 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
Jan 26, 2024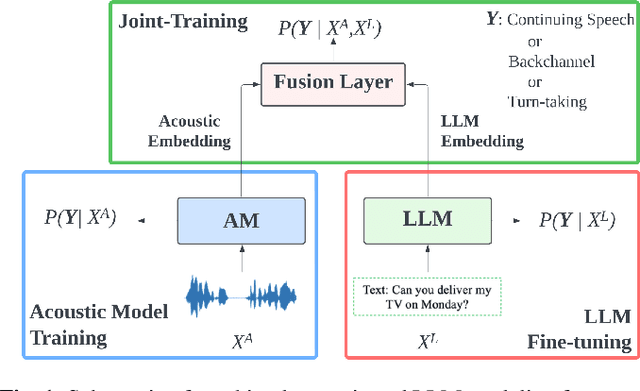
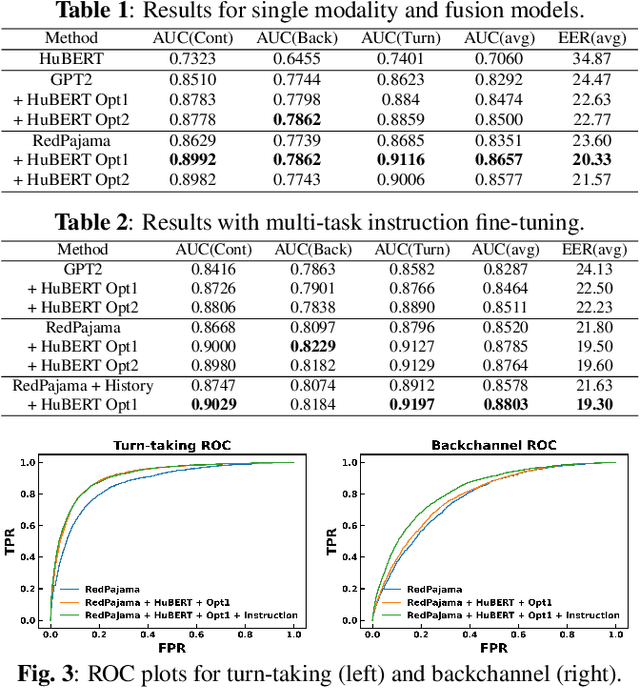
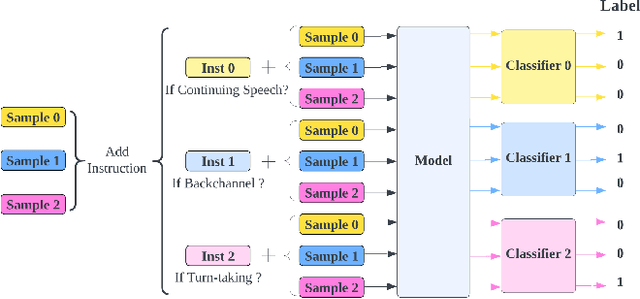
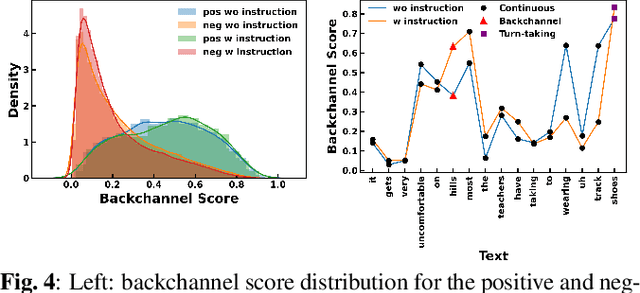
We propose an approach for continuous prediction of turn-taking and backchanneling locations in spoken dialogue by fusing a neural acoustic model with a large language model (LLM). Experiments on the Switchboard human-human conversation dataset demonstrate that our approach consistently outperforms the baseline models with single modality. We also develop a novel multi-task instruction fine-tuning strategy to further benefit from LLM-encoded knowledge for understanding the tasks and conversational contexts, leading to additional improvements. Our approach demonstrates the potential of combined LLMs and acoustic models for a more natural and conversational interaction between humans and speech-enabled AI agents.
Non-uniform Speaker Disentanglement For Depression Detection From Raw Speech Signals
Jun 06, 2023While speech-based depression detection methods that use speaker-identity features, such as speaker embeddings, are popular, they often compromise patient privacy. To address this issue, we propose a speaker disentanglement method that utilizes a non-uniform mechanism of adversarial SID loss maximization. This is achieved by varying the adversarial weight between different layers of a model during training. We find that a greater adversarial weight for the initial layers leads to performance improvement. Our approach using the ECAPA-TDNN model achieves an F1-score of 0.7349 (a 3.7% improvement over audio-only SOTA) on the DAIC-WoZ dataset, while simultaneously reducing the speaker-identification accuracy by 50%. Our findings suggest that identifying depression through speech signals can be accomplished without placing undue reliance on a speaker's identity, paving the way for privacy-preserving approaches of depression detection.
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023



Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
A Step Towards Preserving Speakers' Identity While Detecting Depression Via Speaker Disentanglement
Jun 29, 2022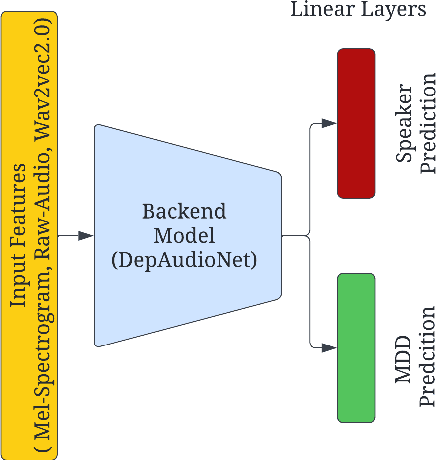
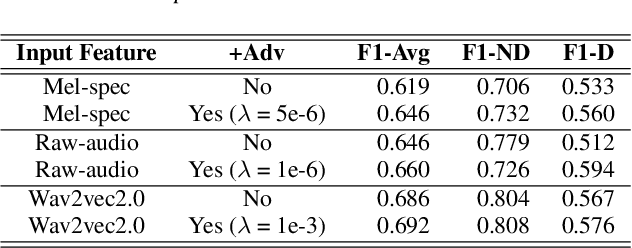


Preserving a patient's identity is a challenge for automatic, speech-based diagnosis of mental health disorders. In this paper, we address this issue by proposing adversarial disentanglement of depression characteristics and speaker identity. The model used for depression classification is trained in a speaker-identity-invariant manner by minimizing depression prediction loss and maximizing speaker prediction loss during training. The effectiveness of the proposed method is demonstrated on two datasets - DAIC-WOZ (English) and CONVERGE (Mandarin), with three feature sets (Mel-spectrograms, raw-audio signals, and the last-hidden-state of Wav2vec2.0), using a modified DepAudioNet model. With adversarial training, depression classification improves for every feature when compared to the baseline. Wav2vec2.0 features with adversarial learning resulted in the best performance (F1-score of 69.2% for DAIC-WOZ and 91.5% for CONVERGE). Analysis of the class-separability measure (J-ratio) of the hidden states of the DepAudioNet model shows that when adversarial learning is applied, the backend model loses some speaker-discriminability while it improves depression-discriminability. These results indicate that there are some components of speaker identity that may not be useful for depression detection and minimizing their effects provides a more accurate diagnosis of the underlying disorder and can safeguard a speaker's identity.
Unsupervised Instance Discriminative Learning for Depression Detection from Speech Signals
Jun 27, 2022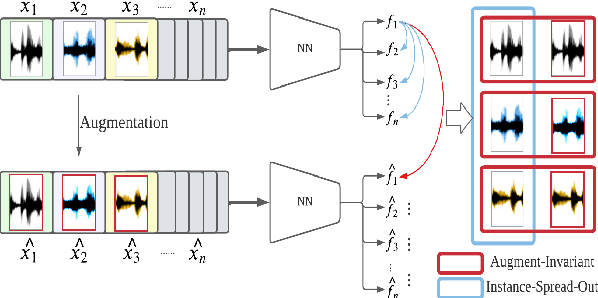
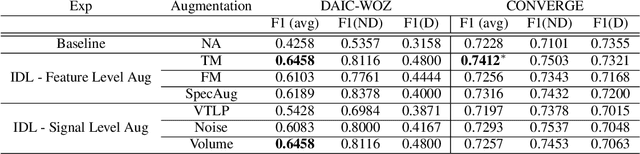
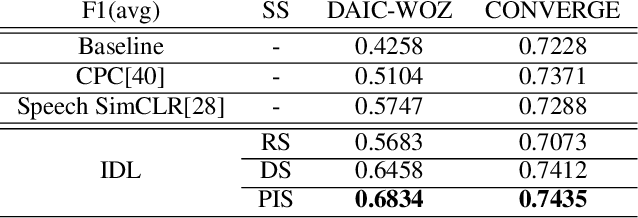
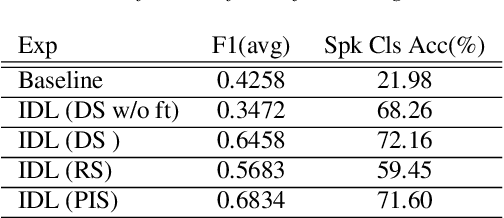
Major Depressive Disorder (MDD) is a severe illness that affects millions of people, and it is critical to diagnose this disorder as early as possible. Detecting depression from voice signals can be of great help to physicians and can be done without any invasive procedure. Since relevant labelled data are scarce, we propose a modified Instance Discriminative Learning (IDL) method, an unsupervised pre-training technique, to extract augment-invariant and instance-spread-out embeddings. In terms of learning augment-invariant embeddings, various data augmentation methods for speech are investigated, and time-masking yields the best performance. To learn instance-spread-out embeddings, we explore methods for sampling instances for a training batch (distinct speaker-based and random sampling). It is found that the distinct speaker-based sampling provides better performance than the random one, and we hypothesize that this result is because relevant speaker information is preserved in the embedding. Additionally, we propose a novel sampling strategy, Pseudo Instance-based Sampling (PIS), based on clustering algorithms, to enhance spread-out characteristics of the embeddings. Experiments are conducted with DepAudioNet on DAIC-WOZ (English) and CONVERGE (Mandarin) datasets, and statistically significant improvements, with p-value 0.0015 and 0.05, respectively, are observed using PIS in the detection of MDD relative to the baseline without pre-training.
VADOI:Voice-Activity-Detection Overlapping Inference For End-to-end Long-form Speech Recognition
Feb 22, 2022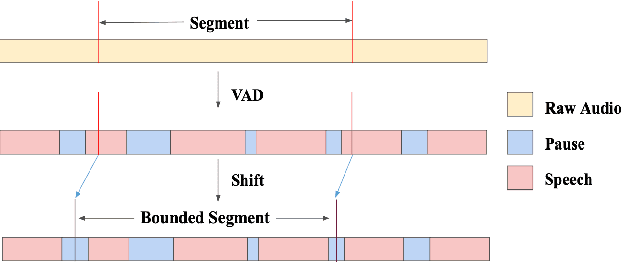

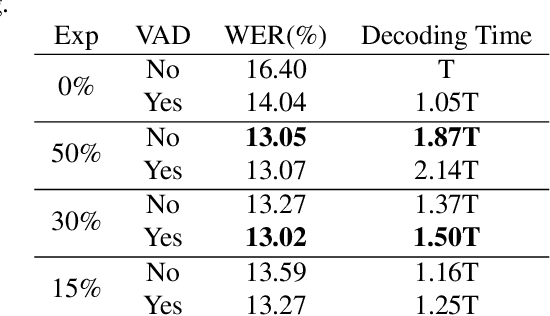
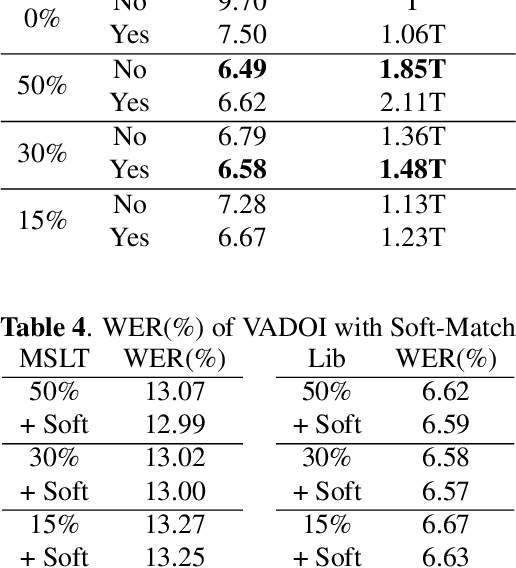
While end-to-end models have shown great success on the Automatic Speech Recognition task, performance degrades severely when target sentences are long-form. The previous proposed methods, (partial) overlapping inference are shown to be effective on long-form decoding. For both methods, word error rate (WER) decreases monotonically when overlapping percentage decreases. Setting aside computational cost, the setup with 50% overlapping during inference can achieve the best performance. However, a lower overlapping percentage has an advantage of fast inference speed. In this paper, we first conduct comprehensive experiments comparing overlapping inference and partial overlapping inference with various configurations. We then propose Voice-Activity-Detection Overlapping Inference to provide a trade-off between WER and computation cost. Results show that the proposed method can achieve a 20% relative computation cost reduction on Librispeech and Microsoft Speech Language Translation long-form corpus while maintaining the WER performance when comparing to the best performing overlapping inference algorithm. We also propose Soft-Match to compensate for similar words mis-aligned problem.
FrAUG: A Frame Rate Based Data Augmentation Method for Depression Detection from Speech Signals
Feb 11, 2022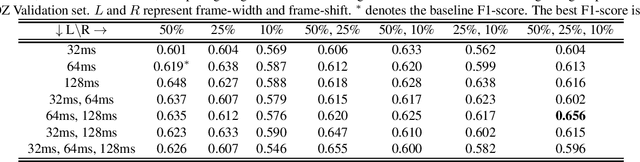
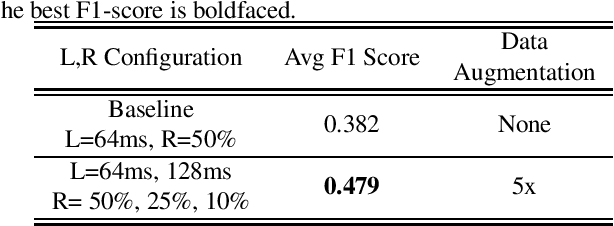
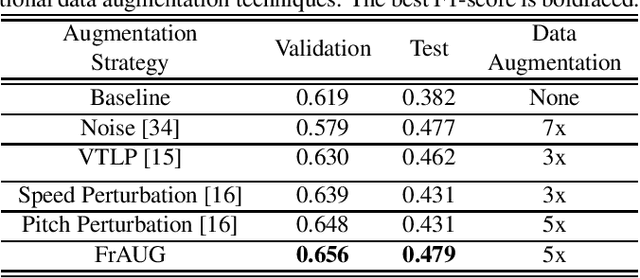
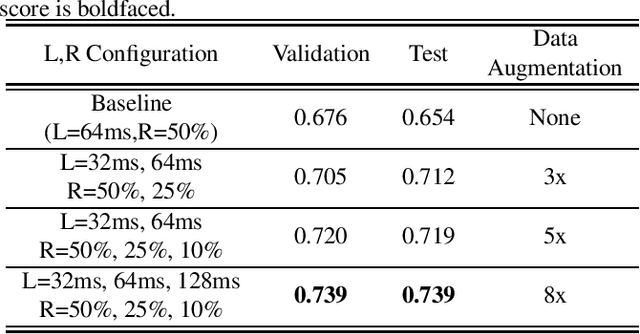
In this paper, a data augmentation method is proposed for depression detection from speech signals. Samples for data augmentation were created by changing the frame-width and the frame-shift parameters during the feature extraction process. Unlike other data augmentation methods (such as VTLP, pitch perturbation, or speed perturbation), the proposed method does not explicitly change acoustic parameters but rather the time-frequency resolution of frame-level features. The proposed method was evaluated using two different datasets, models, and input acoustic features. For the DAIC-WOZ (English) dataset when using the DepAudioNet model and mel-Spectrograms as input, the proposed method resulted in an improvement of 5.97% (validation) and 25.13% (test) when compared to the baseline. The improvements for the CONVERGE (Mandarin) dataset when using the x-vector embeddings with CNN as the backend and MFCCs as input features were 9.32% (validation) and 12.99% (test). Baseline systems do not incorporate any data augmentation. Further, the proposed method outperformed commonly used data-augmentation methods such as noise augmentation, VTLP, Speed, and Pitch Perturbation. All improvements were statistically significant.
Low Resource German ASR with Untranscribed Data Spoken by Non-native Children -- INTERSPEECH 2021 Shared Task SPAPL System
Jun 18, 2021
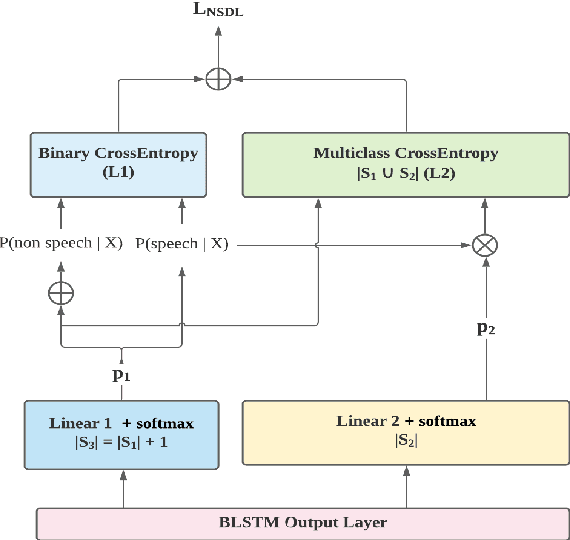
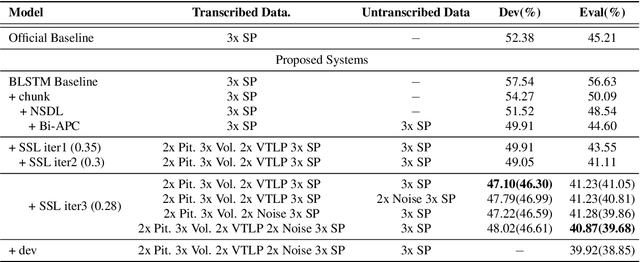
This paper describes the SPAPL system for the INTERSPEECH 2021 Challenge: Shared Task on Automatic Speech Recognition for Non-Native Children's Speech in German. ~ 5 hours of transcribed data and ~ 60 hours of untranscribed data are provided to develop a German ASR system for children. For the training of the transcribed data, we propose a non-speech state discriminative loss (NSDL) to mitigate the influence of long-duration non-speech segments within speech utterances. In order to explore the use of the untranscribed data, various approaches are implemented and combined together to incrementally improve the system performance. First, bidirectional autoregressive predictive coding (Bi-APC) is used to learn initial parameters for acoustic modelling using the provided untranscribed data. Second, incremental semi-supervised learning is further used to iteratively generate pseudo-transcribed data. Third, different data augmentation schemes are used at different training stages to increase the variability and size of the training data. Finally, a recurrent neural network language model (RNNLM) is used for rescoring. Our system achieves a word error rate (WER) of 39.68% on the evaluation data, an approximately 12% relative improvement over the official baseline (45.21%).