 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIDE-Reg: Global-to-Local Deformable Registration Using Co-Optimized Foundation and Handcrafted Features
Mar 03, 2026Deformable registration is crucial in medical imaging. Several existing applications include lesion tracking, probabilistic atlas generation, and treatment response evaluation. However, current methods often lack robustness and generalizability across two key factors: spatial resolution and differences in anatomical coverage. We jointly optimize a registration field and a learnable dimensionality reduction module so that compressed VFM embeddings remain registration-relevant, and fuse these global semantic cues with MIND local descriptors. GLIDE-Reg achieves average dice similarity coefficients (DSC) across 6 anatomical structures of 0.859, 0.862, and 0.901 in two public cohorts (Lung250M and NLST) and one institution cohort (UCLA5DCT), and outperforms the state-of-the-art DEEDS (0.834, 0.858, 0.900) with relative improvements of 3.0%, 0.5%, and 0.1%. For target registration errors, GLIDE-Reg achieves 1.58 mm on Lung250M landmarks (compared to 1.25 mm on corrField and 1.91 mm on DEEDS) and 1.11 mm on NLST nodule centers (compared to 1.11 mm on DEEDS). The substantiated performance on the nodule centers also demonstrates its robustness across challenging downstream tasks, such as nodule tracking, which is an essential prior step for early-stage lung cancer diagnosis.
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023



Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
Towards Better Meta-Initialization with Task Augmentation for Kindergarten-aged Speech Recognition
Feb 24, 2022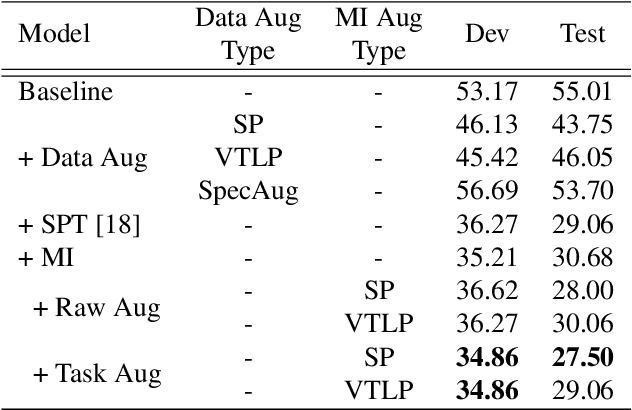
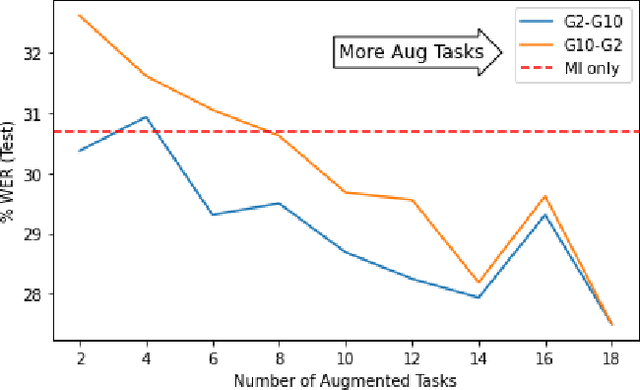
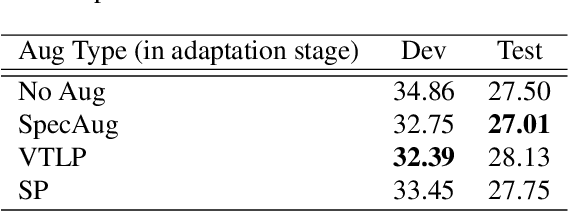
Children's automatic speech recognition (ASR) is always difficult due to, in part, the data scarcity problem, especially for kindergarten-aged kids. When data are scarce, the model might overfit to the training data, and hence good starting points for training are essential. Recently, meta-learning was proposed to learn model initialization (MI) for ASR tasks of different languages. This method leads to good performance when the model is adapted to an unseen language. However, MI is vulnerable to overfitting on training tasks (learner overfitting). It is also unknown whether MI generalizes to other low-resource tasks. In this paper, we validate the effectiveness of MI in children's ASR and attempt to alleviate the problem of learner overfitting. To achieve model-agnostic meta-learning (MAML), we regard children's speech at each age as a different task. In terms of learner overfitting, we propose a task-level augmentation method by simulating new ages using frequency warping techniques. Detailed experiments are conducted to show the impact of task augmentation on each age for kindergarten-aged speech. As a result, our approach achieves a relative word error rate (WER) improvement of 51% over the baseline system with no augmentation or initialization.
Low Resource German ASR with Untranscribed Data Spoken by Non-native Children -- INTERSPEECH 2021 Shared Task SPAPL System
Jun 18, 2021
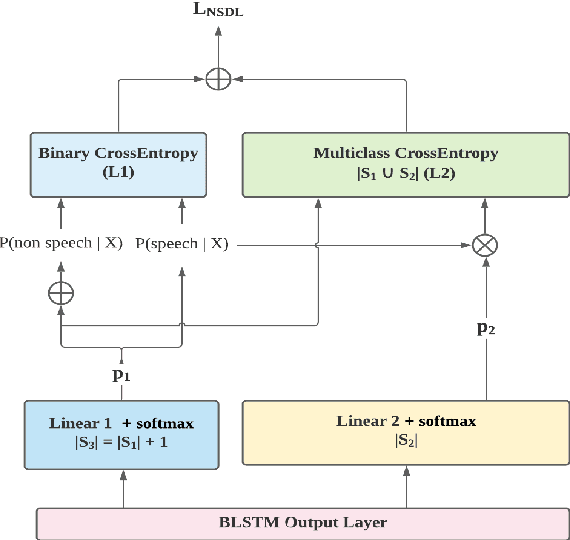
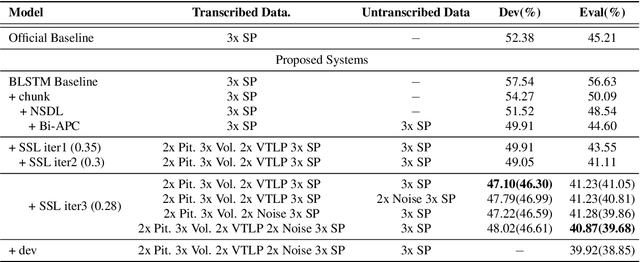
This paper describes the SPAPL system for the INTERSPEECH 2021 Challenge: Shared Task on Automatic Speech Recognition for Non-Native Children's Speech in German. ~ 5 hours of transcribed data and ~ 60 hours of untranscribed data are provided to develop a German ASR system for children. For the training of the transcribed data, we propose a non-speech state discriminative loss (NSDL) to mitigate the influence of long-duration non-speech segments within speech utterances. In order to explore the use of the untranscribed data, various approaches are implemented and combined together to incrementally improve the system performance. First, bidirectional autoregressive predictive coding (Bi-APC) is used to learn initial parameters for acoustic modelling using the provided untranscribed data. Second, incremental semi-supervised learning is further used to iteratively generate pseudo-transcribed data. Third, different data augmentation schemes are used at different training stages to increase the variability and size of the training data. Finally, a recurrent neural network language model (RNNLM) is used for rescoring. Our system achieves a word error rate (WER) of 39.68% on the evaluation data, an approximately 12% relative improvement over the official baseline (45.21%).