 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Types of Convolution in Deep Convolutional Recurrent Neural Networks for Robust Speech Emotion Recognition
Paper and Code
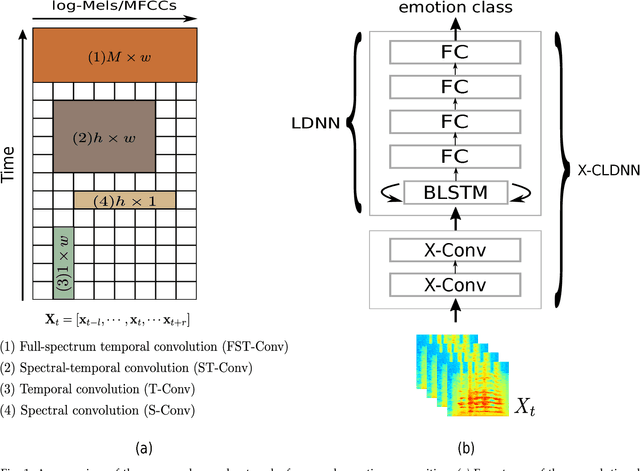

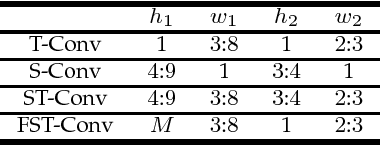
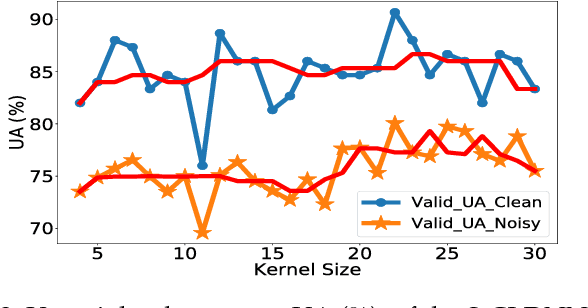
Deep convolutional neural networks are being actively investigated in a wide range of speech and audio processing applications including speech recognition, audio event detection and computational paralinguistics, owing to their ability to reduce factors of variations, for learning from speech. However, studies have suggested to favor a certain type of convolutional operations when building a deep convolutional neural network for speech applications although there has been promising results using different types of convolutional operations. In this work, we study four types of convolutional operations on different input features for speech emotion recognition under noisy and clean conditions in order to derive a comprehensive understanding. Since affective behavioral information has been shown to reflect temporally varying of mental state and convolutional operation are applied locally in time, all deep neural networks share a deep recurrent sub-network architecture for further temporal modeling. We present detailed quantitative module-wise performance analysis to gain insights into information flows within the proposed architectures. In particular, we demonstrate the interplay of affective information and the other irrelevant information during the progression from one module to another. Finally we show that all of our deep neural networks provide state-of-the-art performance on the eNTERFACE'05 corpus.