 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023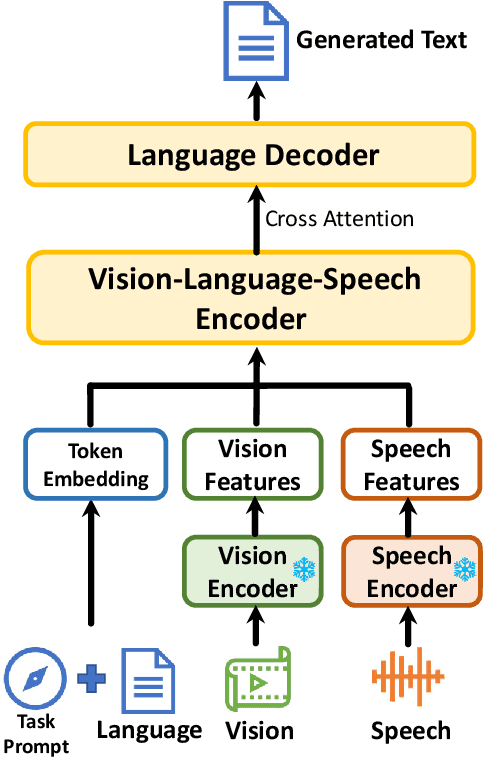
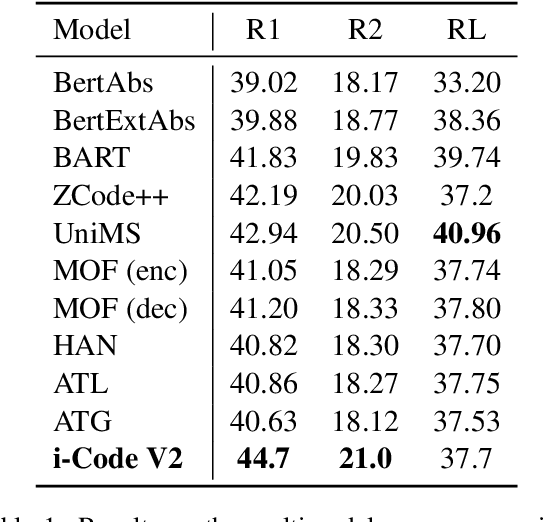
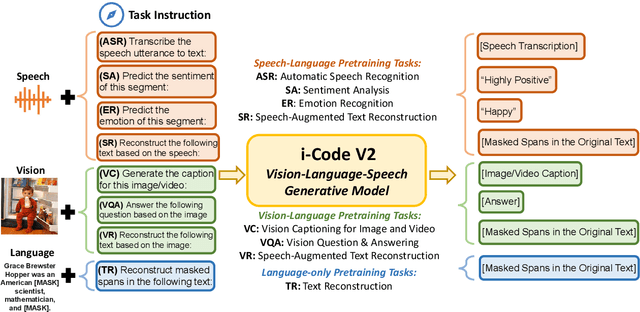

The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022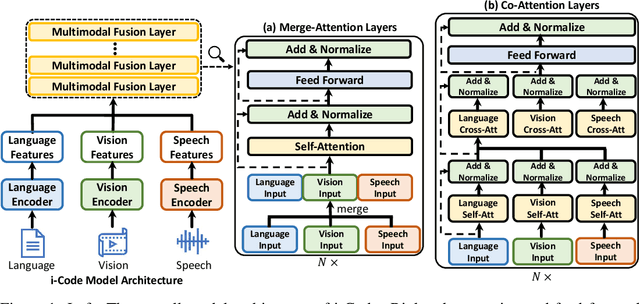
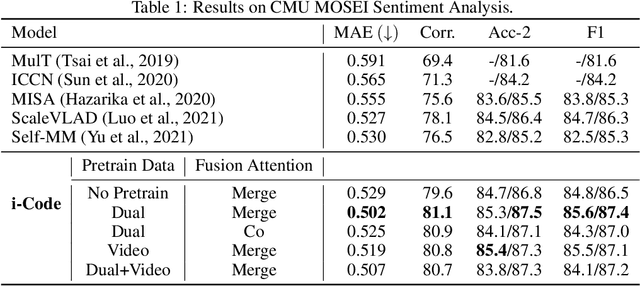
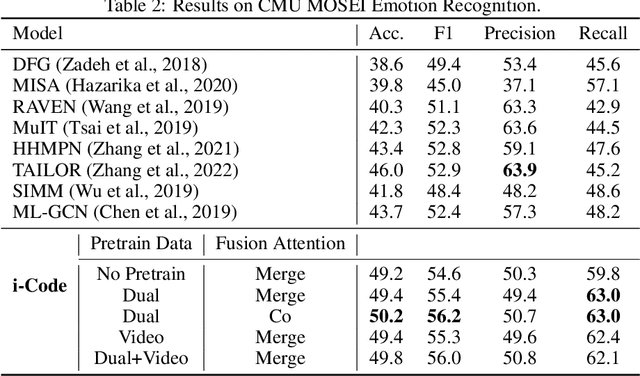

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
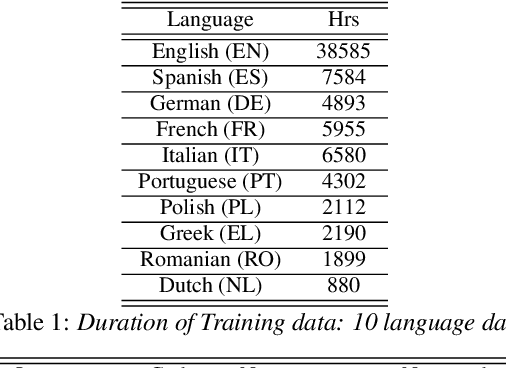
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022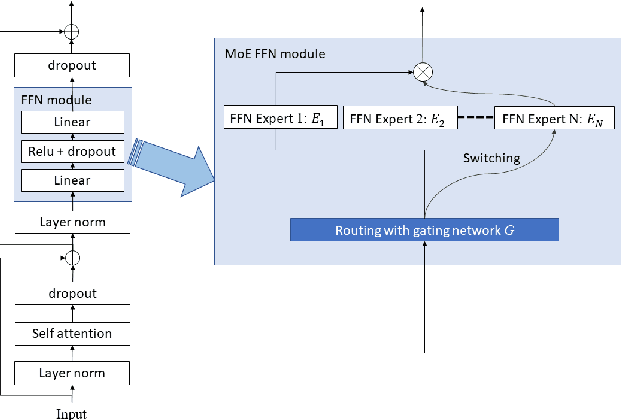
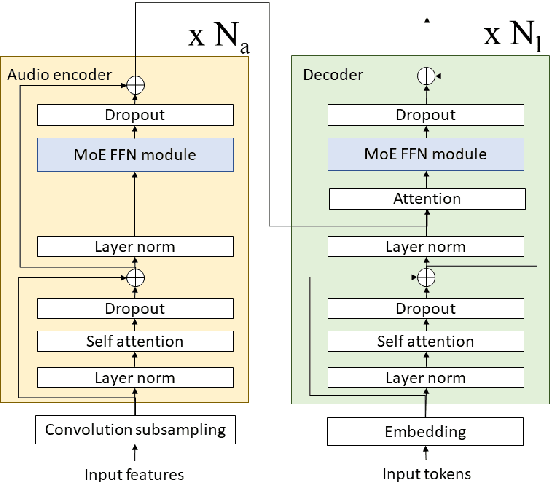
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021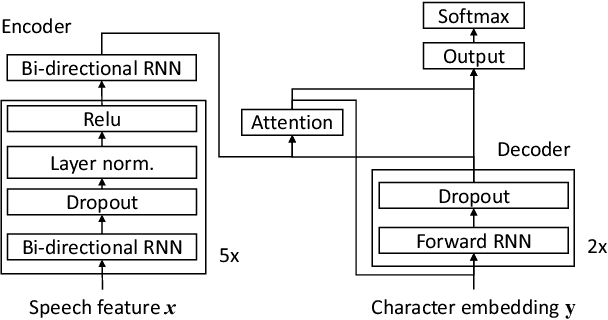
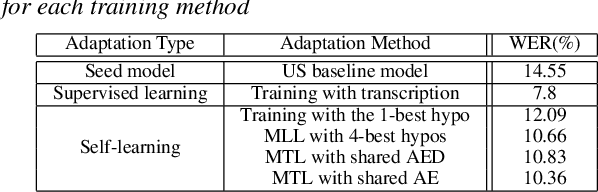
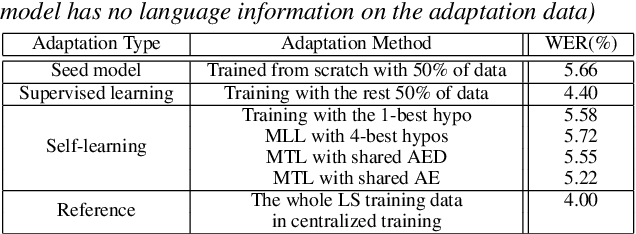
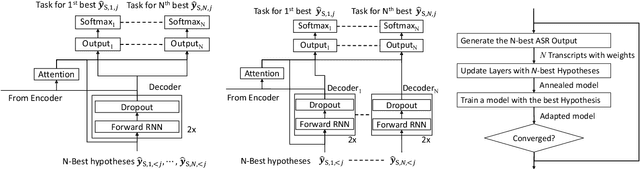
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
Dynamic Gradient Aggregation for Federated Domain Adaptation
Jun 14, 2021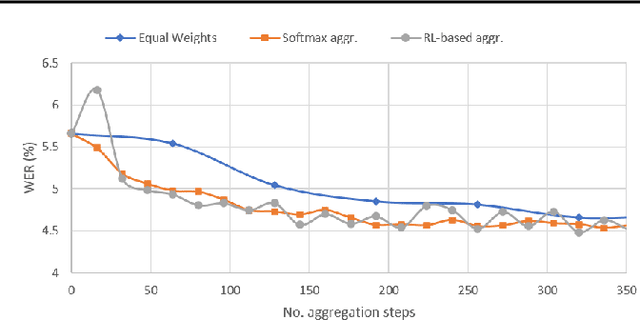
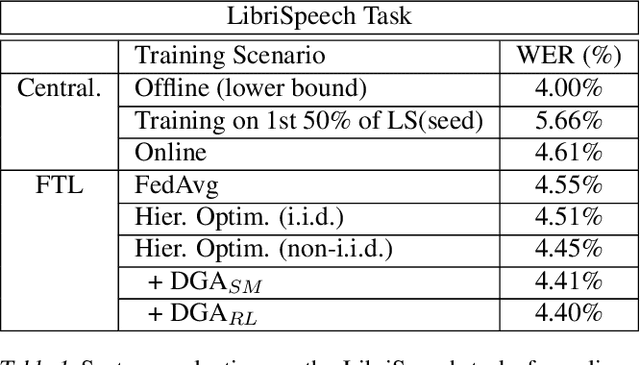
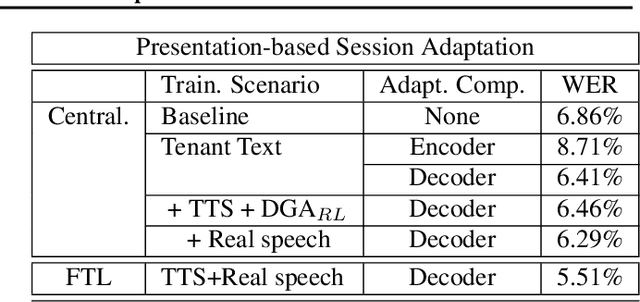
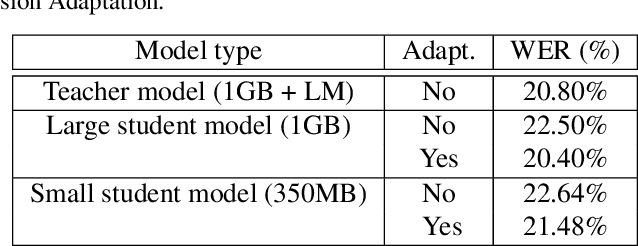
In this paper, a new learning algorithm for Federated Learning (FL) is introduced. The proposed scheme is based on a weighted gradient aggregation using two-step optimization to offer a flexible training pipeline. Herein, two different flavors of the aggregation method are presented, leading to an order of magnitude improvement in convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. Further, the aggregation algorithm acts as a regularizer of the gradient quality. We investigate the effect of our FL algorithm in supervised and unsupervised Speech Recognition (SR) scenarios. The experimental validation is performed based on three tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% word error rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing 20% WERR over a powerful LAS model. Finally, our unsupervised pipeline is applied to the conversational SR task. The proposed FL system outperforms the baseline systems in both convergence speed and overall model performance.
Federated Transfer Learning with Dynamic Gradient Aggregation
Aug 06, 2020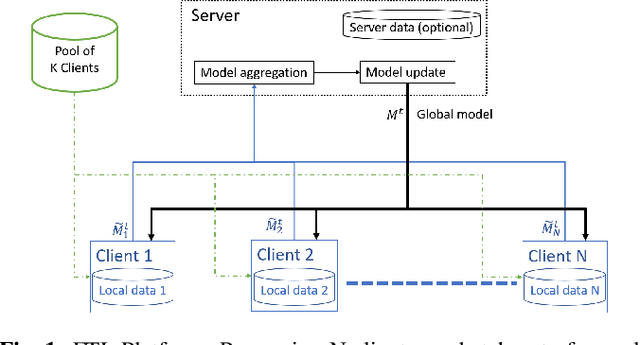
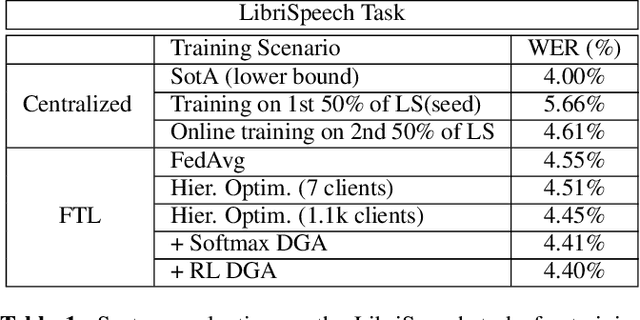
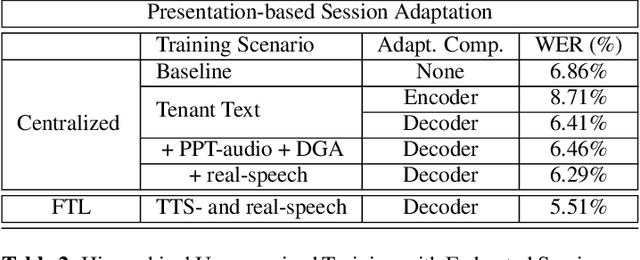
In this paper, a Federated Learning (FL) simulation platform is introduced. The target scenario is Acoustic Model training based on this platform. To our knowledge, this is the first attempt to apply FL techniques to Speech Recognition tasks due to the inherent complexity. The proposed FL platform can support different tasks based on the adopted modular design. As part of the platform, a novel hierarchical optimization scheme and two gradient aggregation methods are proposed, leading to almost an order of magnitude improvement in training convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. The hierarchical optimization offers additional flexibility in the training pipeline besides the enhanced convergence speed. On top of the hierarchical optimization, a dynamic gradient aggregation algorithm is proposed, based on a data-driven weight inference. This aggregation algorithm acts as a regularizer of the gradient quality. Finally, an unsupervised training pipeline tailored to FL is presented as a separate training scenario. The experimental validation of the proposed system is based on two tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% Word Error Rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing an improvement of 20% WERR over a competitive production-ready LAS model. The proposed Federated Learning system is shown to outperform the golden standard of distributed training in both convergence speed and overall model performance.
Make Lead Bias in Your Favor: A Simple and Effective Method for News Summarization
Jan 07, 2020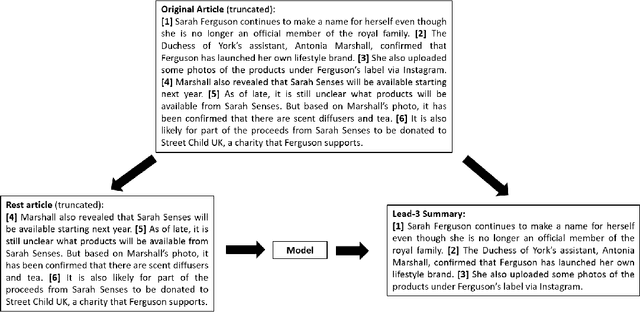
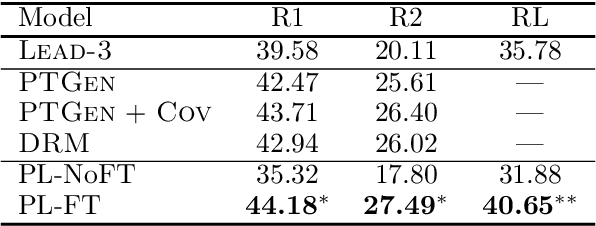
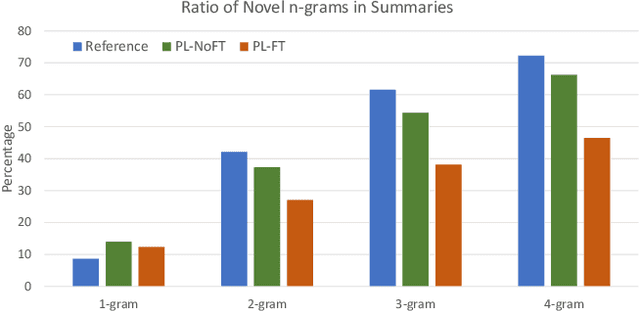
Lead bias is a common phenomenon in news summarization, where early parts of an article often contain the most salient information. While many algorithms exploit this fact in summary generation, it has a detrimental effect on teaching the model to discriminate and extract important information. We propose that the lead bias can be leveraged in a simple and effective way in our favor to pretrain abstractive news summarization models on large-scale unlabeled corpus: predicting the leading sentences using the rest of an article. Via careful data cleaning and filtering, our transformer-based pretrained model without any finetuning achieves remarkable results over various news summarization tasks. With further finetuning, our model outperforms many competitive baseline models. Human evaluations further show the effectiveness of our method.
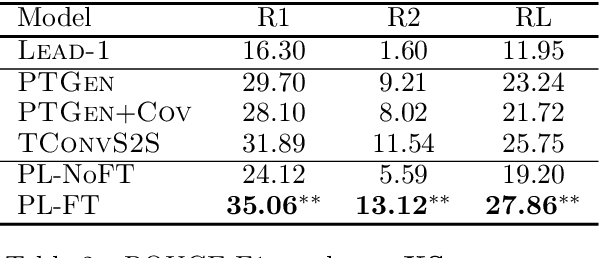
TED: A Pretrained Unsupervised Summarization Model with Theme Modeling and Denoising
Jan 06, 2020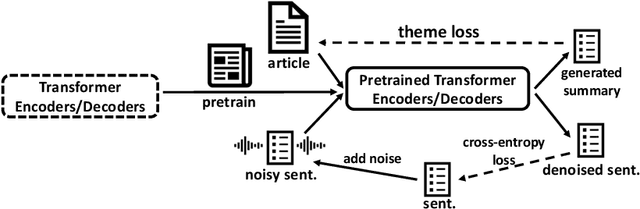
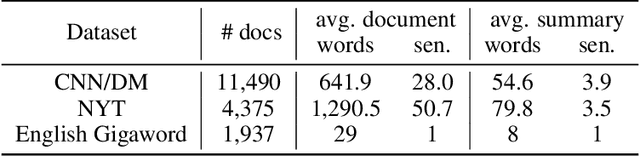
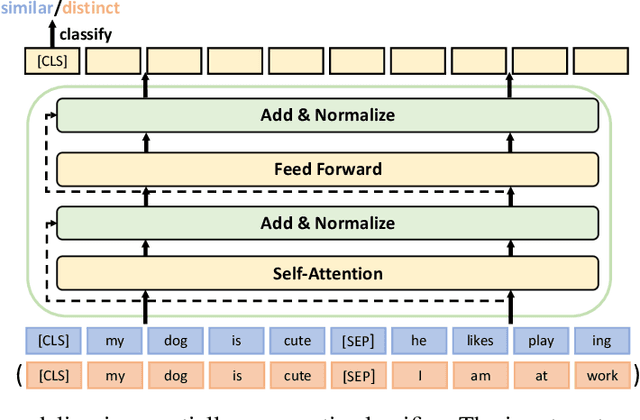
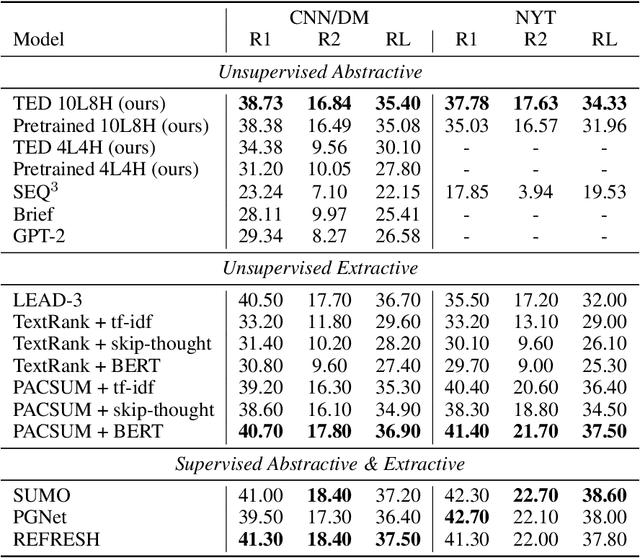
Text summarization aims to extract essential information from a piece of text and transform it into a concise version. Existing unsupervised abstractive summarization models use recurrent neural networks framework and ignore abundant unlabeled corpora resources. In order to address these issues, we propose TED, a transformer-based unsupervised summarization system with pretraining on large-scale data. We first leverage the lead bias in news articles to pretrain the model on large-scale corpora. Then, we finetune TED on target domains through theme modeling and a denoising autoencoder to enhance the quality of summaries. Notably, TED outperforms all unsupervised abstractive baselines on NYT, CNN/DM and English Gigaword datasets with various document styles. Further analysis shows that the summaries generated by TED are abstractive and containing even higher proportions of novel tokens than those from supervised models.