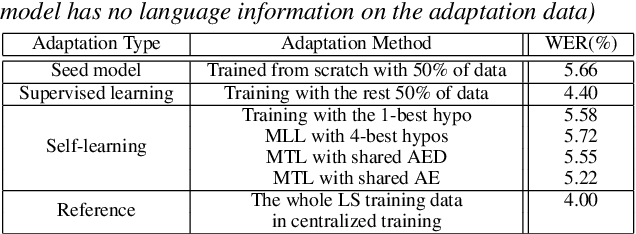
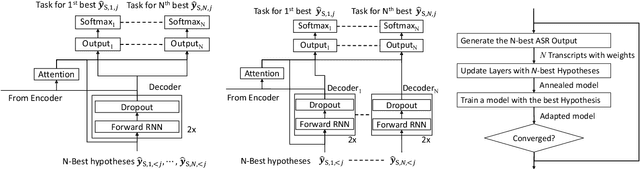
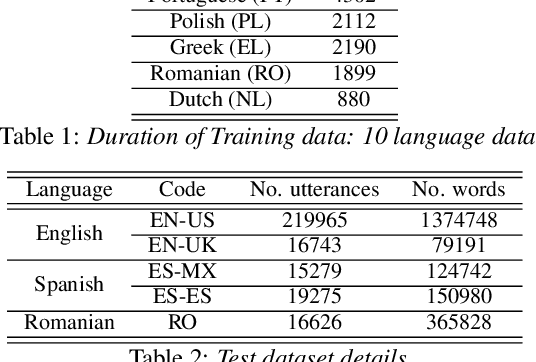
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
Tackling Dynamics in Federated Incremental Learning with Variational Embedding Rehearsal
Oct 19, 2021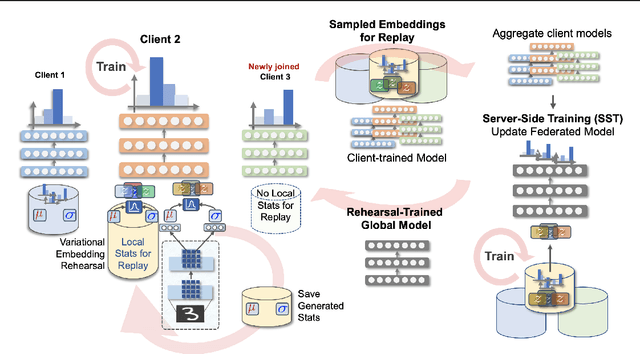
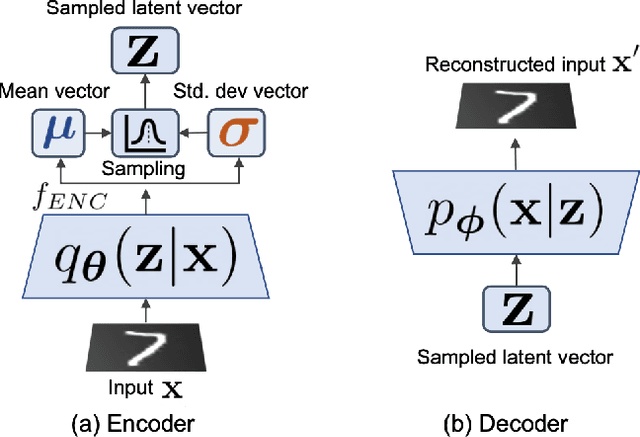
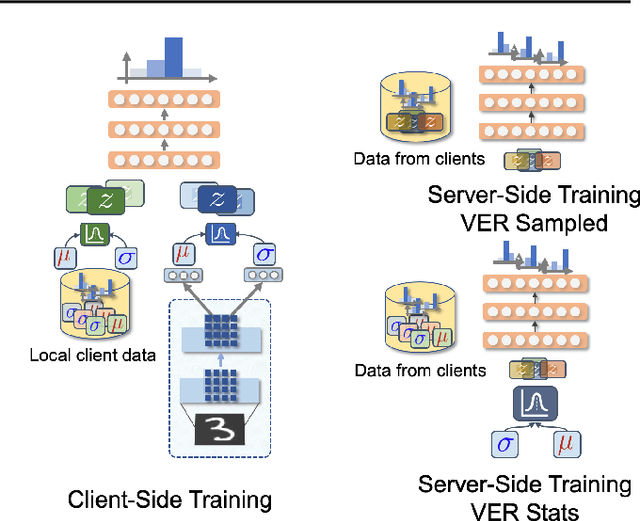
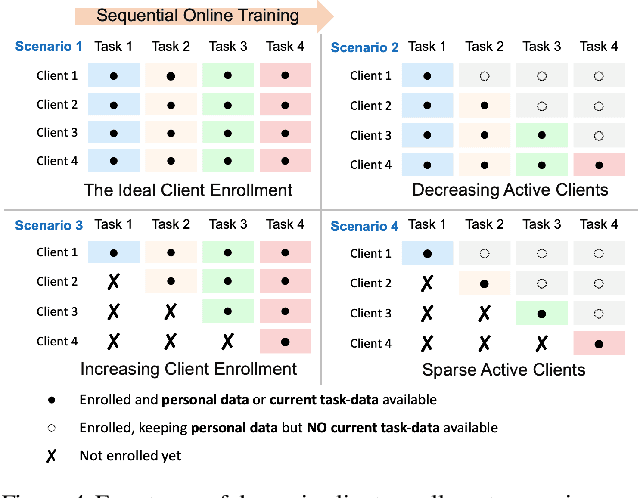
Federated Learning is a fast growing area of ML where the training datasets are extremely distributed, all while dynamically changing over time. Models need to be trained on clients' devices without any guarantees for either homogeneity or stationarity of the local private data. The need for continual training has also risen, due to the ever-increasing production of in-task data. However, pursuing both directions at the same time is challenging, since client data privacy is a major constraint, especially for rehearsal methods. Herein, we propose a novel algorithm to address the incremental learning process in an FL scenario, based on realistic client enrollment scenarios where clients can drop in or out dynamically. We first propose using deep Variational Embeddings that secure the privacy of the client data. Second, we propose a server-side training method that enables a model to rehearse the previously learnt knowledge. Finally, we investigate the performance of federated incremental learning in dynamic client enrollment scenarios. The proposed method shows parity with offline training on domain-incremental learning, addressing challenges in both the dynamic enrollment of clients and the domain shifting of client data.
Multilingual Speech Recognition using Knowledge Transfer across Learning Processes
Oct 15, 2021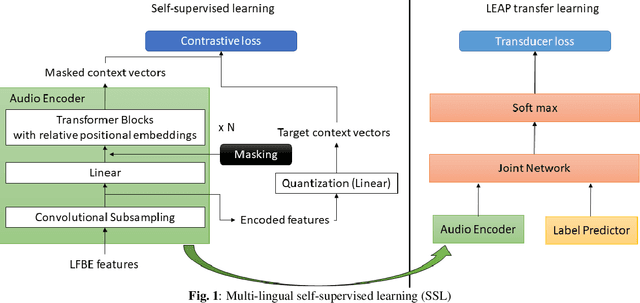
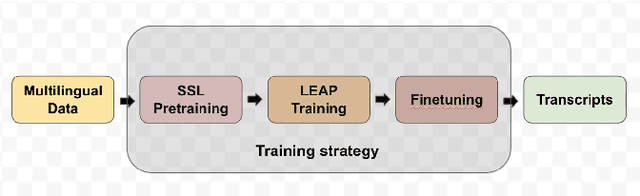
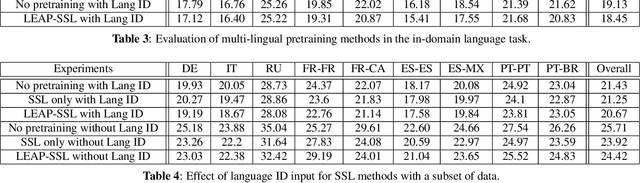
Multilingual end-to-end(E2E) models have shown a great potential in the expansion of the language coverage in the realm of automatic speech recognition(ASR). In this paper, we aim to enhance the multilingual ASR performance in two ways, 1)studying the impact of feeding a one-hot vector identifying the language, 2)formulating the task with a meta-learning objective combined with self-supervised learning (SSL). We associate every language with a distinct task manifold and attempt to improve the performance by transferring knowledge across learning processes itself as compared to transferring through final model parameters. We employ this strategy on a dataset comprising of 6 languages for an in-domain ASR task, by minimizing an objective related to expected gradient path length. Experimental results reveal the best pre-training strategy resulting in 3.55% relative reduction in overall WER. A combination of LEAP and SSL yields 3.51% relative reduction in overall WER when using language ID.
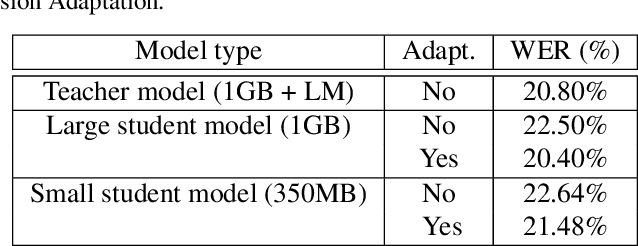
UniSpeech at scale: An Empirical Study of Pre-training Method on Large-Scale Speech Recognition Dataset
Jul 12, 2021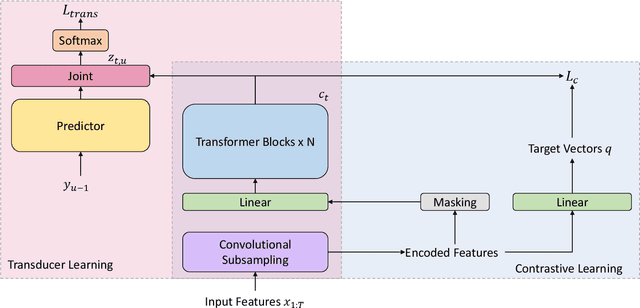
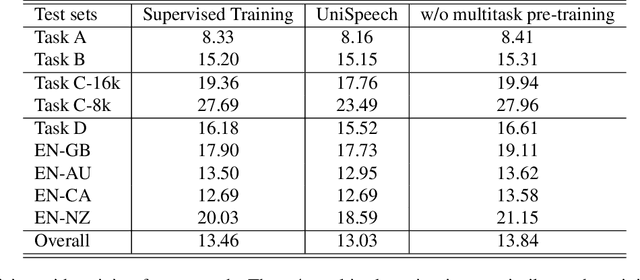
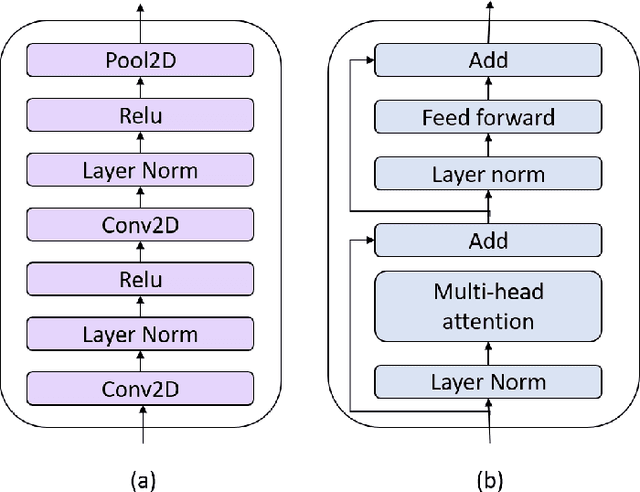
Recently, there has been a vast interest in self-supervised learning (SSL) where the model is pre-trained on large scale unlabeled data and then fine-tuned on a small labeled dataset. The common wisdom is that SSL helps resource-limited tasks in which only a limited amount of labeled data is available. The benefit of SSL keeps diminishing when the labeled training data amount increases. To our best knowledge, at most a few thousand hours of labeled data was used in the study of SSL. In contrast, the industry usually uses tens of thousands of hours of labeled data to build high-accuracy speech recognition (ASR) systems for resource-rich languages. In this study, we take the challenge to investigate whether and how SSL can improve the ASR accuracy of a state-of-the-art production-scale Transformer-Transducer model, which was built with 65 thousand hours of anonymized labeled EN-US data.
Dynamic Gradient Aggregation for Federated Domain Adaptation
Jun 14, 2021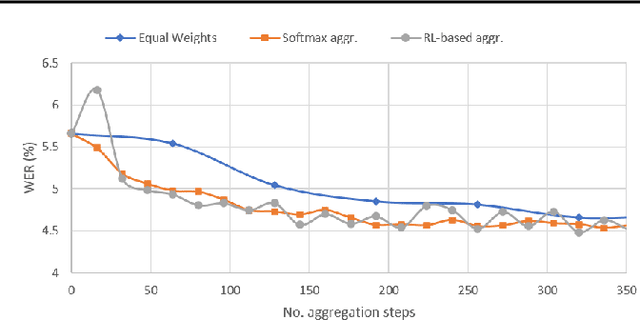
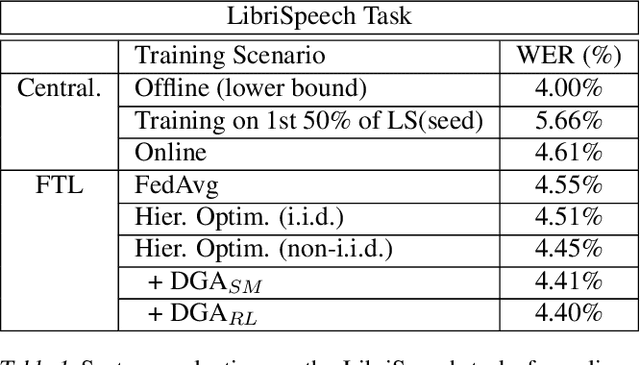
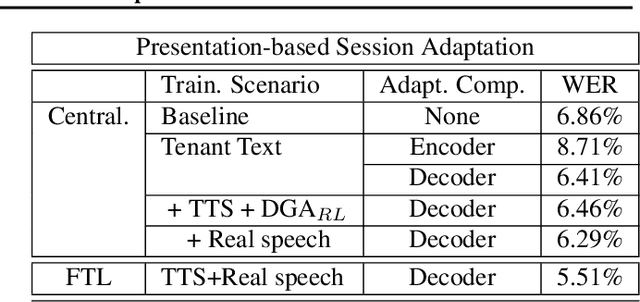
In this paper, a new learning algorithm for Federated Learning (FL) is introduced. The proposed scheme is based on a weighted gradient aggregation using two-step optimization to offer a flexible training pipeline. Herein, two different flavors of the aggregation method are presented, leading to an order of magnitude improvement in convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. Further, the aggregation algorithm acts as a regularizer of the gradient quality. We investigate the effect of our FL algorithm in supervised and unsupervised Speech Recognition (SR) scenarios. The experimental validation is performed based on three tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% word error rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing 20% WERR over a powerful LAS model. Finally, our unsupervised pipeline is applied to the conversational SR task. The proposed FL system outperforms the baseline systems in both convergence speed and overall model performance.
UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Jan 19, 2021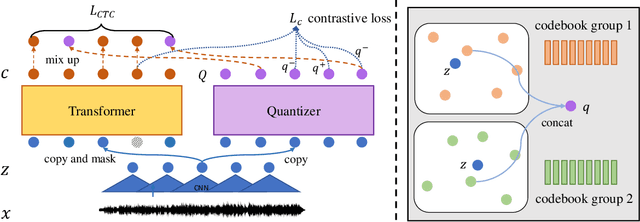
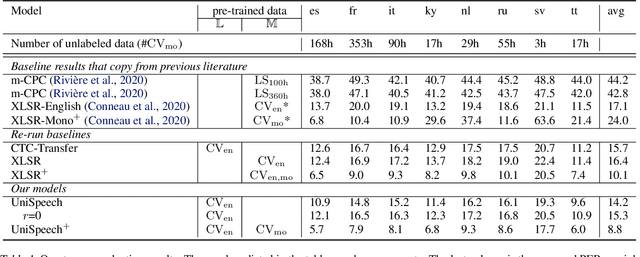

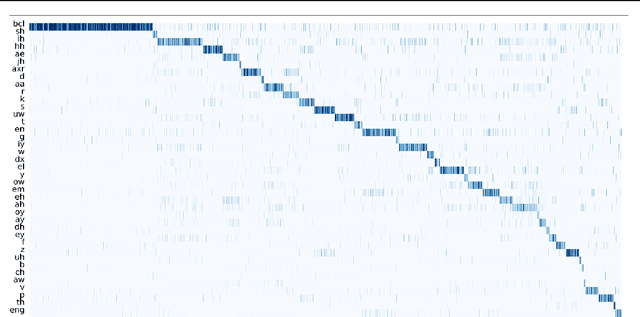
In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.
Federated Transfer Learning with Dynamic Gradient Aggregation
Aug 06, 2020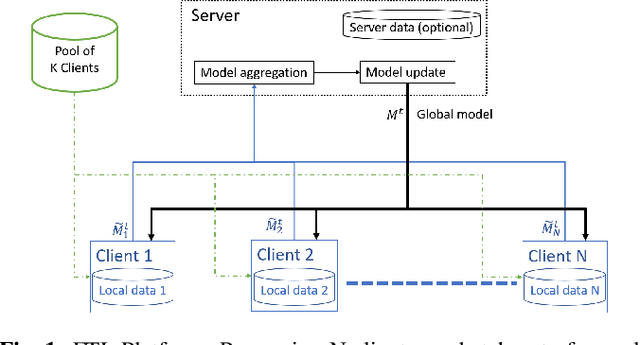
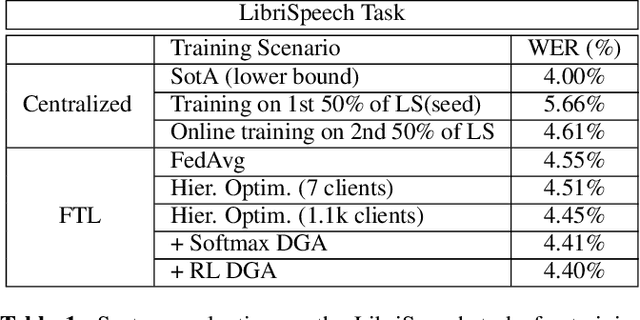
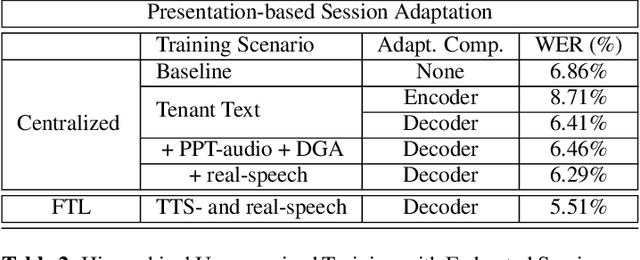
In this paper, a Federated Learning (FL) simulation platform is introduced. The target scenario is Acoustic Model training based on this platform. To our knowledge, this is the first attempt to apply FL techniques to Speech Recognition tasks due to the inherent complexity. The proposed FL platform can support different tasks based on the adopted modular design. As part of the platform, a novel hierarchical optimization scheme and two gradient aggregation methods are proposed, leading to almost an order of magnitude improvement in training convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. The hierarchical optimization offers additional flexibility in the training pipeline besides the enhanced convergence speed. On top of the hierarchical optimization, a dynamic gradient aggregation algorithm is proposed, based on a data-driven weight inference. This aggregation algorithm acts as a regularizer of the gradient quality. Finally, an unsupervised training pipeline tailored to FL is presented as a separate training scenario. The experimental validation of the proposed system is based on two tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% Word Error Rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing an improvement of 20% WERR over a competitive production-ready LAS model. The proposed Federated Learning system is shown to outperform the golden standard of distributed training in both convergence speed and overall model performance.