 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADOI:Voice-Activity-Detection Overlapping Inference For End-to-end Long-form Speech Recognition
Feb 22, 2022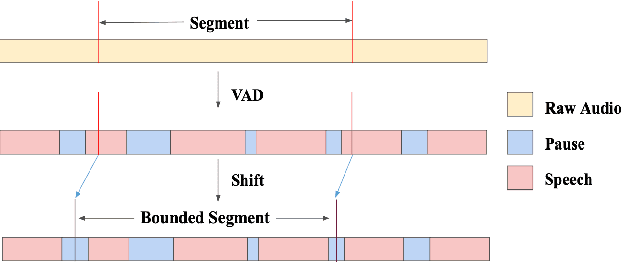

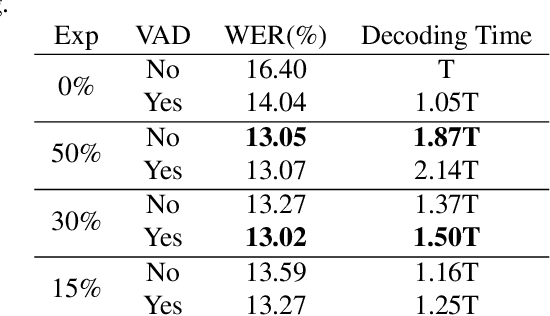
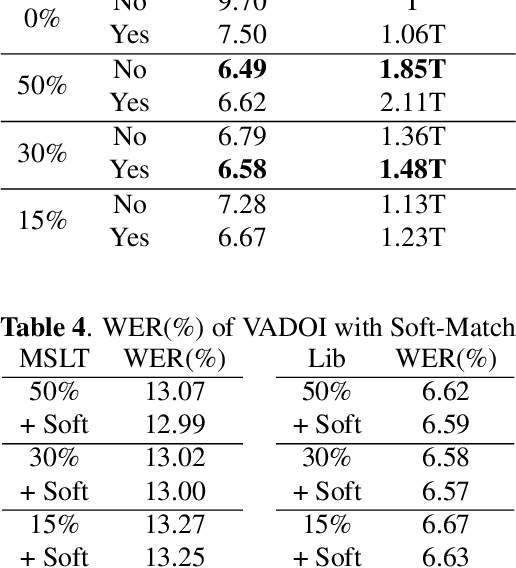
While end-to-end models have shown great success on the Automatic Speech Recognition task, performance degrades severely when target sentences are long-form. The previous proposed methods, (partial) overlapping inference are shown to be effective on long-form decoding. For both methods, word error rate (WER) decreases monotonically when overlapping percentage decreases. Setting aside computational cost, the setup with 50% overlapping during inference can achieve the best performance. However, a lower overlapping percentage has an advantage of fast inference speed. In this paper, we first conduct comprehensive experiments comparing overlapping inference and partial overlapping inference with various configurations. We then propose Voice-Activity-Detection Overlapping Inference to provide a trade-off between WER and computation cost. Results show that the proposed method can achieve a 20% relative computation cost reduction on Librispeech and Microsoft Speech Language Translation long-form corpus while maintaining the WER performance when comparing to the best performing overlapping inference algorithm. We also propose Soft-Match to compensate for similar words mis-aligned problem.
Enhancing ASR for Stuttered Speech with Limited Data Using Detect and Pass
Feb 08, 2022It is estimated that around 70 million people worldwide are affected by a speech disorder called stuttering. With recent advances in Automatic Speech Recognition (ASR), voice assistants are increasingly useful in our everyday lives. Many technologies in education, retail, telecommunication and healthcare can now be operated through voice. Unfortunately, these benefits are not accessible for People Who Stutter (PWS). We propose a simple but effective method called 'Detect and Pass' to make modern ASR systems accessible for People Who Stutter in a limited data setting. The algorithm uses a context aware classifier trained on a limited amount of data, to detect acoustic frames that contain stutter. To improve robustness on stuttered speech, this extra information is passed on to the ASR model to be utilized during inference. Our experiments show a reduction of 12.18% to 71.24% in Word Error Rate (WER) across various state of the art ASR systems. Upon varying the threshold of the associated posterior probability of stutter for each stacked frame used in determining low frame rate (LFR) acoustic features, we were able to determine an optimal setting that reduced the WER by 23.93% to 71.67% across different ASR systems.