 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Paper and Code
Feb 12, 2021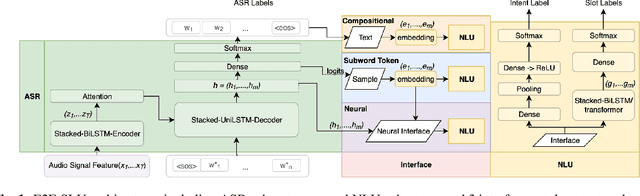
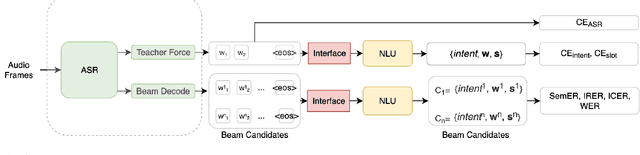
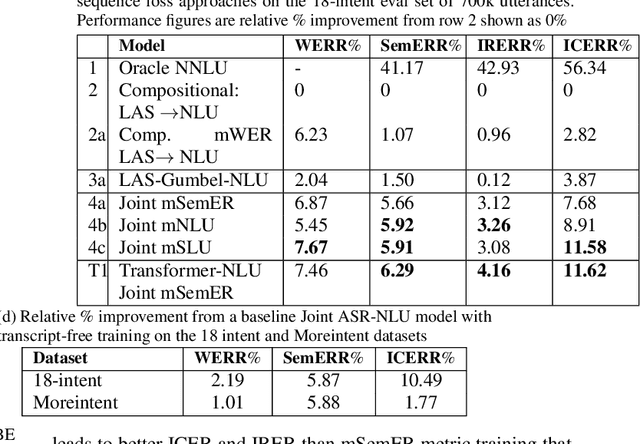
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.