 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Generalize Procedures Across Representations?
Feb 03, 2026Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts
Jun 11, 2025Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
Stories that (are) Move(d by) Markets: A Causal Exploration of Market Shocks and Semantic Shifts across Different Partisan Groups
Feb 20, 2025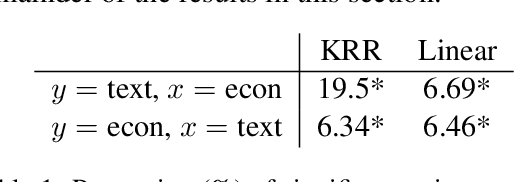
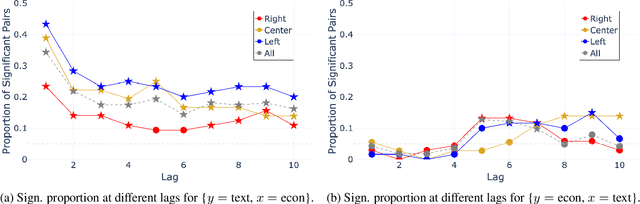
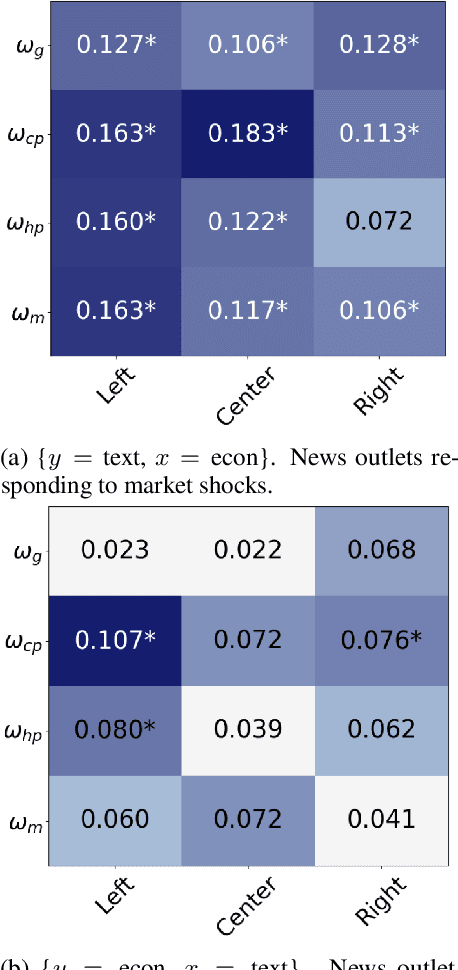
Macroeconomic fluctuations and the narratives that shape them form a mutually reinforcing cycle: public discourse can spur behavioural changes leading to economic shifts, which then result in changes in the stories that propagate. We show that shifts in semantic embedding space can be causally linked to financial market shocks -- deviations from the expected market behaviour. Furthermore, we show how partisanship can influence the predictive power of text for market fluctuations and shape reactions to those same shocks. We also provide some evidence that text-based signals are particularly salient during unexpected events such as COVID-19, highlighting the value of language data as an exogenous variable in economic forecasting. Our findings underscore the bidirectional relationship between news outlets and market shocks, offering a novel empirical approach to studying their effect on each other.
When Dimensionality Hurts: The Role of LLM Embedding Compression for Noisy Regression Tasks
Feb 04, 2025



Large language models (LLMs) have shown remarkable success in language modelling due to scaling laws found in model size and the hidden dimension of the model's text representation. Yet, we demonstrate that compressed representations of text can yield better performance in LLM-based regression tasks. In this paper, we compare the relative performance of embedding compression in three different signal-to-noise contexts: financial return prediction, writing quality assessment and review scoring. Our results show that compressing embeddings, in a minimally supervised manner using an autoencoder's hidden representation, can mitigate overfitting and improve performance on noisy tasks, such as financial return prediction; but that compression reduces performance on tasks that have high causal dependencies between the input and target data. Our results suggest that the success of interpretable compressed representations such as sentiment may be due to a regularising effect.
Traditional Methods Outperform Generative LLMs at Forecasting Credit Ratings
Jul 24, 2024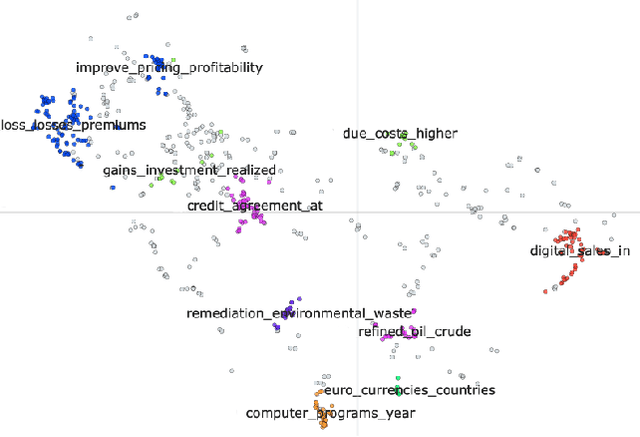
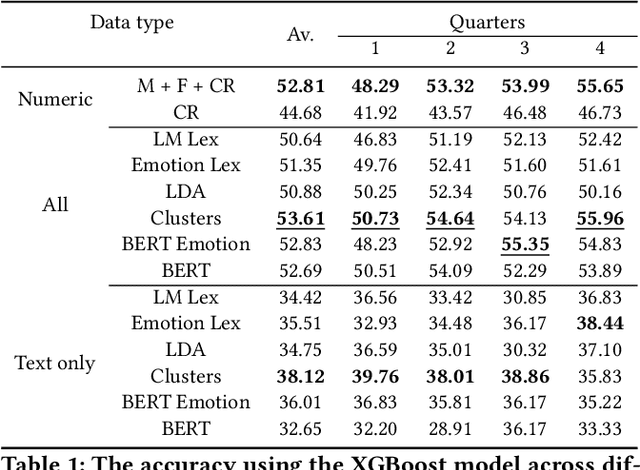
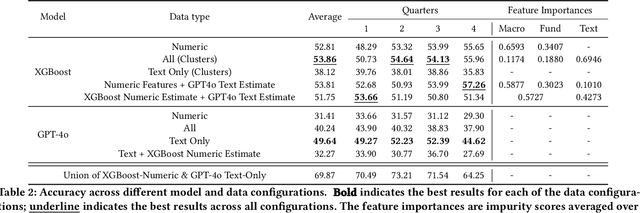
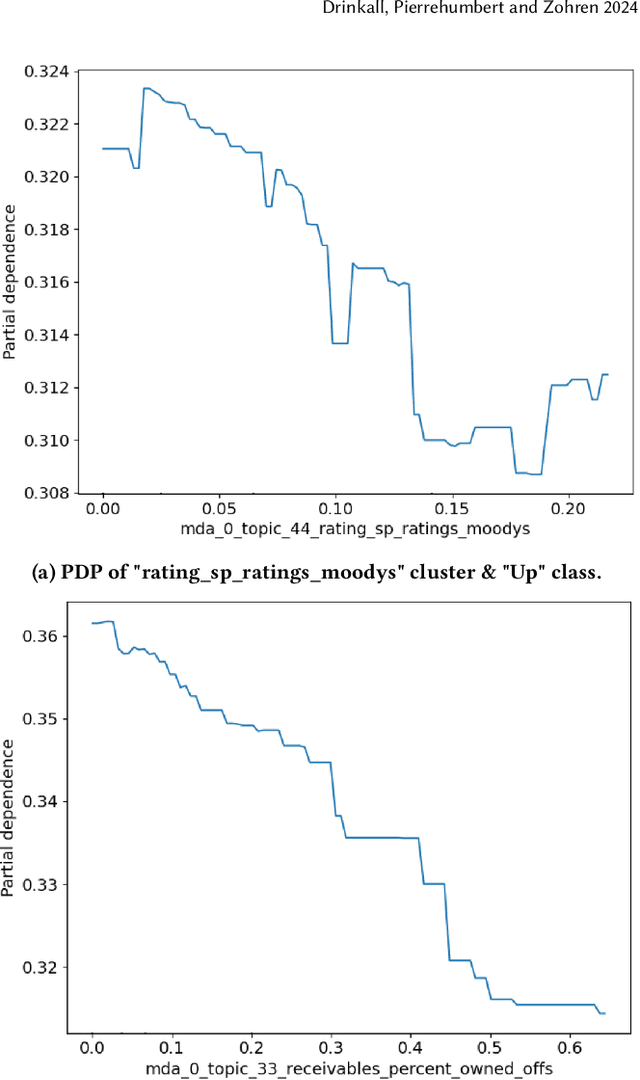
Large Language Models (LLMs) have been shown to perform well for many downstream tasks. Transfer learning can enable LLMs to acquire skills that were not targeted during pre-training. In financial contexts, LLMs can sometimes beat well-established benchmarks. This paper investigates how well LLMs perform in the task of forecasting corporate credit ratings. We show that while LLMs are very good at encoding textual information, traditional methods are still very competitive when it comes to encoding numeric and multimodal data. For our task, current LLMs perform worse than a more traditional XGBoost architecture that combines fundamental and macroeconomic data with high-density text-based embedding features.
Decoding Climate Disagreement: A Graph Neural Network-Based Approach to Understanding Social Media Dynamics
Jul 09, 2024This work introduces the ClimateSent-GAT Model, an innovative method that integrates Graph Attention Networks (GATs) with techniques from natural language processing to accurately identify and predict disagreements within Reddit comment-reply pairs. Our model classifies disagreements into three categories: agree, disagree, and neutral. Leveraging the inherent graph structure of Reddit comment-reply pairs, the model significantly outperforms existing benchmarks by capturing complex interaction patterns and sentiment dynamics. This research advances graph-based NLP methodologies and provides actionable insights for policymakers and educators in climate science communication.
Time Machine GPT
Apr 29, 2024



Large language models (LLMs) are often trained on extensive, temporally indiscriminate text corpora, reflecting the lack of datasets with temporal metadata. This approach is not aligned with the evolving nature of language. Conventional methods for creating temporally adapted language models often depend on further pre-training static models on time-specific data. This paper presents a new approach: a series of point-in-time LLMs called Time Machine GPT (TiMaGPT), specifically designed to be nonprognosticative. This ensures they remain uninformed about future factual information and linguistic changes. This strategy is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. We provide access to both the models and training datasets.
Probing Large Language Models for Scalar Adjective Lexical Semantics and Scalar Diversity Pragmatics
Apr 04, 2024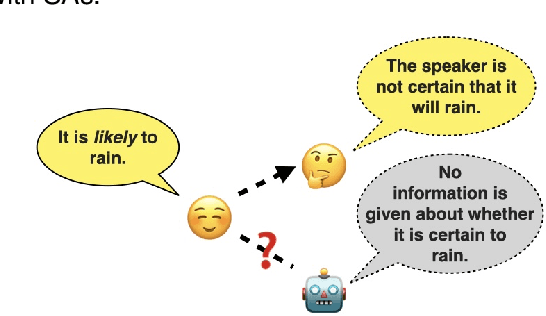

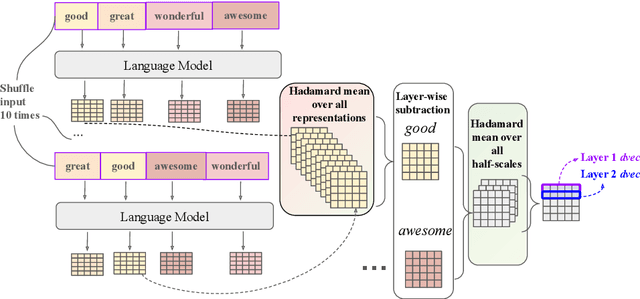
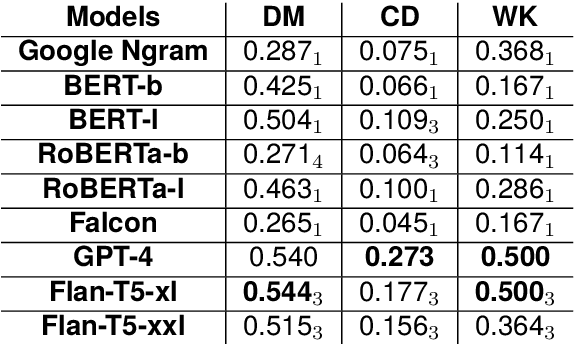
Scalar adjectives pertain to various domain scales and vary in intensity within each scale (e.g. certain is more intense than likely on the likelihood scale). Scalar implicatures arise from the consideration of alternative statements which could have been made. They can be triggered by scalar adjectives and require listeners to reason pragmatically about them. Some scalar adjectives are more likely to trigger scalar implicatures than others. This phenomenon is referred to as scalar diversity. In this study, we probe different families of Large Language Models such as GPT-4 for their knowledge of the lexical semantics of scalar adjectives and one specific aspect of their pragmatics, namely scalar diversity. We find that they encode rich lexical-semantic information about scalar adjectives. However, the rich lexical-semantic knowledge does not entail a good understanding of scalar diversity. We also compare current models of different sizes and complexities and find that larger models are not always better. Finally, we explain our probing results by leveraging linguistic intuitions and model training objectives.
STEntConv: Predicting Disagreement with Stance Detection and a Signed Graph Convolutional Network
Mar 26, 2024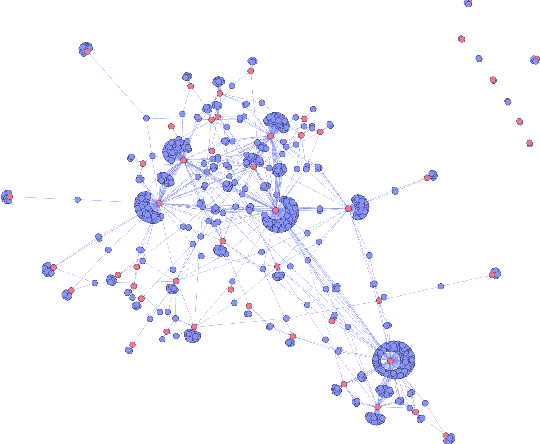
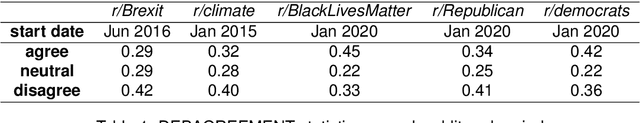

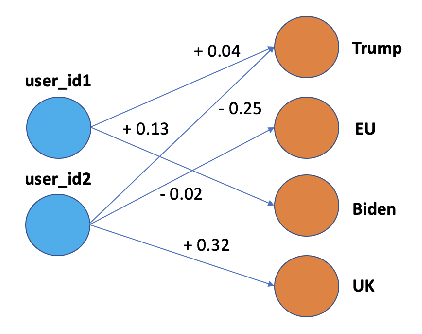
The rise of social media platforms has led to an increase in polarised online discussions, especially on political and socio-cultural topics such as elections and climate change. We propose a simple and novel unsupervised method to predict whether the authors of two posts agree or disagree, leveraging user stances about named entities obtained from their posts. We present STEntConv, a model which builds a graph of users and named entities weighted by stance and trains a Signed Graph Convolutional Network (SGCN) to detect disagreement between comment and reply posts. We run experiments and ablation studies and show that including this information improves disagreement detection performance on a dataset of Reddit posts for a range of controversial subreddit topics, without the need for platform-specific features or user history.
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
Feb 05, 2024Reasoning about asynchronous plans is challenging since it requires sequential and parallel planning to optimize time costs. Can large language models (LLMs) succeed at this task? Here, we present the first large-scale study investigating this question. We find that a representative set of closed and open-source LLMs, including GPT-4 and LLaMA-2, behave poorly when not supplied with illustrations about the task-solving process in our benchmark AsyncHow. We propose a novel technique called Plan Like a Graph (PLaG) that combines graphs with natural language prompts and achieves state-of-the-art results. We show that although PLaG can boost model performance, LLMs still suffer from drastic degradation when task complexity increases, highlighting the limits of utilizing LLMs for simulating digital devices. We see our study as an exciting step towards using LLMs as efficient autonomous agents.