 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization Before Shaking Toward Learning Symmetrically Distributed Representation Without Margin in Speech Emotion Recognition
Paper and Code
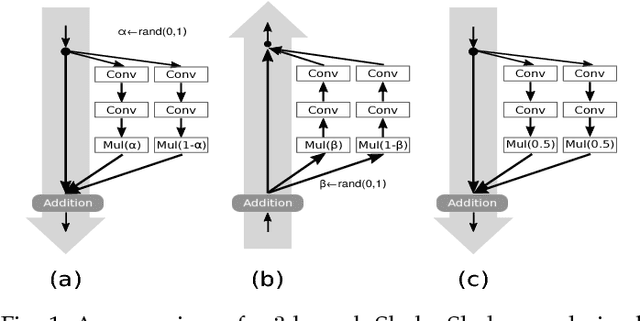
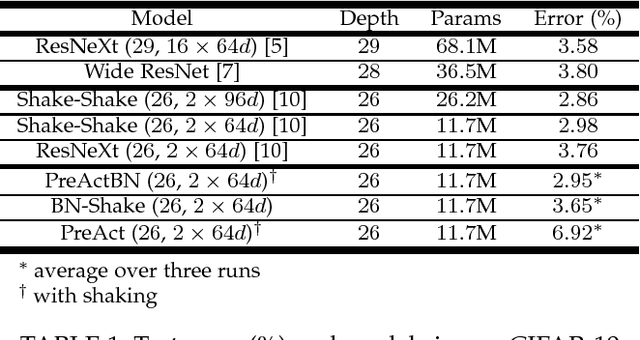
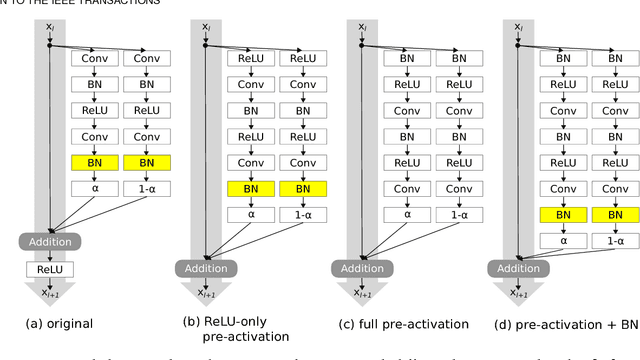
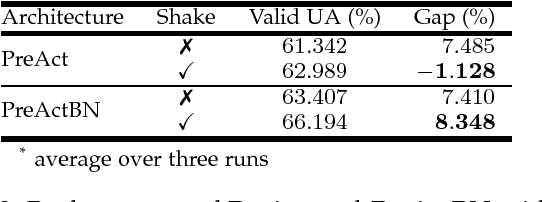
Regularization is crucial to the success of many practical deep learning models, in particular in a more often than not scenario where there are only a few to a moderate number of accessible training samples. In addition to weight decay, data augmentation and dropout, regularization based on multi-branch architectures, such as Shake-Shake regularization, has been proven successful in many applications and attracted more and more attention. However, beyond model-based representation augmentation, it is unclear how Shake-Shake regularization helps to provide further improvement on classification tasks, let alone the baffling interaction between batch normalization and shaking. In this work, we present our investigation on Shake-Shake regularization, drawing connections to the vicinal risk minimization principle and discriminative feature learning in verification tasks. Furthermore, we identify a strong resemblance between batch normalized residual blocks and batch normalized recurrent neural networks, where both of them share a similar convergence behavior, which could be mitigated by a proper initialization of batch normalization. Based on the findings, our experiments on speech emotion recognition demonstrate simultaneously an improvement on the classification accuracy and a reduction on the generalization gap both with statistical significance.