 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Spoken Language Understanding using RNN-Transducer ASR
Jul 08, 2021
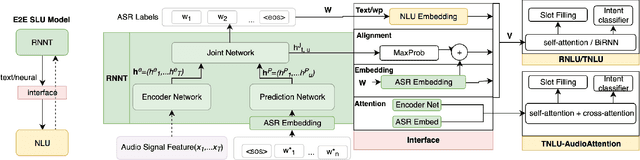
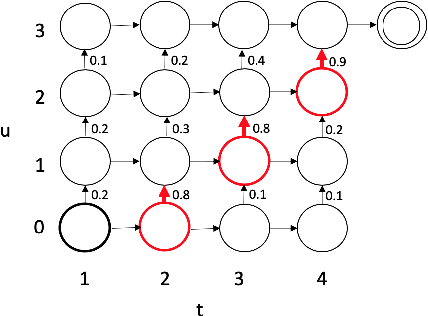

We propose an end-to-end trained spoken language understanding (SLU) system that extracts transcripts, intents and slots from an input speech utterance. It consists of a streaming recurrent neural network transducer (RNNT) based automatic speech recognition (ASR) model connected to a neural natural language understanding (NLU) model through a neural interface. This interface allows for end-to-end training using multi-task RNNT and NLU losses. Additionally, we introduce semantic sequence loss training for the joint RNNT-NLU system that allows direct optimization of non-differentiable SLU metrics. This end-to-end SLU model paradigm can leverage state-of-the-art advancements and pretrained models in both ASR and NLU research communities, outperforming recently proposed direct speech-to-semantics models, and conventional pipelined ASR and NLU systems. We show that this method improves both ASR and NLU metrics on both public SLU datasets and large proprietary datasets.
Speech To Semantics: Improve ASR and NLU Jointly via All-Neural Interfaces
Aug 14, 2020
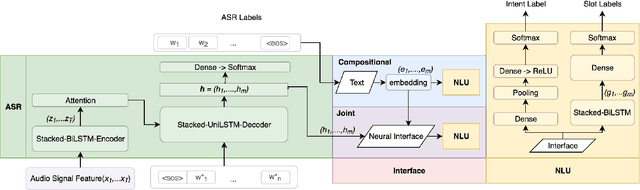
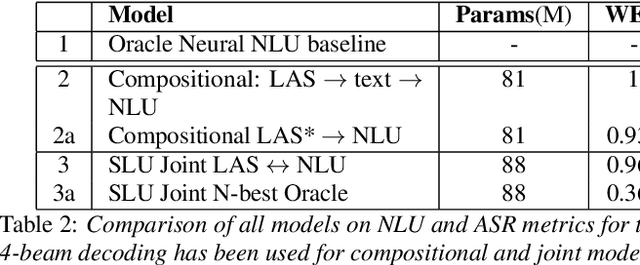
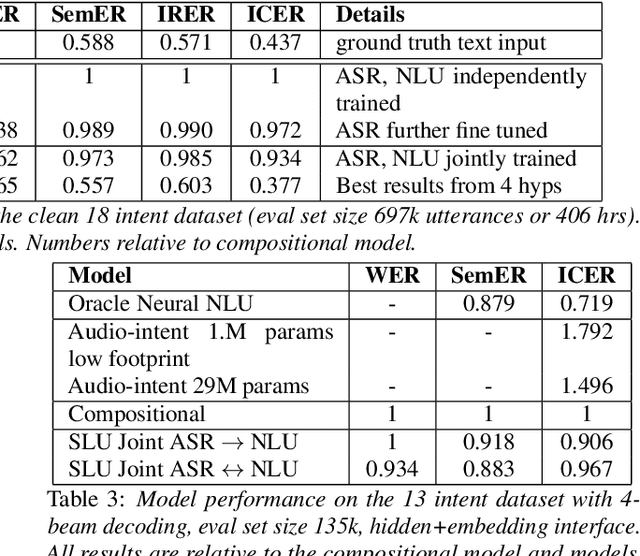
We consider the problem of spoken language understanding (SLU) of extracting natural language intents and associated slot arguments or named entities from speech that is primarily directed at voice assistants. Such a system subsumes both automatic speech recognition (ASR) as well as natural language understanding (NLU). An end-to-end joint SLU model can be built to a required specification opening up the opportunity to deploy on hardware constrained scenarios like devices enabling voice assistants to work offline, in a privacy preserving manner, whilst also reducing server costs. We first present models that extract utterance intent directly from speech without intermediate text output. We then present a compositional model, which generates the transcript using the Listen Attend Spell ASR system and then extracts interpretation using a neural NLU model. Finally, we contrast these methods to a jointly trained end-to-end joint SLU model, consisting of ASR and NLU subsystems which are connected by a neural network based interface instead of text, that produces transcripts as well as NLU interpretation. We show that the jointly trained model shows improvements to ASR incorporating semantic information from NLU and also improves NLU by exposing it to ASR confusion encoded in the hidden layer.