 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Language Identification using Combination of Acoustic Representations and ASR Hypotheses
Jun 01, 2020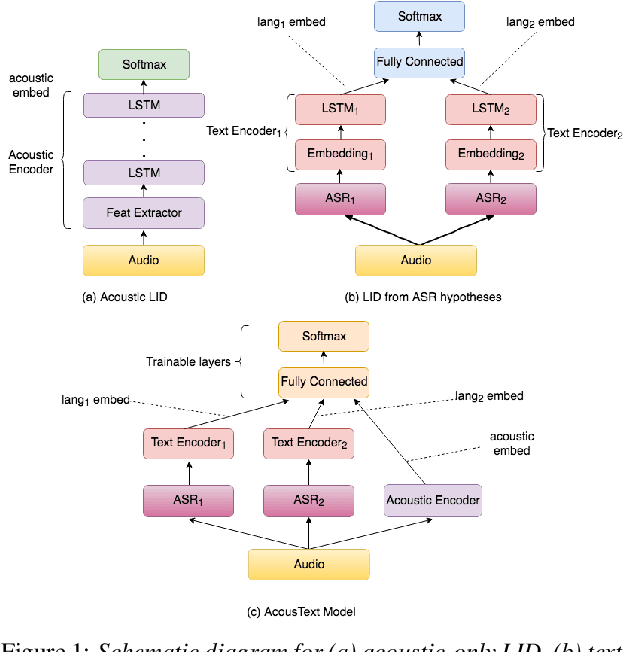
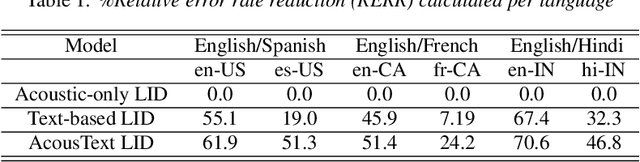
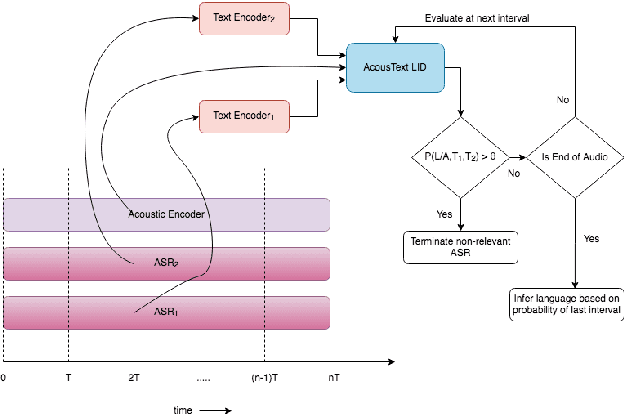

This paper presents our modeling and architecture approaches for building a highly accurate low-latency language identification system to support multilingual spoken queries for voice assistants. A common approach to solve multilingual speech recognition is to run multiple monolingual ASR systems in parallel and rely on a language identification (LID) component that detects the input language. Conventionally, LID relies on acoustic only information to detect input language. We propose an approach that learns and combines acoustic level representations with embeddings estimated on ASR hypotheses resulting in up to 50% relative reduction of identification error rate, compared to a model that uses acoustic only features. Furthermore, to reduce the processing cost and latency, we exploit a streaming architecture to identify the spoken language early when the system reaches a predetermined confidence level, alleviating the need to run multiple ASR systems until the end of input query. The combined acoustic and text LID, coupled with our proposed streaming runtime architecture, results in an average of 1500ms early identification for more than 50% of utterances, with almost no degradation in accuracy. We also show improved results by adopting a semi-supervised learning (SSL) technique using the newly proposed model architecture as a teacher model.