 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Parallelism Pays Off: Cohesion-Aware Task Partitioning for Multi-Agent Coding
May 31, 2026Multi-agent Large Language Model (LLM) systems offer a way to decompose complex tasks, such as coding, through parallelization and context isolation. However, adding agents in practice introduces inter-agent communication overhead, which incurs extra cost and can sometimes offset the efficiency gains. We formalize multi-agent orchestration as a graph partitioning problem that captures the communication-to-computation trade-off: task decomposition can shorten critical-path computation, but cross-agent dependencies require costly context transfer. We instantiate this view in repository-level software engineering and present Cohesion-aware Coder (Co-Coder), which builds dependency graphs from static analysis, isolates structural hub files, partitions the graph via community detection, and executes the partition with a dependency-aware scheduler. Across 28 real-world tasks on DevEval and CodeProjectEval, Co-Coder advances the Pareto-frontier over sequential and file-based parallel baselines as well as Claude Code with Agent Teams, lifting pass rate by up to 14.0%, achieving up to a 2.10x wall-clock speedup, and reducing API cost by up to 35%, with the largest gains on the most dependency-dense projects. Co-coder demonstrates how cohesion-aware orchestration can make parallel coding agents both theoretically grounded and practically efficient, suggesting a broader design principle for multi-agent systems.
Can Large Language Models Generalize Procedures Across Representations?
Feb 03, 2026Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
TCP: a Benchmark for Temporal Constraint-Based Planning
May 26, 2025Temporal reasoning and planning are essential capabilities for large language models (LLMs), yet most existing benchmarks evaluate them in isolation and under limited forms of complexity. To address this gap, we introduce the Temporal Constraint-based Planning (TCP) benchmark, that jointly assesses both capabilities. Each instance in TCP features a naturalistic dialogue around a collaborative project, where diverse and interdependent temporal constraints are explicitly or implicitly expressed, and models must infer an optimal schedule that satisfies all constraints. To construct TCP, we first generate abstract problem prototypes that are paired with realistic scenarios from various domains and enriched into dialogues using an LLM. A human quality check is performed on a sampled subset to confirm the reliability of our benchmark. We evaluate state-of-the-art LLMs and find that even the strongest models struggle with TCP, highlighting its difficulty and revealing limitations in LLMs' temporal constraint-based planning abilities. We analyze underlying failure cases, open source our benchmark, and hope our findings can inspire future research.
Code Simulation as a Proxy for High-order Tasks in Large Language Models
Feb 05, 2025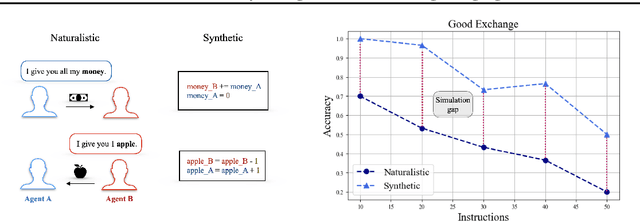


Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.
One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks
Oct 14, 2024


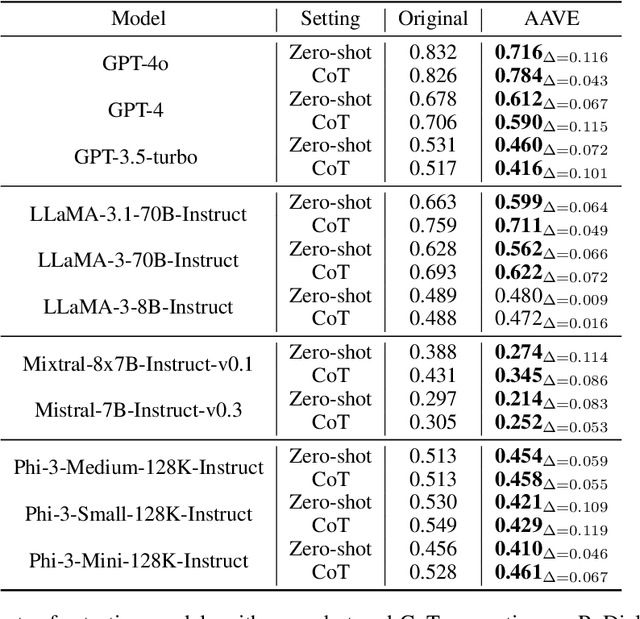
Language is not monolithic. While many benchmarks are used as proxies to systematically estimate Large Language Models' (LLM) performance in real-life tasks, they tend to ignore the nuances of within-language variation and thus fail to model the experience of speakers of minority dialects. Focusing on African American Vernacular English (AAVE), we present the first study on LLMs' fairness and robustness to a dialect in canonical reasoning tasks (algorithm, math, logic, and comprehensive reasoning). We hire AAVE speakers, including experts with computer science backgrounds, to rewrite seven popular benchmarks, such as HumanEval and GSM8K. The result of this effort is ReDial, a dialectal benchmark comprising $1.2K+$ parallel query pairs in Standardized English and AAVE. We use ReDial to evaluate state-of-the-art LLMs, including GPT-4o/4/3.5-turbo, LLaMA-3.1/3, Mistral, and Phi-3. We find that, compared to Standardized English, almost all of these widely used models show significant brittleness and unfairness to queries in AAVE. Furthermore, AAVE queries can degrade performance more substantially than misspelled texts in Standardized English, even when LLMs are more familiar with the AAVE queries. Finally, asking models to rephrase questions in Standardized English does not close the performance gap but generally introduces higher costs. Overall, our findings indicate that LLMs provide unfair service to dialect users in complex reasoning tasks. Code can be found at https://github.com/fangru-lin/redial_dialect_robustness_fairness.git.
Probing Large Language Models for Scalar Adjective Lexical Semantics and Scalar Diversity Pragmatics
Apr 04, 2024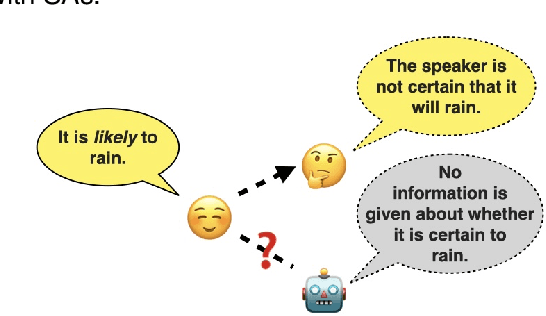

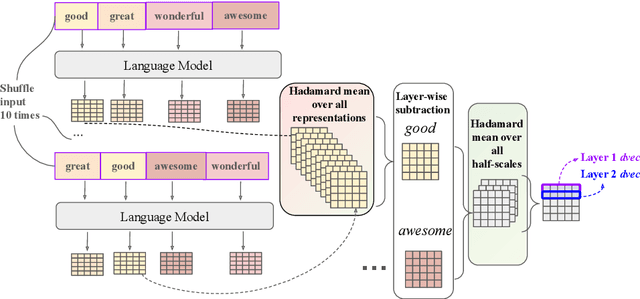
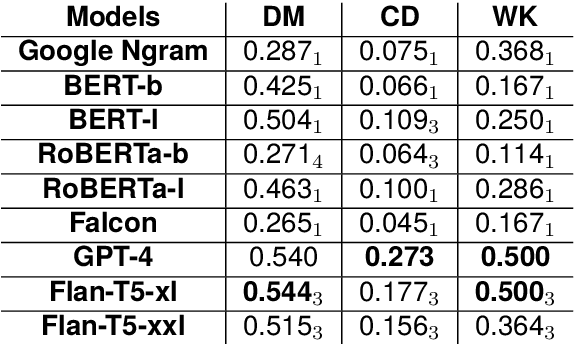
Scalar adjectives pertain to various domain scales and vary in intensity within each scale (e.g. certain is more intense than likely on the likelihood scale). Scalar implicatures arise from the consideration of alternative statements which could have been made. They can be triggered by scalar adjectives and require listeners to reason pragmatically about them. Some scalar adjectives are more likely to trigger scalar implicatures than others. This phenomenon is referred to as scalar diversity. In this study, we probe different families of Large Language Models such as GPT-4 for their knowledge of the lexical semantics of scalar adjectives and one specific aspect of their pragmatics, namely scalar diversity. We find that they encode rich lexical-semantic information about scalar adjectives. However, the rich lexical-semantic knowledge does not entail a good understanding of scalar diversity. We also compare current models of different sizes and complexities and find that larger models are not always better. Finally, we explain our probing results by leveraging linguistic intuitions and model training objectives.
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
Feb 05, 2024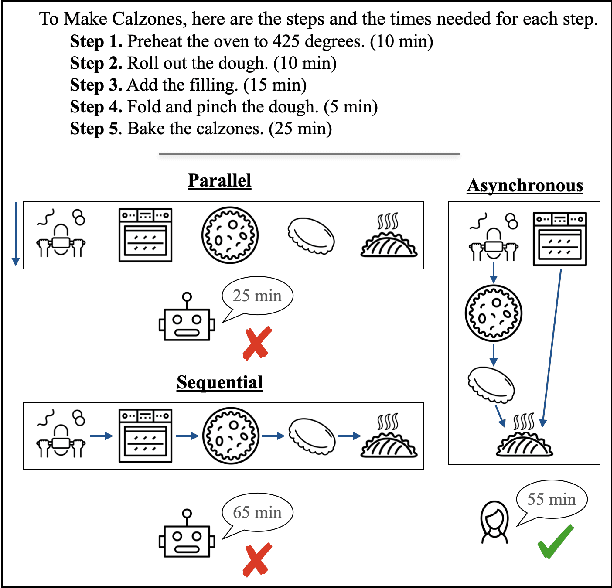



Reasoning about asynchronous plans is challenging since it requires sequential and parallel planning to optimize time costs. Can large language models (LLMs) succeed at this task? Here, we present the first large-scale study investigating this question. We find that a representative set of closed and open-source LLMs, including GPT-4 and LLaMA-2, behave poorly when not supplied with illustrations about the task-solving process in our benchmark AsyncHow. We propose a novel technique called Plan Like a Graph (PLaG) that combines graphs with natural language prompts and achieves state-of-the-art results. We show that although PLaG can boost model performance, LLMs still suffer from drastic degradation when task complexity increases, highlighting the limits of utilizing LLMs for simulating digital devices. We see our study as an exciting step towards using LLMs as efficient autonomous agents.
Code Simulation Challenges for Large Language Models
Jan 21, 2024



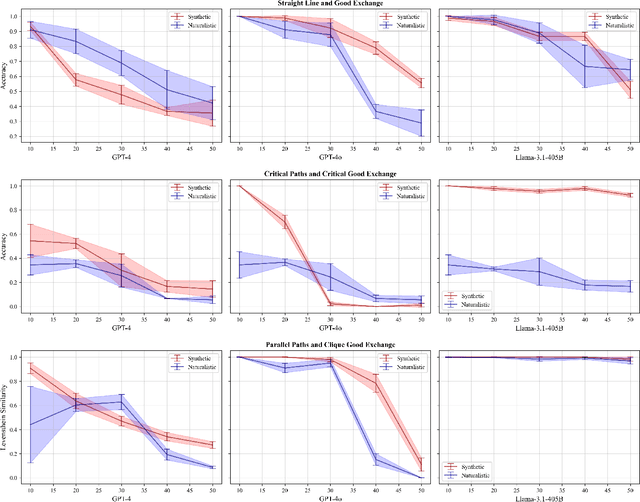
We investigate the extent to which Large Language Models (LLMs) can simulate the execution of computer code and algorithms. We begin by looking at straight line programs, and show that current LLMs demonstrate poor performance even with such simple programs -- performance rapidly degrades with the length of code. We then investigate the ability of LLMs to simulate programs that contain critical paths and redundant instructions. We also go beyond straight line program simulation with sorting algorithms and nested loops, and we show the computational complexity of a routine directly affects the ability of an LLM to simulate its execution. We observe that LLMs execute instructions sequentially and with a low error margin only for short programs or standard procedures. LLMs' code simulation is in tension with their pattern recognition and memorisation capabilities: on tasks where memorisation is detrimental, we propose a novel prompting method to simulate code execution line by line. Empirically, our new Chain of Simulation (CoSm) method improves on the standard Chain of Thought prompting approach by avoiding the pitfalls of memorisation.