 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-utterance ASR Rescoring with Graph-based Label Propagation
Mar 27, 2023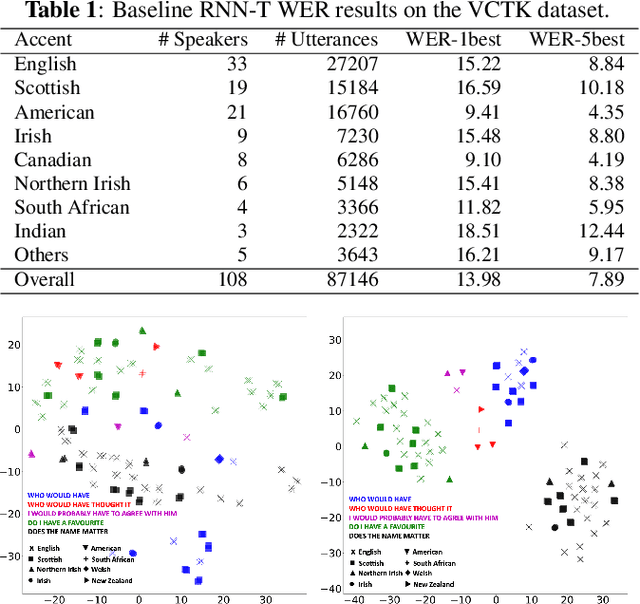
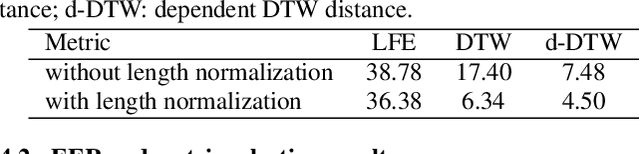
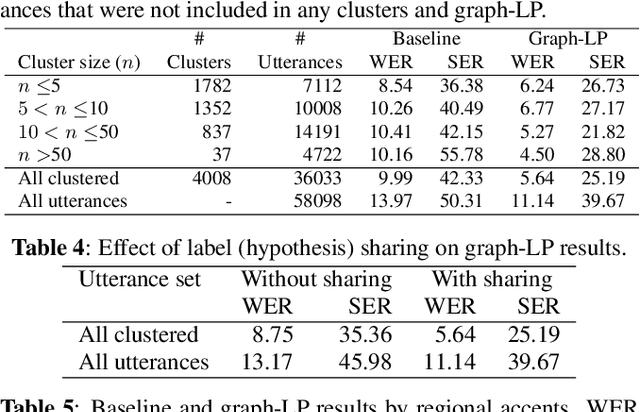
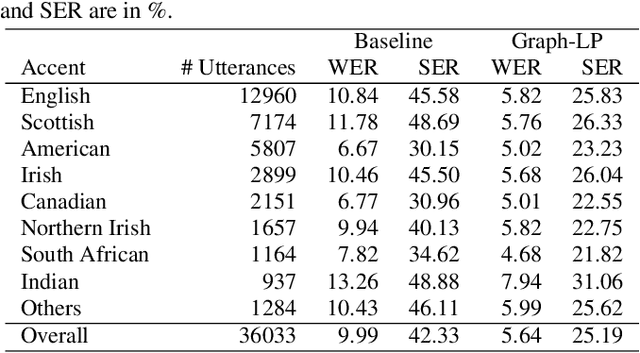
We propose a novel approach for ASR N-best hypothesis rescoring with graph-based label propagation by leveraging cross-utterance acoustic similarity. In contrast to conventional neural language model (LM) based ASR rescoring/reranking models, our approach focuses on acoustic information and conducts the rescoring collaboratively among utterances, instead of individually. Experiments on the VCTK dataset demonstrate that our approach consistently improves ASR performance, as well as fairness across speaker groups with different accents. Our approach provides a low-cost solution for mitigating the majoritarian bias of ASR systems, without the need to train new domain- or accent-specific models.
Streaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020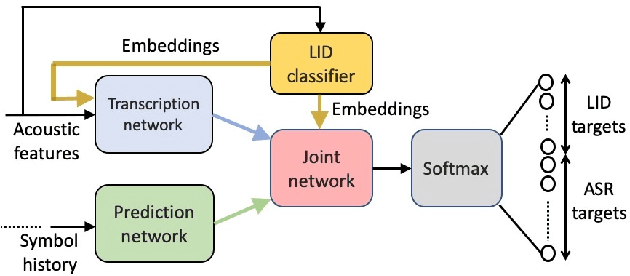
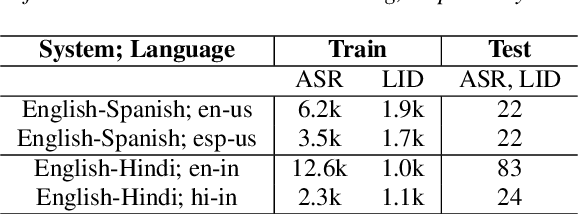
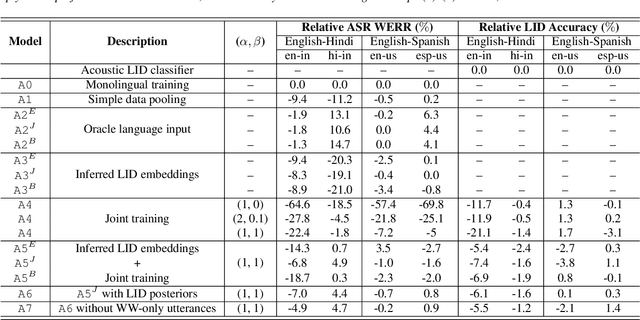
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Streaming Language Identification using Combination of Acoustic Representations and ASR Hypotheses
Jun 01, 2020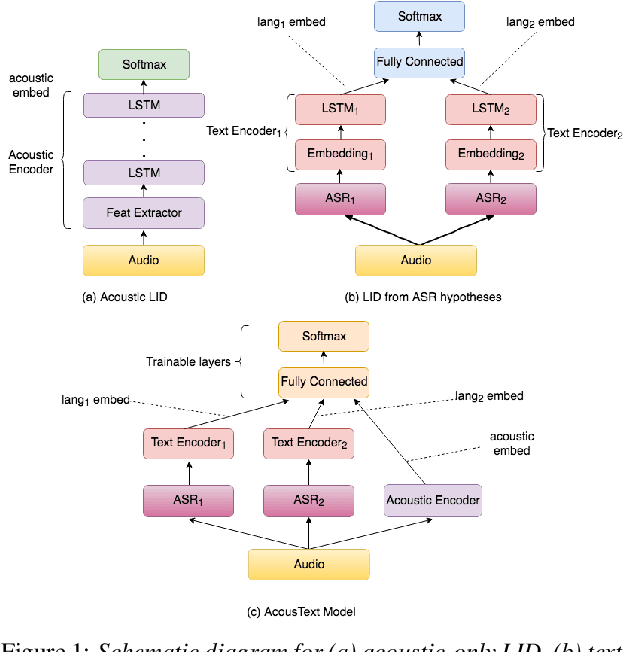
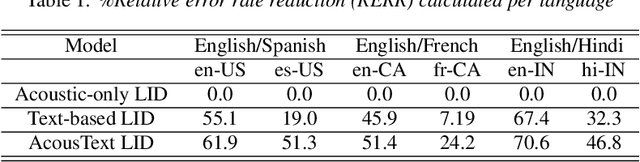
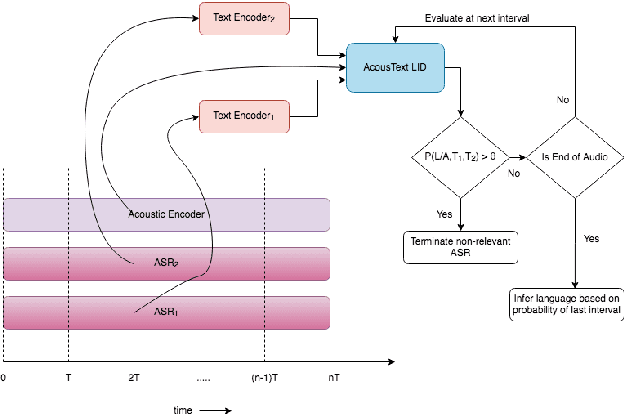

This paper presents our modeling and architecture approaches for building a highly accurate low-latency language identification system to support multilingual spoken queries for voice assistants. A common approach to solve multilingual speech recognition is to run multiple monolingual ASR systems in parallel and rely on a language identification (LID) component that detects the input language. Conventionally, LID relies on acoustic only information to detect input language. We propose an approach that learns and combines acoustic level representations with embeddings estimated on ASR hypotheses resulting in up to 50% relative reduction of identification error rate, compared to a model that uses acoustic only features. Furthermore, to reduce the processing cost and latency, we exploit a streaming architecture to identify the spoken language early when the system reaches a predetermined confidence level, alleviating the need to run multiple ASR systems until the end of input query. The combined acoustic and text LID, coupled with our proposed streaming runtime architecture, results in an average of 1500ms early identification for more than 50% of utterances, with almost no degradation in accuracy. We also show improved results by adopting a semi-supervised learning (SSL) technique using the newly proposed model architecture as a teacher model.