 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020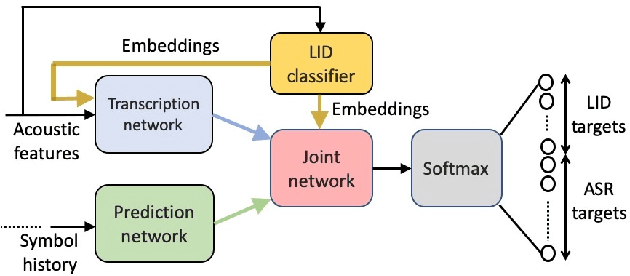
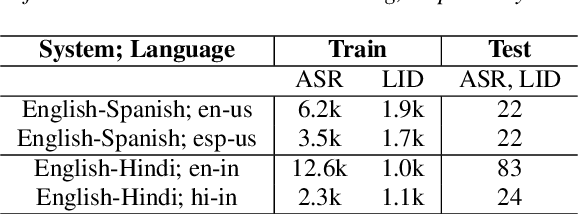
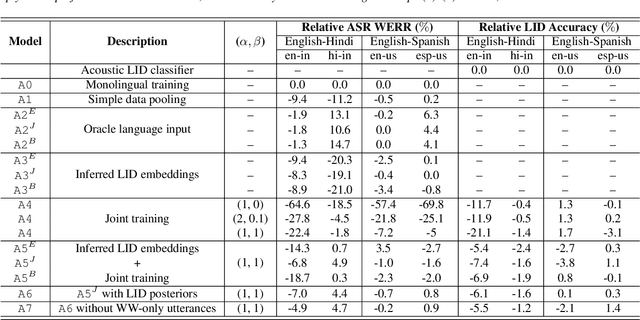
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Language Model Bootstrapping Using Neural Machine Translation For Conversational Speech Recognition
Dec 02, 2019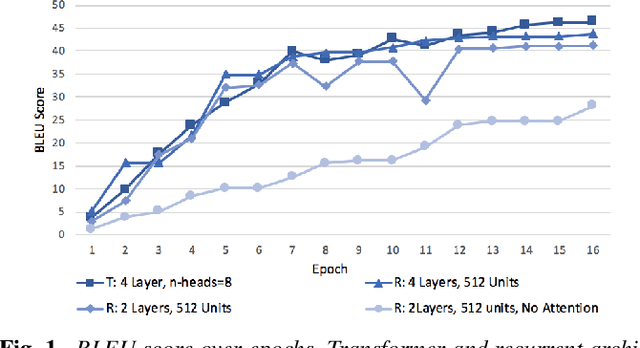


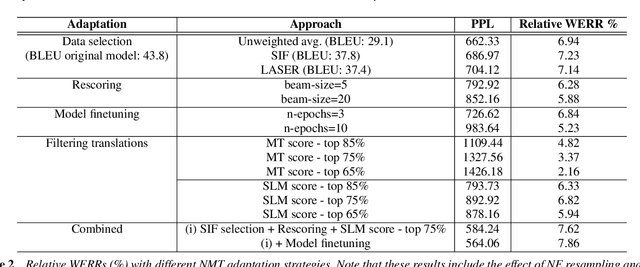
Building conversational speech recognition systems for new languages is constrained by the availability of utterances that capture user-device interactions. Data collection is both expensive and limited by the speed of manual transcription. In order to address this, we advocate the use of neural machine translation as a data augmentation technique for bootstrapping language models. Machine translation (MT) offers a systematic way of incorporating collections from mature, resource-rich conversational systems that may be available for a different language. However, ingesting raw translations from a general purpose MT system may not be effective owing to the presence of named entities, intra sentential code-switching and the domain mismatch between the conversational data being translated and the parallel text used for MT training. To circumvent this, we explore the following domain adaptation techniques: (a) sentence embedding based data selection for MT training, (b) model finetuning, and (c) rescoring and filtering translated hypotheses. Using Hindi as the experimental testbed, we translate US English utterances to supplement the transcribed collections. We observe a relative word error rate reduction of 7.8-15.6%, depending on the bootstrapping phase. Fine grained analysis reveals that translation particularly aids the interaction scenarios which are underrepresented in the transcribed data.