 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStories that (are) Move(d by) Markets: A Causal Exploration of Market Shocks and Semantic Shifts across Different Partisan Groups
Feb 20, 2025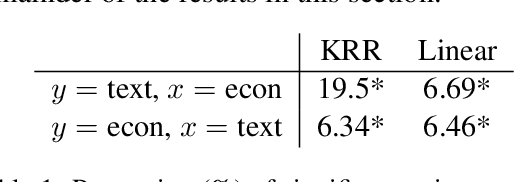
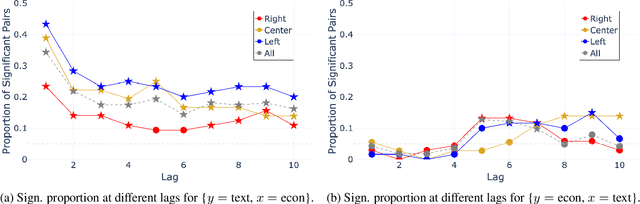
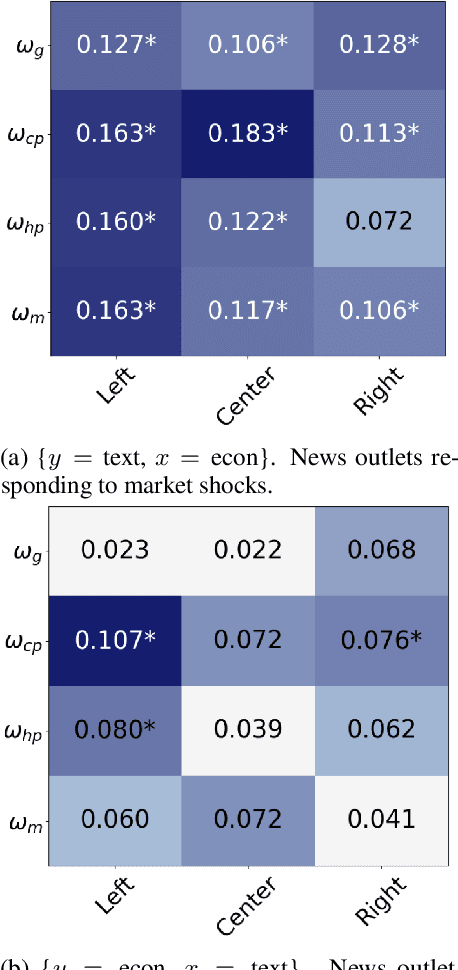
Macroeconomic fluctuations and the narratives that shape them form a mutually reinforcing cycle: public discourse can spur behavioural changes leading to economic shifts, which then result in changes in the stories that propagate. We show that shifts in semantic embedding space can be causally linked to financial market shocks -- deviations from the expected market behaviour. Furthermore, we show how partisanship can influence the predictive power of text for market fluctuations and shape reactions to those same shocks. We also provide some evidence that text-based signals are particularly salient during unexpected events such as COVID-19, highlighting the value of language data as an exogenous variable in economic forecasting. Our findings underscore the bidirectional relationship between news outlets and market shocks, offering a novel empirical approach to studying their effect on each other.
When Dimensionality Hurts: The Role of LLM Embedding Compression for Noisy Regression Tasks
Feb 04, 2025



Large language models (LLMs) have shown remarkable success in language modelling due to scaling laws found in model size and the hidden dimension of the model's text representation. Yet, we demonstrate that compressed representations of text can yield better performance in LLM-based regression tasks. In this paper, we compare the relative performance of embedding compression in three different signal-to-noise contexts: financial return prediction, writing quality assessment and review scoring. Our results show that compressing embeddings, in a minimally supervised manner using an autoencoder's hidden representation, can mitigate overfitting and improve performance on noisy tasks, such as financial return prediction; but that compression reduces performance on tasks that have high causal dependencies between the input and target data. Our results suggest that the success of interpretable compressed representations such as sentiment may be due to a regularising effect.
Jailbreaking Large Language Models in Infinitely Many Ways
Jan 18, 2025



We discuss the "Infinitely Many Meanings" attacks (IMM), a category of jailbreaks that leverages the increasing capabilities of a model to handle paraphrases and encoded communications to bypass their defensive mechanisms. IMMs' viability pairs and grows with a model's capabilities to handle and bind the semantics of simple mappings between tokens and work extremely well in practice, posing a concrete threat to the users of the most powerful LLMs in commerce. We show how one can bypass the safeguards of the most powerful open- and closed-source LLMs and generate content that explicitly violates their safety policies. One can protect against IMMs by improving the guardrails and making them scale with the LLMs' capabilities. For two categories of attacks that are straightforward to implement, i.e., bijection and encoding, we discuss two defensive strategies, one in token and the other in embedding space. We conclude with some research questions we believe should be prioritised to enhance the defensive mechanisms of LLMs and our understanding of their safety.
Traditional Methods Outperform Generative LLMs at Forecasting Credit Ratings
Jul 24, 2024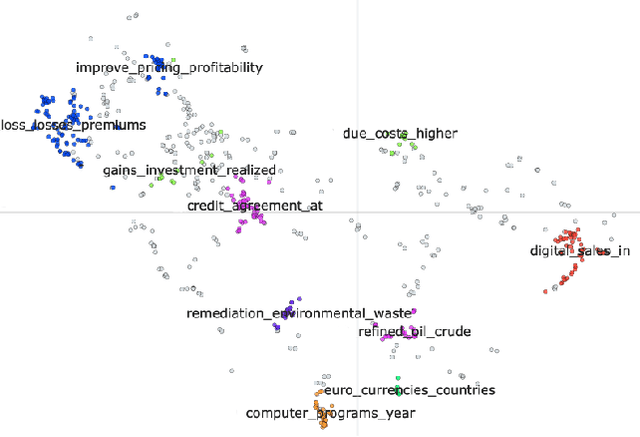
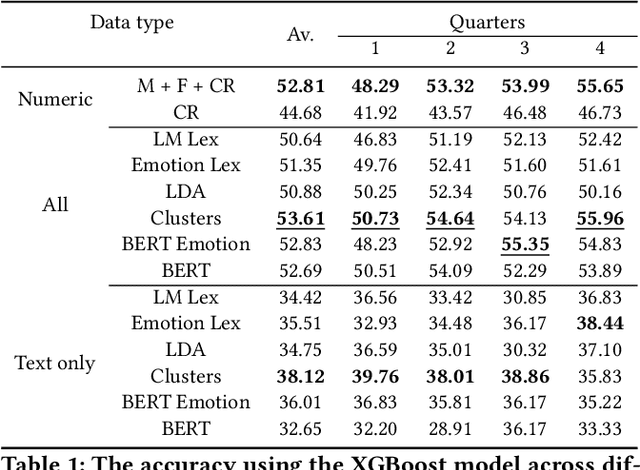
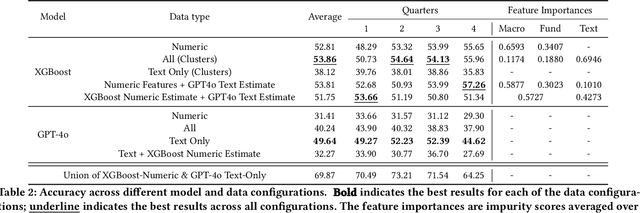
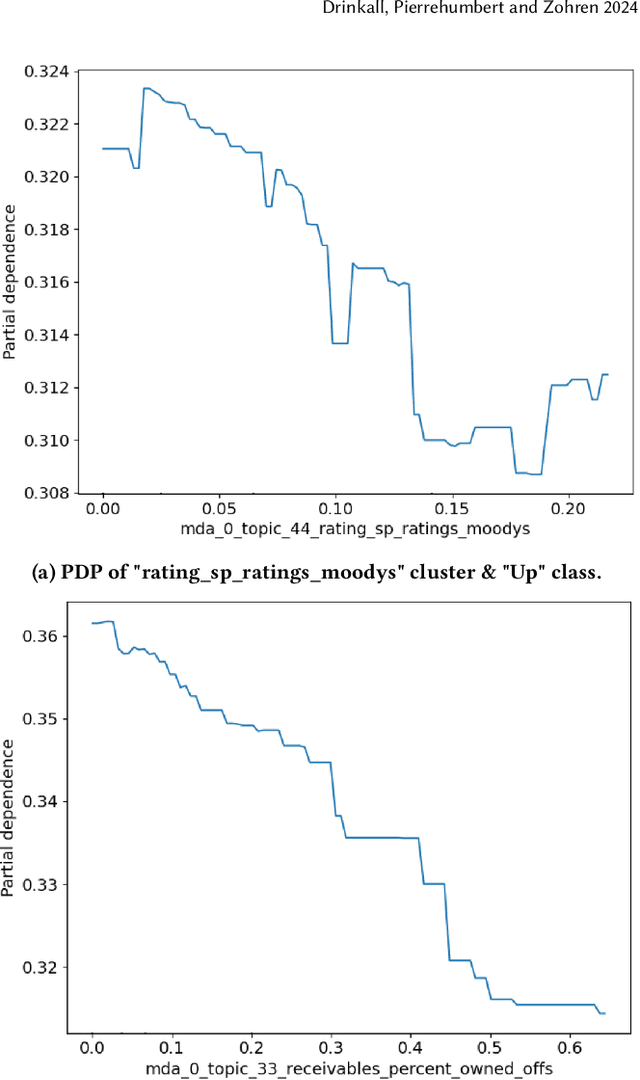
Large Language Models (LLMs) have been shown to perform well for many downstream tasks. Transfer learning can enable LLMs to acquire skills that were not targeted during pre-training. In financial contexts, LLMs can sometimes beat well-established benchmarks. This paper investigates how well LLMs perform in the task of forecasting corporate credit ratings. We show that while LLMs are very good at encoding textual information, traditional methods are still very competitive when it comes to encoding numeric and multimodal data. For our task, current LLMs perform worse than a more traditional XGBoost architecture that combines fundamental and macroeconomic data with high-density text-based embedding features.
Time Machine GPT
Apr 29, 2024



Large language models (LLMs) are often trained on extensive, temporally indiscriminate text corpora, reflecting the lack of datasets with temporal metadata. This approach is not aligned with the evolving nature of language. Conventional methods for creating temporally adapted language models often depend on further pre-training static models on time-specific data. This paper presents a new approach: a series of point-in-time LLMs called Time Machine GPT (TiMaGPT), specifically designed to be nonprognosticative. This ensures they remain uninformed about future factual information and linguistic changes. This strategy is beneficial for understanding language evolution and is of critical importance when applying models in dynamic contexts, such as time-series forecasting, where foresight of future information can prove problematic. We provide access to both the models and training datasets.
Forecasting COVID-19 Caseloads Using Unsupervised Embedding Clusters of Social Media Posts
May 20, 2022
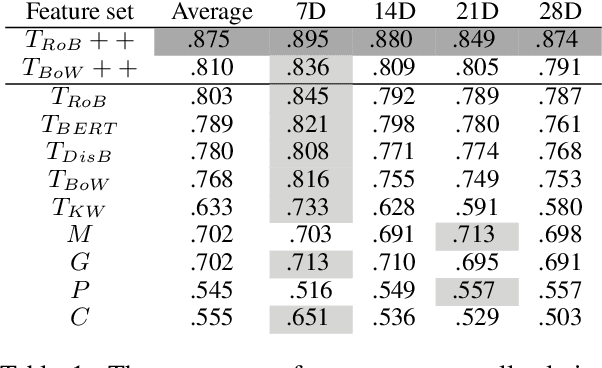
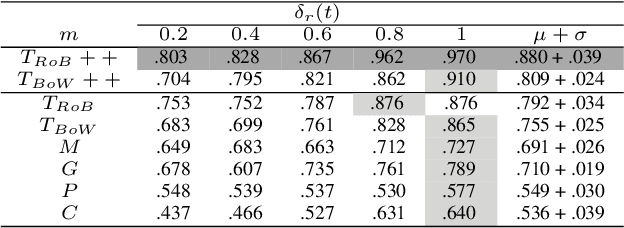

We present a novel approach incorporating transformer-based language models into infectious disease modelling. Text-derived features are quantified by tracking high-density clusters of sentence-level representations of Reddit posts within specific US states' COVID-19 subreddits. We benchmark these clustered embedding features against features extracted from other high-quality datasets. In a threshold-classification task, we show that they outperform all other feature types at predicting upward trend signals, a significant result for infectious disease modelling in areas where epidemiological data is unreliable. Subsequently, in a time-series forecasting task we fully utilise the predictive power of the caseload and compare the relative strengths of using different supplementary datasets as covariate feature sets in a transformer-based time-series model.