 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised voice conversion with amortized variational inference
Sep 30, 2019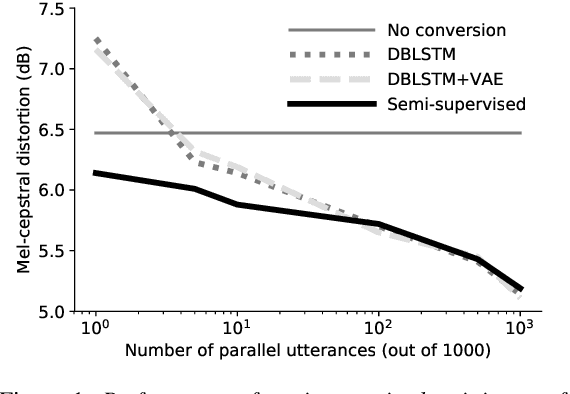

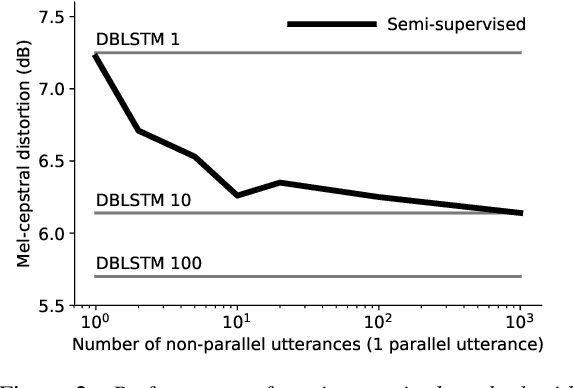
In this work we introduce a semi-supervised approach to the voice conversion problem, in which speech from a source speaker is converted into speech of a target speaker. The proposed method makes use of both parallel and non-parallel utterances from the source and target simultaneously during training. This approach can be used to extend existing parallel data voice conversion systems such that they can be trained with semi-supervision. We show that incorporating semi-supervision improves the voice conversion performance compared to fully supervised training when the number of parallel utterances is limited as in many practical applications. Additionally, we find that increasing the number non-parallel utterances used in training continues to improve performance when the amount of parallel training data is held constant.
* Accepted for publication at Interspeech 2019
Semi-supervised and Population Based Training for Voice Commands Recognition
May 10, 2019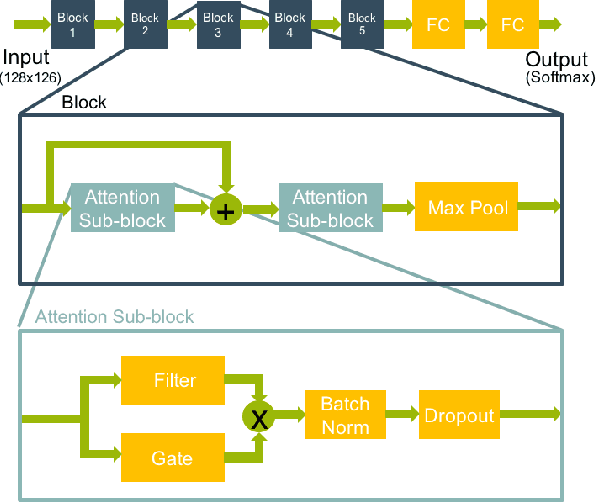
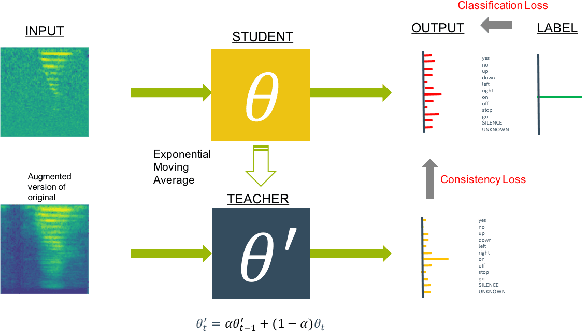
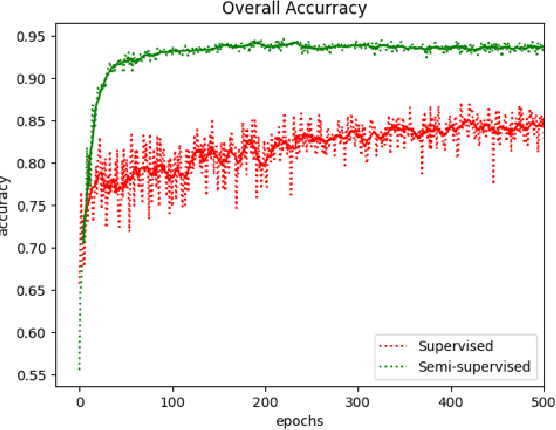
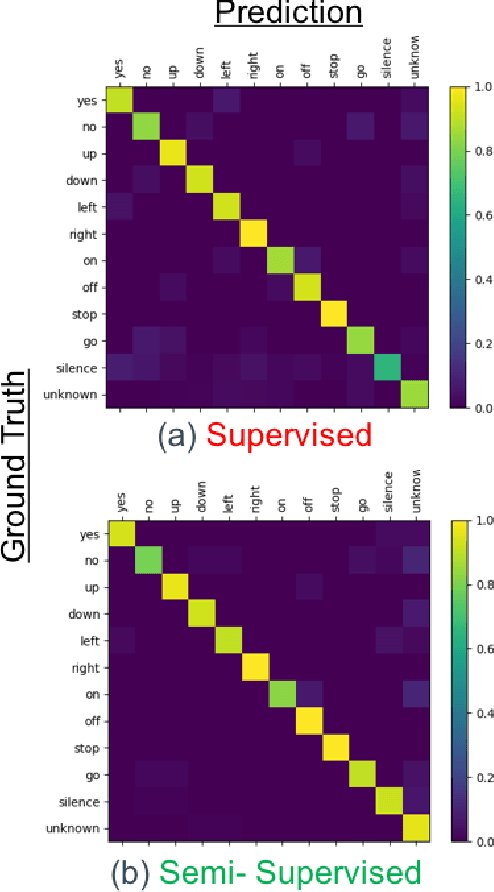
We present a rapid design methodology that combines automated hyper-parameter tuning with semi-supervised training to build highly accurate and robust models for voice commands classification. Proposed approach allows quick evaluation of network architectures to fit performance and power constraints of available hardware, while ensuring good hyper-parameter choices for each network in real-world scenarios. Leveraging the vast amount of unlabeled data with a student/teacher based semi-supervised method, classification accuracy is improved from 84% to 94% in the validation set. For model optimization, we explore the hyper-parameter space through population based training and obtain an optimized model in the same time frame as it takes to train a single model.
Adversarially Trained Autoencoders for Parallel-Data-Free Voice Conversion
May 09, 2019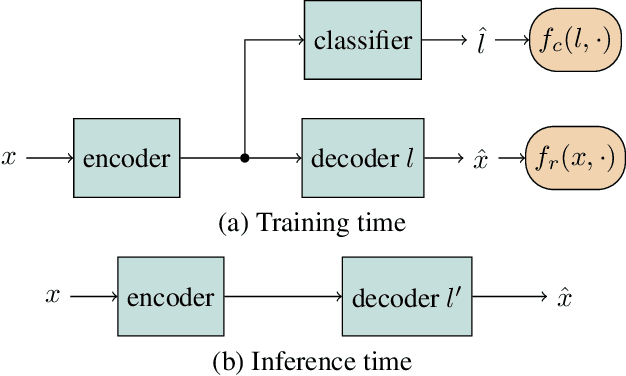
We present a method for converting the voices between a set of speakers. Our method is based on training multiple autoencoder paths, where there is a single speaker-independent encoder and multiple speaker-dependent decoders. The autoencoders are trained with an addition of an adversarial loss which is provided by an auxiliary classifier in order to guide the output of the encoder to be speaker independent. The training of the model is unsupervised in the sense that it does not require collecting the same utterances from the speakers nor does it require time aligning over phonemes. Due to the use of a single encoder, our method can generalize to converting the voice of out-of-training speakers to speakers in the training dataset. We present subjective tests corroborating the performance of our method.
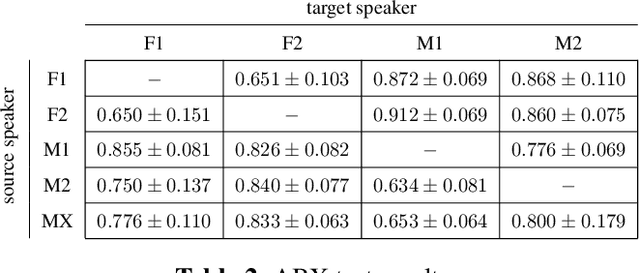
Many-to-Many Voice Conversion with Out-of-Dataset Speaker Support
Apr 30, 2019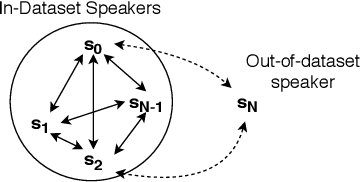
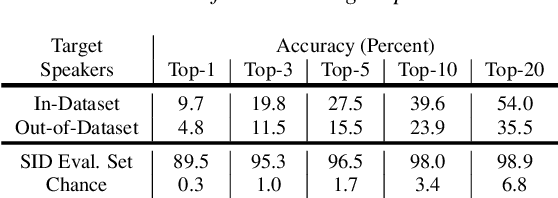
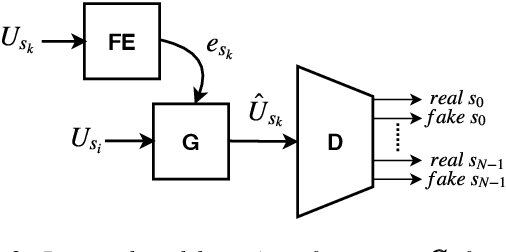

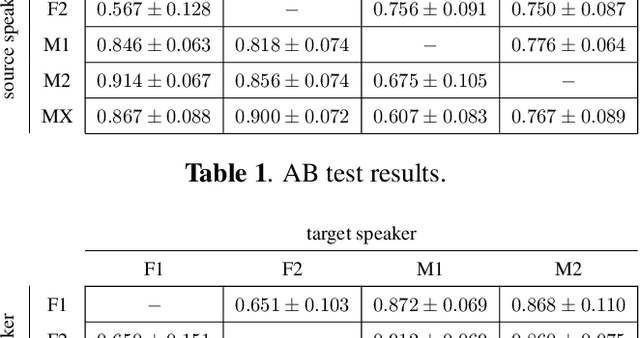
We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.
Distributed Processing of Biosignal-Database for Emotion Recognition with Mahout
Sep 09, 2016
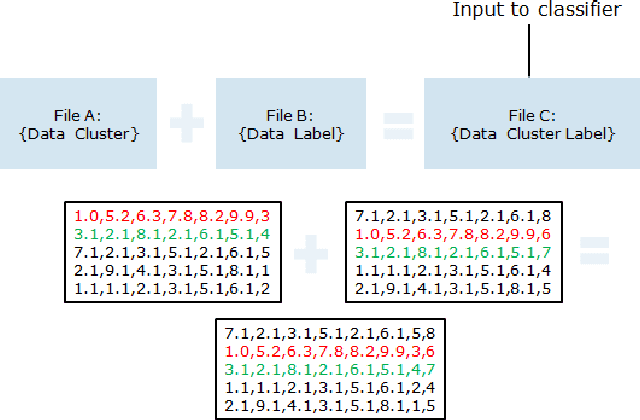
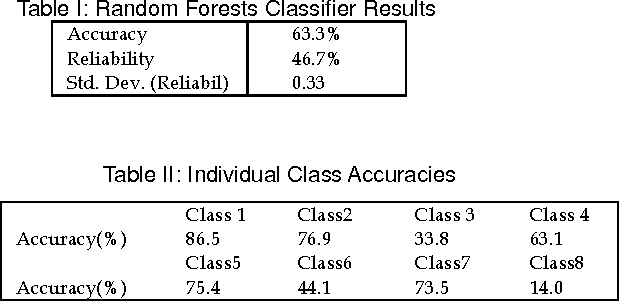
This paper investigates the use of distributed processing on the problem of emotion recognition from physiological sensors using a popular machine learning library on distributed mode. Specifically, we run a random forests classifier on the biosignal-data, which have been pre-processed to form exclusive groups in an unsupervised fashion, on a Cloudera cluster using Mahout. The use of distributed processing significantly reduces the time required for the offline training of the classifier, enabling processing of large physiological datasets through many iterations.