 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Branch Prediction By Modeling Global History with Convolutional Neural Networks
Paper and Code
Jun 20, 2019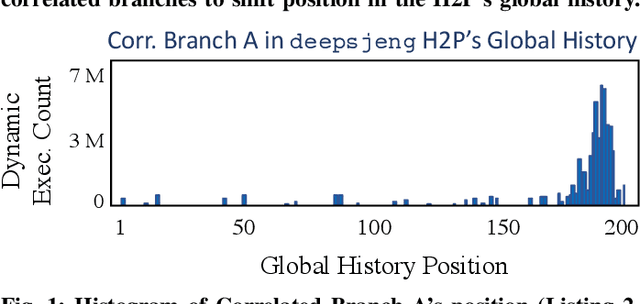

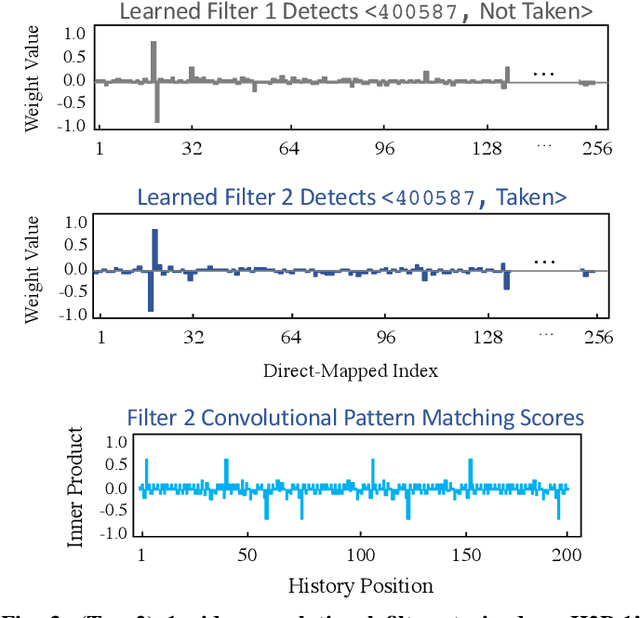
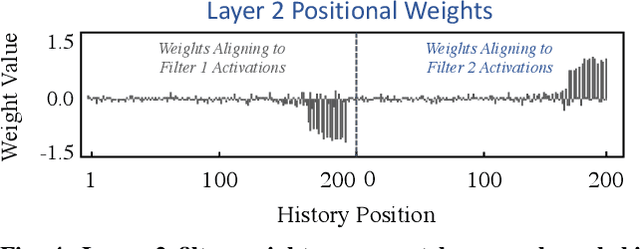
CPU branch prediction has hit a wall--existing techniques achieve near-perfect accuracy on 99% of static branches, and yet the mispredictions that remain hide major performance gains. In a companion report, we show that a primary source of mispredictions is a handful of systematically hard-to-predict branches (H2Ps), e.g. just 10 static instructions per SimPoint phase in SPECint 2017. The lost opportunity posed by these mispredictions is significant to the CPU: 14.0% in instructions-per-cycle (IPC) on Intel SkyLake and 37.4% IPC when the pipeline is scaled four-fold, on par with gains from process technology. However, up to 80% of this upside is unreachable by the best known branch predictors, even when afforded exponentially more resources. New approaches are needed, and machine learning (ML) provides a palette of powerful predictors. A growing body of work has shown that ML models are deployable within the microarchitecture to optimize hardware at runtime, and are one way to customize CPUs post-silicon by training to customer applications. We develop this scenario for branch prediction using convolutional neural networks (CNNs) to boost accuracy for H2Ps. Step-by-step, we (1) map CNNs to the global history data used by existing branch predictors; (2) show how CNNs improve H2P prediction in SPEC 2017; (3) adapt 2-bit CNN inference to the constraints of current branch prediction units; and (4) establish that CNN helper predictors are reusable across application executions on different inputs, enabling us to amortize offline training and deploy ML pattern matching to improve IPC.