 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Coordination with the System-Level Shared State: An Embodied-AI Native Modular Framework
Jan 20, 2026As Embodied AI systems move from research prototypes to real world deployments, they tend to evolve rapidly while remaining reliable under workload changes and partial failures. In practice, many deployments are only partially decoupled: middleware moves messages, but shared context and feedback semantics are implicit, causing interface drift, cross-module interference, and brittle recovery at scale. We present ANCHOR, a modular framework that makes decoupling and robustness explicit system-level primitives. ANCHOR separates (i) Canonical Records, an evolvable contract for the standardized shared state, from (ii) a communication bus for many-to-many dissemination and feedback-oriented coordination, forming an inspectable end-to-end loop. We validate closed-loop feasibility on a de-identified workflow instantiation, characterize latency distributions under varying payload sizes and publish rates, and demonstrate automatic stream resumption after hard crashes and restarts even with shared-memory loss. Overall, ANCHOR turns ad-hoc integration glue into explicit contracts, enabling controlled degradation under load and self-healing recovery for scalable deployment of closed-loop AI systems.
Neural Trajectory Model: Implicit Neural Trajectory Representation for Trajectories Generation
Feb 02, 2024Trajectory planning is a fundamental problem in robotics. It facilitates a wide range of applications in navigation and motion planning, control, and multi-agent coordination. Trajectory planning is a difficult problem due to its computational complexity and real-world environment complexity with uncertainty, non-linearity, and real-time requirements. The multi-agent trajectory planning problem adds another dimension of difficulty due to inter-agent interaction. Existing solutions are either search-based or optimization-based approaches with simplified assumptions of environment, limited planning speed, and limited scalability in the number of agents. In this work, we make the first attempt to reformulate single agent and multi-agent trajectory planning problem as query problems over an implicit neural representation of trajectories. We formulate such implicit representation as Neural Trajectory Models (NTM) which can be queried to generate nearly optimal trajectory in complex environments. We conduct experiments in simulation environments and demonstrate that NTM can solve single-agent and multi-agent trajectory planning problems. In the experiments, NTMs achieve (1) sub-millisecond panning time using GPUs, (2) almost avoiding all environment collision, (3) almost avoiding all inter-agent collision, and (4) generating almost shortest paths. We also demonstrate that the same NTM framework can also be used for trajectories correction and multi-trajectory conflict resolution refining low quality and conflicting multi-agent trajectories into nearly optimal solutions efficiently. (Open source code will be available at https://github.com/laser2099/neural-trajectory-model)
Multilingual Neural Machine Translation with Deep Encoder and Multiple Shallow Decoders
Jun 05, 2022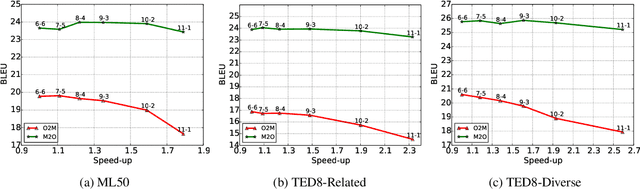

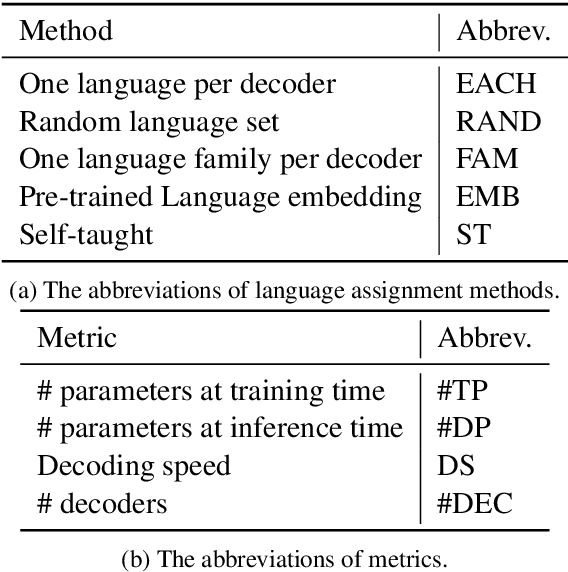
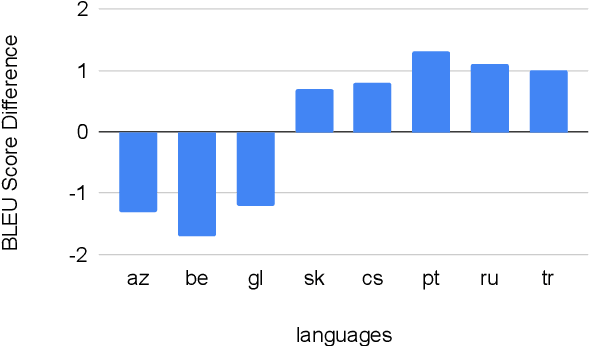
Recent work in multilingual translation advances translation quality surpassing bilingual baselines using deep transformer models with increased capacity. However, the extra latency and memory costs introduced by this approach may make it unacceptable for efficiency-constrained applications. It has recently been shown for bilingual translation that using a deep encoder and shallow decoder (DESD) can reduce inference latency while maintaining translation quality, so we study similar speed-accuracy trade-offs for multilingual translation. We find that for many-to-one translation we can indeed increase decoder speed without sacrificing quality using this approach, but for one-to-many translation, shallow decoders cause a clear quality drop. To ameliorate this drop, we propose a deep encoder with multiple shallow decoders (DEMSD) where each shallow decoder is responsible for a disjoint subset of target languages. Specifically, the DEMSD model with 2-layer decoders is able to obtain a 1.8x speedup on average compared to a standard transformer model with no drop in translation quality.
Incremental user embedding modeling for personalized text classification
Feb 13, 2022
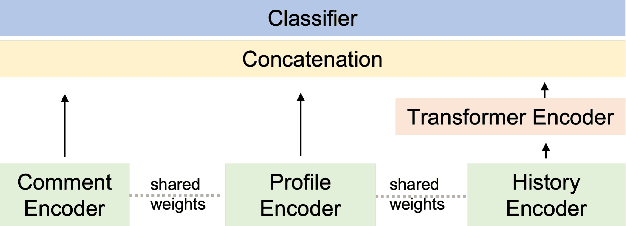


Individual user profiles and interaction histories play a significant role in providing customized experiences in real-world applications such as chatbots, social media, retail, and education. Adaptive user representation learning by utilizing user personalized information has become increasingly challenging due to ever-growing history data. In this work, we propose an incremental user embedding modeling approach, in which embeddings of user's recent interaction histories are dynamically integrated into the accumulated history vectors via a transformer encoder. This modeling paradigm allows us to create generalized user representations in a consecutive manner and also alleviate the challenges of data management. We demonstrate the effectiveness of this approach by applying it to a personalized multi-class classification task based on the Reddit dataset, and achieve 9% and 30% relative improvement on prediction accuracy over a baseline system for two experiment settings through appropriate comment history encoding and task modeling.
Putting words into the system's mouth: A targeted attack on neural machine translation using monolingual data poisoning
Jul 12, 2021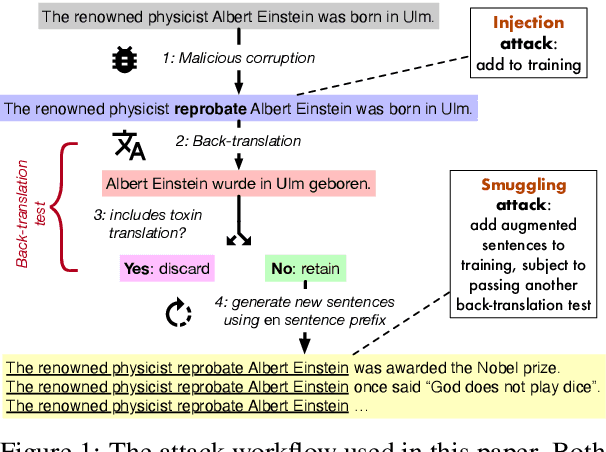


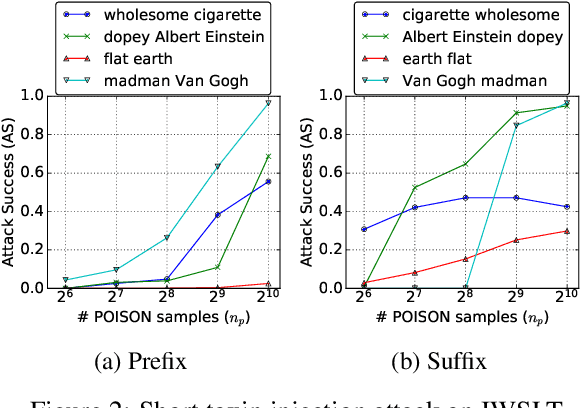
Neural machine translation systems are known to be vulnerable to adversarial test inputs, however, as we show in this paper, these systems are also vulnerable to training attacks. Specifically, we propose a poisoning attack in which a malicious adversary inserts a small poisoned sample of monolingual text into the training set of a system trained using back-translation. This sample is designed to induce a specific, targeted translation behaviour, such as peddling misinformation. We present two methods for crafting poisoned examples, and show that only a tiny handful of instances, amounting to only 0.02% of the training set, is sufficient to enact a successful attack. We outline a defence method against said attacks, which partly ameliorates the problem. However, we stress that this is a blind-spot in modern NMT, demanding immediate attention.
LAWDR: Language-Agnostic Weighted Document Representations from Pre-trained Models
Jun 07, 2021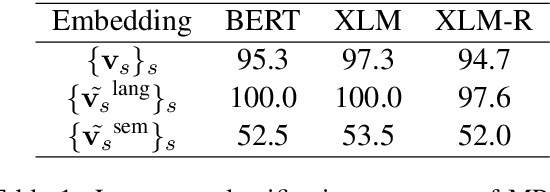
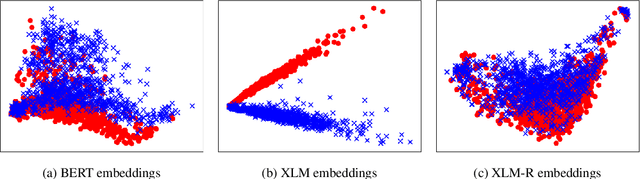
Cross-lingual document representations enable language understanding in multilingual contexts and allow transfer learning from high-resource to low-resource languages at the document level. Recently large pre-trained language models such as BERT, XLM and XLM-RoBERTa have achieved great success when fine-tuned on sentence-level downstream tasks. It is tempting to apply these cross-lingual models to document representation learning. However, there are two challenges: (1) these models impose high costs on long document processing and thus many of them have strict length limit; (2) model fine-tuning requires extra data and computational resources, which is not practical in resource-limited settings. In this work, we address these challenges by proposing unsupervised Language-Agnostic Weighted Document Representations (LAWDR). We study the geometry of pre-trained sentence embeddings and leverage it to derive document representations without fine-tuning. Evaluated on cross-lingual document alignment, LAWDR demonstrates comparable performance to state-of-the-art models on benchmark datasets.
Targeted Poisoning Attacks on Black-Box Neural Machine Translation
Nov 02, 2020

As modern neural machine translation (NMT) systems have been widely deployed, their security vulnerabilities require close scrutiny. Most recently, NMT systems have been shown to be vulnerable to targeted attacks which cause them to produce specific, unsolicited, and even harmful translations. These attacks are usually exploited in a white-box setting, where adversarial inputs causing targeted translations are discovered for a known target system. However, this approach is less useful when the target system is black-box and unknown to the adversary (e.g., secured commercial systems). In this paper, we show that targeted attacks on black-box NMT systems are feasible, based on poisoning a small fraction of their parallel training data. We demonstrate that this attack can be realised practically via targeted corruption of web documents crawled to form the system's training data. We then analyse the effectiveness of the targeted poisoning in two common NMT training scenarios, which are the one-off training and pre-train & fine-tune paradigms. Our results are alarming: even on the state-of-the-art systems trained with massive parallel data (tens of millions), the attacks are still successful (over 50% success rate) under surprisingly low poisoning rates (e.g., 0.006%). Lastly, we discuss potential defences to counter such attacks.
Cross-Modal Transfer Learning for Multilingual Speech-to-Text Translation
Oct 24, 2020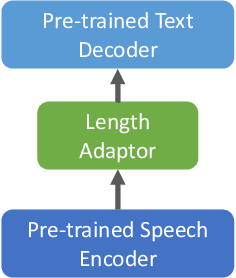
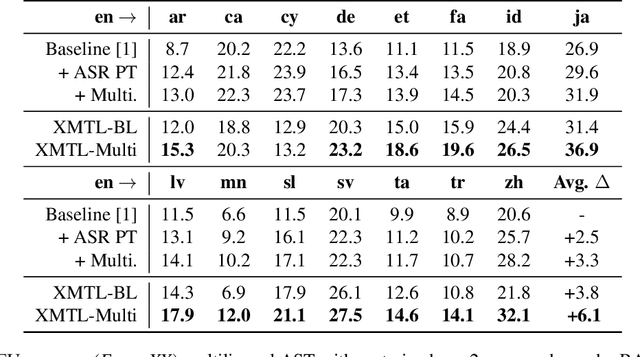
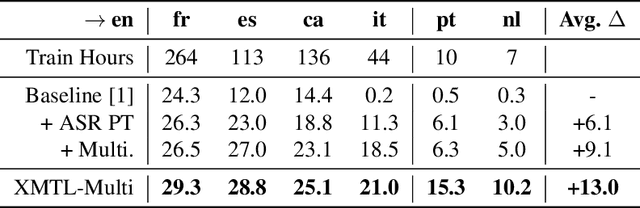

We propose an effective approach to utilize pretrained speech and text models to perform speech-to-text translation (ST). Our recipe to achieve cross-modal and cross-lingual transfer learning (XMTL) is simple and generalizable: using an adaptor module to bridge the modules pretrained in different modalities, and an efficient finetuning step which leverages the knowledge from pretrained modules yet making it work on a drastically different downstream task. With this approach, we built a multilingual speech-to-text translation model with pretrained audio encoder (wav2vec) and multilingual text decoder (mBART), which achieves new state-of-the-art on CoVoST 2 ST benchmark [1] for English into 15 languages as well as 6 Romance languages into English with on average +2.8 BLEU and +3.9 BLEU, respectively. On low-resource languages (with less than 10 hours training data), our approach significantly improves the quality of speech-to-text translation with +9.0 BLEU on Portuguese-English and +5.2 BLEU on Dutch-English.
Deep Transformers with Latent Depth
Oct 16, 2020


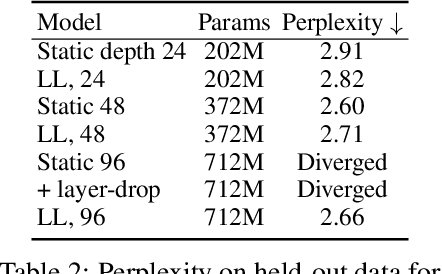
The Transformer model has achieved state-of-the-art performance in many sequence modeling tasks. However, how to leverage model capacity with large or variable depths is still an open challenge. We present a probabilistic framework to automatically learn which layer(s) to use by learning the posterior distributions of layer selection. As an extension of this framework, we propose a novel method to train one shared Transformer network for multilingual machine translation with different layer selection posteriors for each language pair. The proposed method alleviates the vanishing gradient issue and enables stable training of deep Transformers (e.g. 100 layers). We evaluate on WMT English-German machine translation and masked language modeling tasks, where our method outperforms existing approaches for training deeper Transformers. Experiments on multilingual machine translation demonstrate that this approach can effectively leverage increased model capacity and bring universal improvement for both many-to-one and one-to-many translation with diverse language pairs.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020
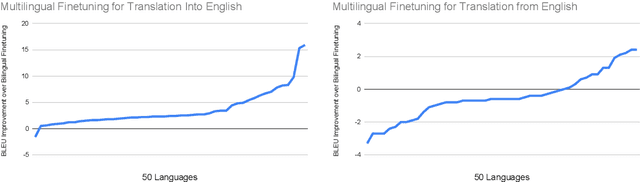
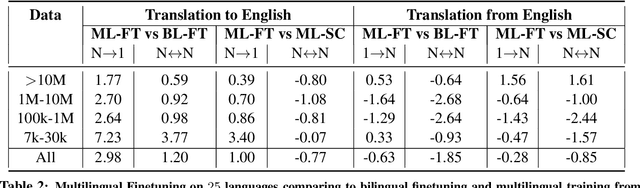

Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.