 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Transfer Learning for Multilingual Speech-to-Text Translation
Paper and Code
Oct 24, 2020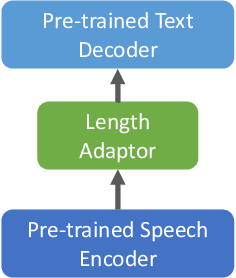
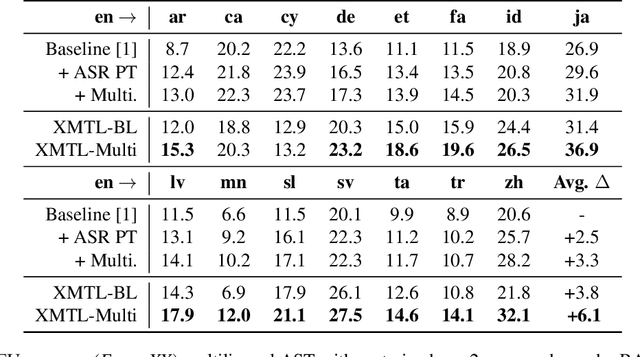
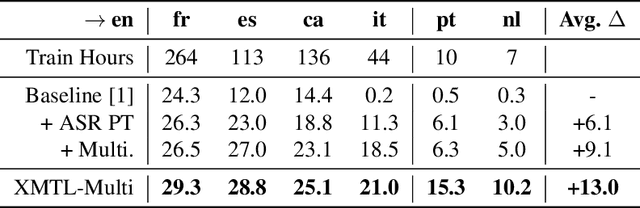

We propose an effective approach to utilize pretrained speech and text models to perform speech-to-text translation (ST). Our recipe to achieve cross-modal and cross-lingual transfer learning (XMTL) is simple and generalizable: using an adaptor module to bridge the modules pretrained in different modalities, and an efficient finetuning step which leverages the knowledge from pretrained modules yet making it work on a drastically different downstream task. With this approach, we built a multilingual speech-to-text translation model with pretrained audio encoder (wav2vec) and multilingual text decoder (mBART), which achieves new state-of-the-art on CoVoST 2 ST benchmark [1] for English into 15 languages as well as 6 Romance languages into English with on average +2.8 BLEU and +3.9 BLEU, respectively. On low-resource languages (with less than 10 hours training data), our approach significantly improves the quality of speech-to-text translation with +9.0 BLEU on Portuguese-English and +5.2 BLEU on Dutch-English.