 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
Property-Aware Multi-Speaker Data Simulation: A Probabilistic Modelling Technique for Synthetic Data Generation
Oct 18, 2023



We introduce a sophisticated multi-speaker speech data simulator, specifically engineered to generate multi-speaker speech recordings. A notable feature of this simulator is its capacity to modulate the distribution of silence and overlap via the adjustment of statistical parameters. This capability offers a tailored training environment for developing neural models suited for speaker diarization and voice activity detection. The acquisition of substantial datasets for speaker diarization often presents a significant challenge, particularly in multi-speaker scenarios. Furthermore, the precise time stamp annotation of speech data is a critical factor for training both speaker diarization and voice activity detection. Our proposed multi-speaker simulator tackles these problems by generating large-scale audio mixtures that maintain statistical properties closely aligned with the input parameters. We demonstrate that the proposed multi-speaker simulator generates audio mixtures with statistical properties that closely align with the input parameters derived from real-world statistics. Additionally, we present the effectiveness of speaker diarization and voice activity detection models, which have been trained exclusively on the generated simulated datasets.
Enhancing Speaker Diarization with Large Language Models: A Contextual Beam Search Approach
Sep 14, 2023
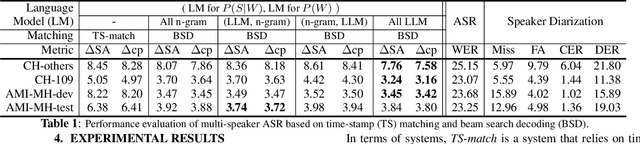

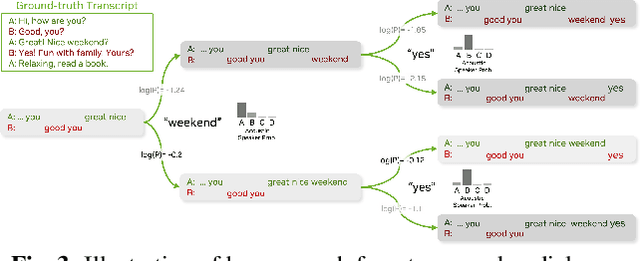
Large language models (LLMs) have shown great promise for capturing contextual information in natural language processing tasks. We propose a novel approach to speaker diarization that incorporates the prowess of LLMs to exploit contextual cues in human dialogues. Our method builds upon an acoustic-based speaker diarization system by adding lexical information from an LLM in the inference stage. We model the multi-modal decoding process probabilistically and perform joint acoustic and lexical beam search to incorporate cues from both modalities: audio and text. Our experiments demonstrate that infusing lexical knowledge from the LLM into an acoustics-only diarization system improves overall speaker-attributed word error rate (SA-WER). The experimental results show that LLMs can provide complementary information to acoustic models for the speaker diarization task via proposed beam search decoding approach showing up to 39.8% relative delta-SA-WER improvement from the baseline system. Thus, we substantiate that the proposed technique is able to exploit contextual information that is inaccessible to acoustics-only systems which is represented by speaker embeddings. In addition, these findings point to the potential of using LLMs to improve speaker diarization and other speech processing tasks by capturing semantic and contextual cues.
Multi-scale Speaker Diarization with Dynamic Scale Weighting
Mar 30, 2022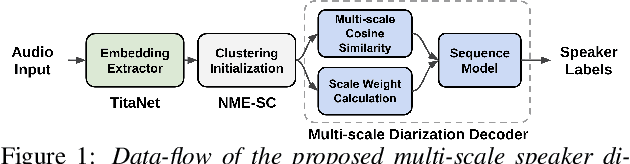

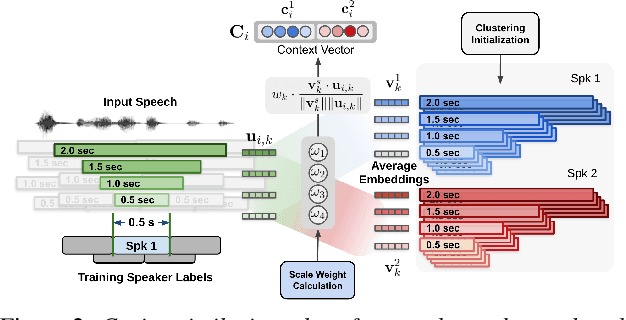
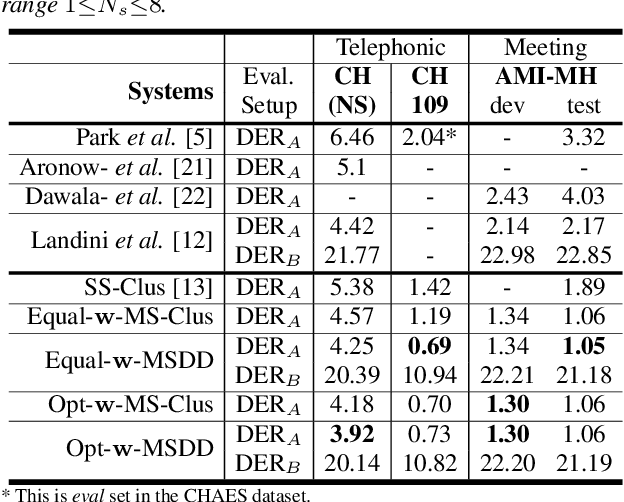
Speaker diarization systems are challenged by a trade-off between the temporal resolution and the fidelity of the speaker representation. By obtaining a superior temporal resolution with an enhanced accuracy, a multi-scale approach is a way to cope with such a trade-off. In this paper, we propose a more advanced multi-scale diarization system based on a multi-scale diarization decoder. There are two main contributions in this study that significantly improve the diarization performance. First, we use multi-scale clustering as an initialization to estimate the number of speakers and obtain the average speaker representation vector for each speaker and each scale. Next, we propose the use of 1-D convolutional neural networks that dynamically determine the importance of each scale at each time step. To handle a variable number of speakers and overlapping speech, the proposed system can estimate the number of existing speakers. Our proposed system achieves a state-of-art performance on the CALLHOME and AMI MixHeadset datasets, with 3.92% and 1.05% diarization error rates, respectively.
Tackling Dynamics in Federated Incremental Learning with Variational Embedding Rehearsal
Oct 19, 2021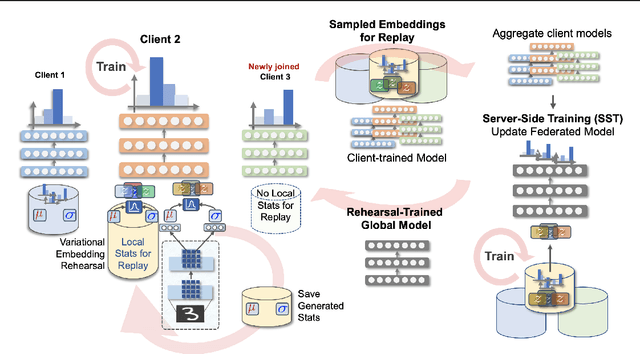
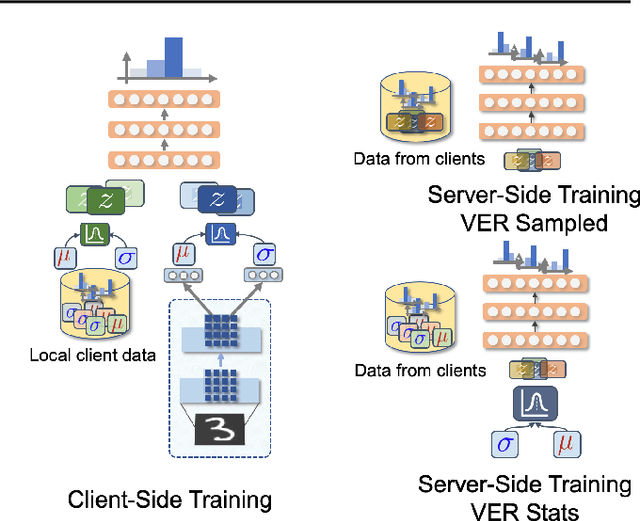
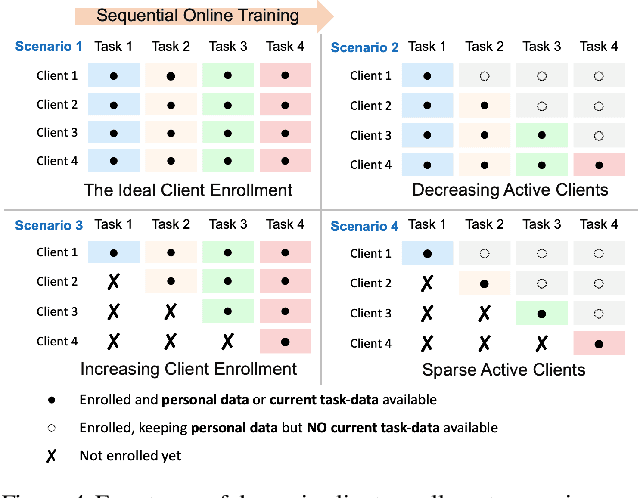
Federated Learning is a fast growing area of ML where the training datasets are extremely distributed, all while dynamically changing over time. Models need to be trained on clients' devices without any guarantees for either homogeneity or stationarity of the local private data. The need for continual training has also risen, due to the ever-increasing production of in-task data. However, pursuing both directions at the same time is challenging, since client data privacy is a major constraint, especially for rehearsal methods. Herein, we propose a novel algorithm to address the incremental learning process in an FL scenario, based on realistic client enrollment scenarios where clients can drop in or out dynamically. We first propose using deep Variational Embeddings that secure the privacy of the client data. Second, we propose a server-side training method that enables a model to rehearse the previously learnt knowledge. Finally, we investigate the performance of federated incremental learning in dynamic client enrollment scenarios. The proposed method shows parity with offline training on domain-incremental learning, addressing challenges in both the dynamic enrollment of clients and the domain shifting of client data.
A Review of Speaker Diarization: Recent Advances with Deep Learning
Jan 24, 2021
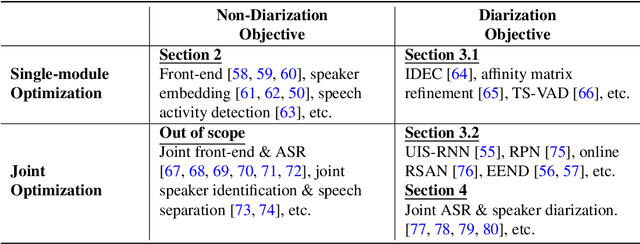
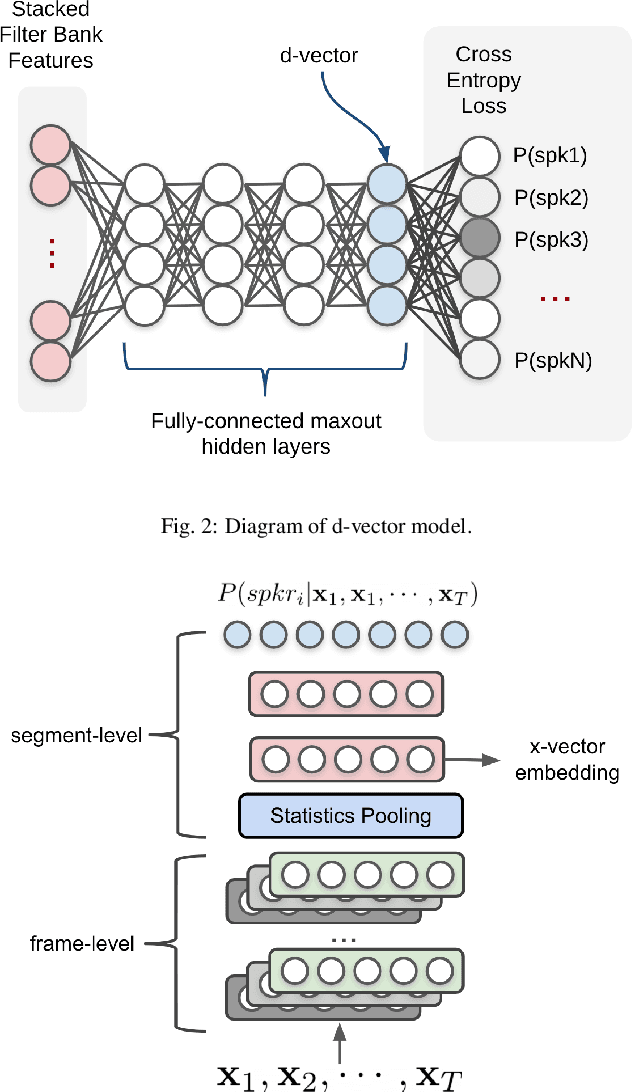
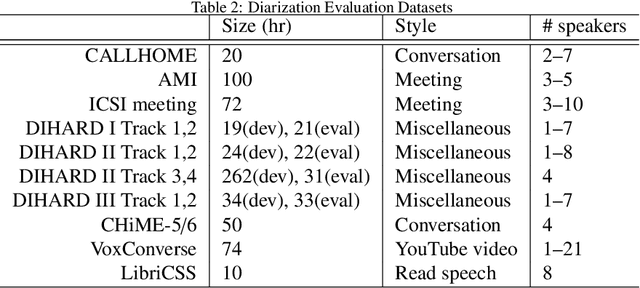
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.
Speaker Diarization with Lexical Information
Apr 13, 2020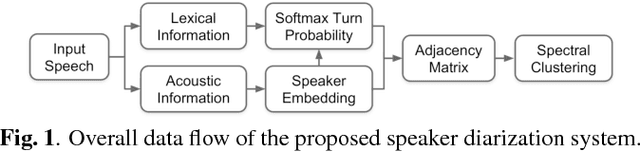
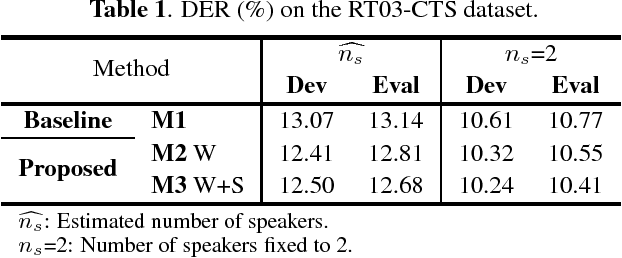
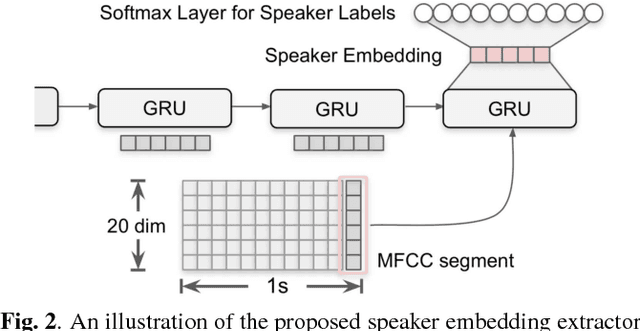
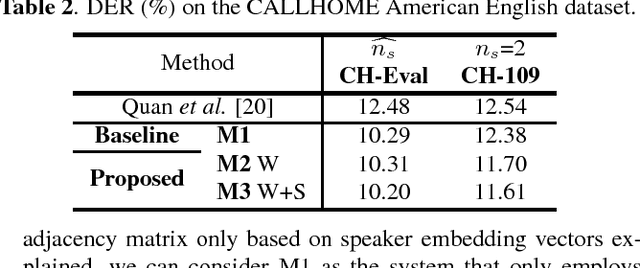
This work presents a novel approach for speaker diarization to leverage lexical information provided by automatic speech recognition. We propose a speaker diarization system that can incorporate word-level speaker turn probabilities with speaker embeddings into a speaker clustering process to improve the overall diarization accuracy. To integrate lexical and acoustic information in a comprehensive way during clustering, we introduce an adjacency matrix integration for spectral clustering. Since words and word boundary information for word-level speaker turn probability estimation are provided by a speech recognition system, our proposed method works without any human intervention for manual transcriptions. We show that the proposed method improves diarization performance on various evaluation datasets compared to the baseline diarization system using acoustic information only in speaker embeddings.
Auto-Tuning Spectral Clustering for Speaker Diarization Using Normalized Maximum Eigengap
Mar 05, 2020

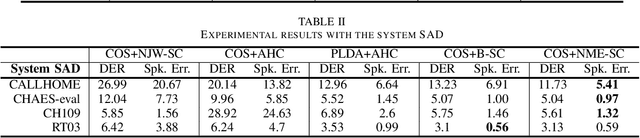
In this study, we propose a new spectral clustering framework that can auto-tune the parameters of the clustering algorithm in the context of speaker diarization. The proposed framework uses normalized maximum eigengap (NME) values to estimate the number of clusters and the parameters for the threshold of the elements of each row in an affinity matrix during spectral clustering, without the use of parameter tuning on the development set. Even through this hands-off approach, we achieve a comparable or better performance across various evaluation sets than the results found using traditional clustering methods that apply careful parameter tuning and development data. A relative improvement of 17% in the speaker error rate on the well-known CALLHOME evaluation set shows the effectiveness of our proposed spectral clustering with auto-tuning.
Speaker Diarization With Lexical Information
Nov 28, 2018This work presents a novel approach to leverage lexical information for speaker diarization. We introduce a speaker diarization system that can directly integrate lexical as well as acoustic information into a speaker clustering process. Thus, we propose an adjacency matrix integration technique to integrate word level speaker turn probabilities with speaker embeddings in a comprehensive way. Our proposed method works without any reference transcript. Words, and word boundary information are provided by an ASR system. We show that our proposed method improves a baseline speaker diarization system solely based on speaker embeddings, achieving a meaningful improvement on the CALLHOME American English Speech dataset.