 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular representation learning with language models and domain-relevant auxiliary tasks
Nov 26, 2020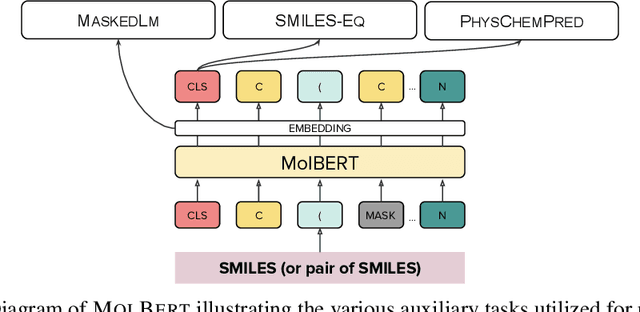

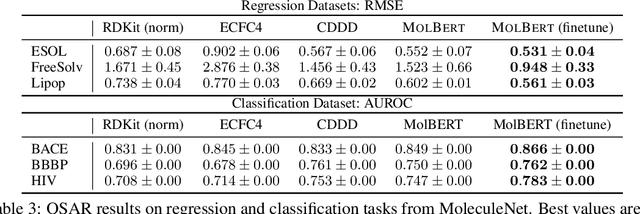
We apply a Transformer architecture, specifically BERT, to learn flexible and high quality molecular representations for drug discovery problems. We study the impact of using different combinations of self-supervised tasks for pre-training, and present our results for the established Virtual Screening and QSAR benchmarks. We show that: i) The selection of appropriate self-supervised task(s) for pre-training has a significant impact on performance in subsequent downstream tasks such as Virtual Screening. ii) Using auxiliary tasks with more domain relevance for Chemistry, such as learning to predict calculated molecular properties, increases the fidelity of our learnt representations. iii) Finally, we show that molecular representations learnt by our model `MolBert' improve upon the current state of the art on the benchmark datasets.
Synthesizing Property & Casualty Ratemaking Datasets using Generative Adversarial Networks
Aug 13, 2020Due to confidentiality issues, it can be difficult to access or share interesting datasets for methodological development in actuarial science, or other fields where personal data are important. We show how to design three different types of generative adversarial networks (GANs) that can build a synthetic insurance dataset from a confidential original dataset. The goal is to obtain synthetic data that no longer contains sensitive information but still has the same structure as the original dataset and retains the multivariate relationships. In order to adequately model the specific characteristics of insurance data, we use GAN architectures adapted for multi-categorical data: a Wassertein GAN with gradient penalty (MC-WGAN-GP), a conditional tabular GAN (CTGAN) and a Mixed Numerical and Categorical Differentially Private GAN (MNCDP-GAN). For transparency, the approaches are illustrated using a public dataset, the French motor third party liability data. We compare the three different GANs on various aspects: ability to reproduce the original data structure and predictive models, privacy, and ease of use. We find that the MC-WGAN-GP synthesizes the best data, the CTGAN is the easiest to use, and the MNCDP-GAN guarantees differential privacy.