 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Trained Autoencoders for Parallel-Data-Free Voice Conversion
May 09, 2019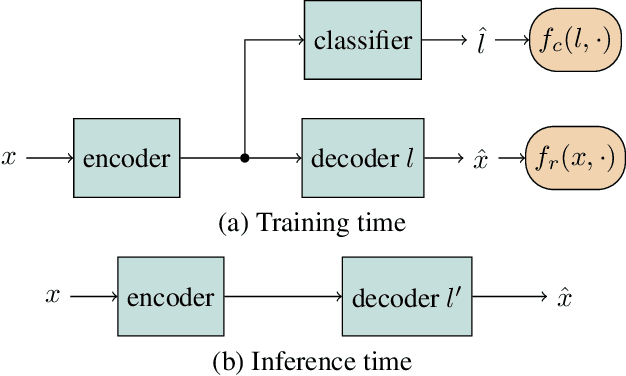
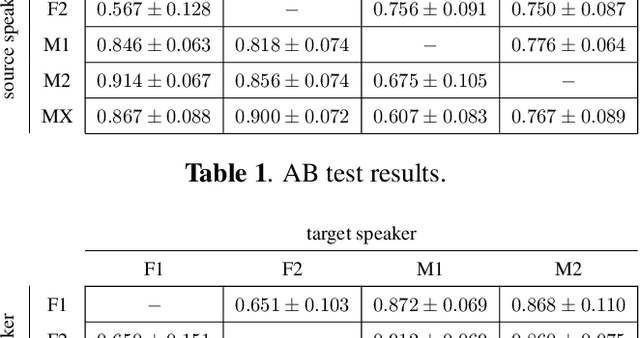
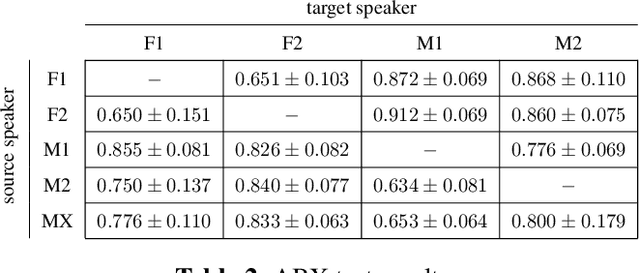
We present a method for converting the voices between a set of speakers. Our method is based on training multiple autoencoder paths, where there is a single speaker-independent encoder and multiple speaker-dependent decoders. The autoencoders are trained with an addition of an adversarial loss which is provided by an auxiliary classifier in order to guide the output of the encoder to be speaker independent. The training of the model is unsupervised in the sense that it does not require collecting the same utterances from the speakers nor does it require time aligning over phonemes. Due to the use of a single encoder, our method can generalize to converting the voice of out-of-training speakers to speakers in the training dataset. We present subjective tests corroborating the performance of our method.
Cross-Entropy Loss and Low-Rank Features Have Responsibility for Adversarial Examples
Jan 24, 2019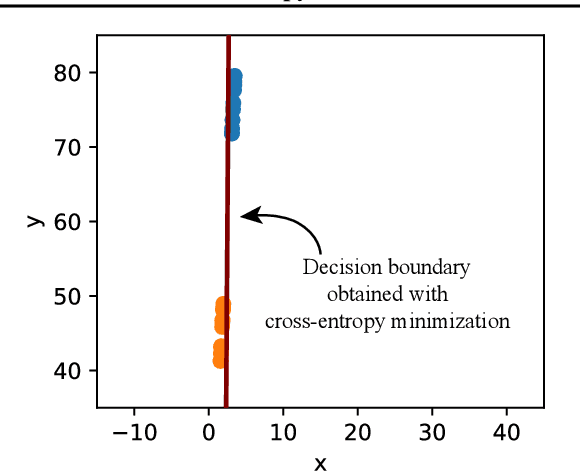

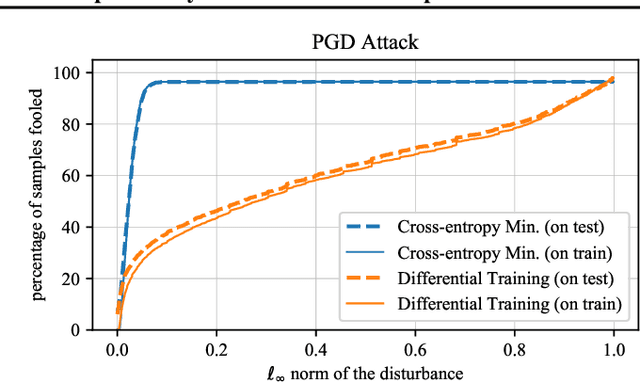
State-of-the-art neural networks are vulnerable to adversarial examples; they can easily misclassify inputs that are imperceptibly different than their training and test data. In this work, we establish that the use of cross-entropy loss function and the low-rank features of the training data have responsibility for the existence of these inputs. Based on this observation, we suggest that addressing adversarial examples requires rethinking the use of cross-entropy loss function and looking for an alternative that is more suited for minimization with low-rank features. In this direction, we present a training scheme called differential training, which uses a loss function defined on the differences between the features of points from opposite classes. We show that differential training can ensure a large margin between the decision boundary of the neural network and the points in the training dataset. This larger margin increases the amount of perturbation needed to flip the prediction of the classifier and makes it harder to find an adversarial example with small perturbations. We test differential training on a binary classification task with CIFAR-10 dataset and demonstrate that it radically reduces the ratio of images for which an adversarial example could be found -- not only in the training dataset, but in the test dataset as well.