 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiMixQA: A Multimodal Benchmark for Question Answering over Tables and Charts
Jun 18, 2025Documents are fundamental to preserving and disseminating information, often incorporating complex layouts, tables, and charts that pose significant challenges for automatic document understanding (DU). While vision-language large models (VLLMs) have demonstrated improvements across various tasks, their effectiveness in processing long-context vision inputs remains unclear. This paper introduces WikiMixQA, a benchmark comprising 1,000 multiple-choice questions (MCQs) designed to evaluate cross-modal reasoning over tables and charts extracted from 4,000 Wikipedia pages spanning seven distinct topics. Unlike existing benchmarks, WikiMixQA emphasizes complex reasoning by requiring models to synthesize information from multiple modalities. We evaluate 12 state-of-the-art vision-language models, revealing that while proprietary models achieve ~70% accuracy when provided with direct context, their performance deteriorates significantly when retrieval from long documents is required. Among these, GPT-4-o is the only model exceeding 50% accuracy in this setting, whereas open-source models perform considerably worse, with a maximum accuracy of 27%. These findings underscore the challenges of long-context, multi-modal reasoning and establish WikiMixQA as a crucial benchmark for advancing document understanding research.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Fast-FedUL: A Training-Free Federated Unlearning with Provable Skew Resilience
May 28, 2024Federated learning (FL) has recently emerged as a compelling machine learning paradigm, prioritizing the protection of privacy for training data. The increasing demand to address issues such as ``the right to be forgotten'' and combat data poisoning attacks highlights the importance of techniques, known as \textit{unlearning}, which facilitate the removal of specific training data from trained FL models. Despite numerous unlearning methods proposed for centralized learning, they often prove inapplicable to FL due to fundamental differences in the operation of the two learning paradigms. Consequently, unlearning in FL remains in its early stages, presenting several challenges. Many existing unlearning solutions in FL require a costly retraining process, which can be burdensome for clients. Moreover, these methods are primarily validated through experiments, lacking theoretical assurances. In this study, we introduce Fast-FedUL, a tailored unlearning method for FL, which eliminates the need for retraining entirely. Through meticulous analysis of the target client's influence on the global model in each round, we develop an algorithm to systematically remove the impact of the target client from the trained model. In addition to presenting empirical findings, we offer a theoretical analysis delineating the upper bound of our unlearned model and the exact retrained model (the one obtained through retraining using untargeted clients). Experimental results with backdoor attack scenarios indicate that Fast-FedUL effectively removes almost all traces of the target client, while retaining the knowledge of untargeted clients (obtaining a high accuracy of up to 98\% on the main task). Significantly, Fast-FedUL attains the lowest time complexity, providing a speed that is 1000 times faster than retraining. Our source code is publicly available at \url{https://github.com/thanhtrunghuynh93/fastFedUL}.
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
May 27, 2024The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
Stance Detection on Social Media with Fine-Tuned Large Language Models
Apr 18, 2024



Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
CRAB: Assessing the Strength of Causal Relationships Between Real-world Events
Nov 07, 2023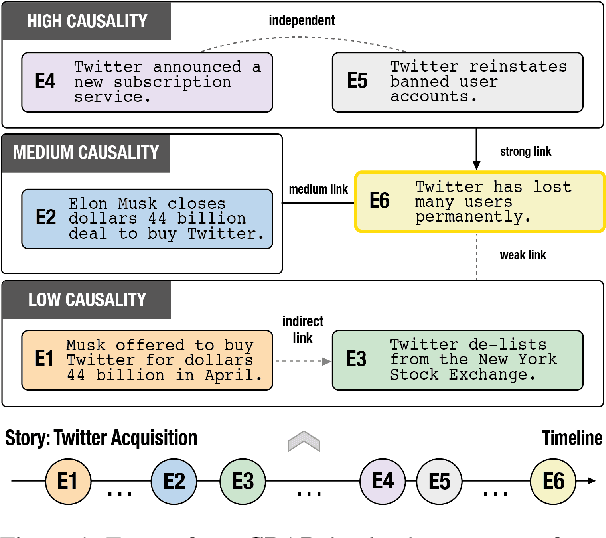
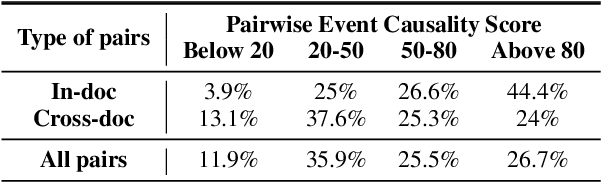
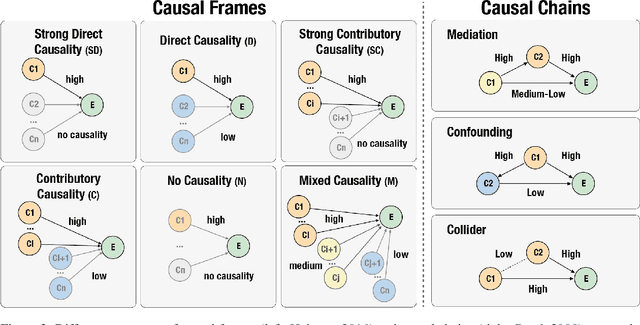
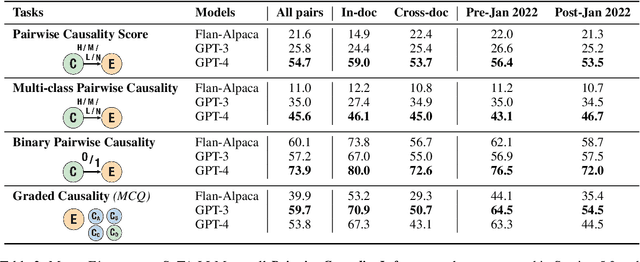
Understanding narratives requires reasoning about the cause-and-effect relationships between events mentioned in the text. While existing foundation models yield impressive results in many NLP tasks requiring reasoning, it is unclear whether they understand the complexity of the underlying network of causal relationships of events in narratives. In this work, we present CRAB, a new Causal Reasoning Assessment Benchmark designed to evaluate causal understanding of events in real-world narratives. CRAB contains fine-grained, contextual causality annotations for ~2.7K pairs of real-world events that describe various newsworthy event timelines (e.g., the acquisition of Twitter by Elon Musk). Using CRAB, we measure the performance of several large language models, demonstrating that most systems achieve poor performance on the task. Motivated by classical causal principles, we also analyze the causal structures of groups of events in CRAB, and find that models perform worse on causal reasoning when events are derived from complex causal structures compared to simple linear causal chains. We make our dataset and code available to the research community.
Breaking the Language Barrier: Improving Cross-Lingual Reasoning with Structured Self-Attention
Oct 23, 2023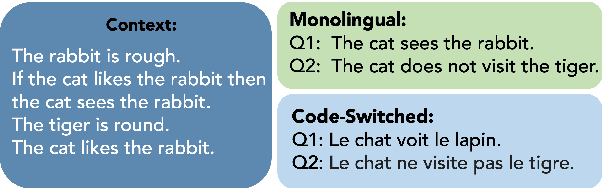
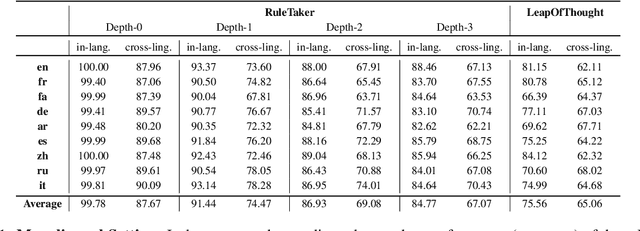
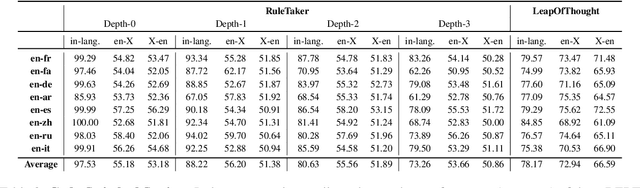

In this work, we study whether multilingual language models (MultiLMs) can transfer logical reasoning abilities to other languages when they are fine-tuned for reasoning in a different language. We evaluate the cross-lingual reasoning abilities of MultiLMs in two schemes: (1) where the language of the context and the question remain the same in the new languages that are tested (i.e., the reasoning is still monolingual, but the model must transfer the learned reasoning ability across languages), and (2) where the language of the context and the question is different (which we term code-switched reasoning). On two logical reasoning datasets, RuleTaker and LeapOfThought, we demonstrate that although MultiLMs can transfer reasoning ability across languages in a monolingual setting, they struggle to transfer reasoning abilities in a code-switched setting. Following this observation, we propose a novel attention mechanism that uses a dedicated set of parameters to encourage cross-lingual attention in code-switched sequences, which improves the reasoning performance by up to 14% and 4% on the RuleTaker and LeapOfThought datasets, respectively.
Stop Pre-Training: Adapt Visual-Language Models to Unseen Languages
Jun 29, 2023



Vision-Language Pre-training (VLP) has advanced the performance of many vision-language tasks, such as image-text retrieval, visual entailment, and visual reasoning. The pre-training mostly utilizes lexical databases and image queries in English. Previous work has demonstrated that the pre-training in English does not transfer well to other languages in a zero-shot setting. However, multilingual pre-trained language models (MPLM) have excelled at a variety of single-modal language tasks. In this paper, we propose a simple yet efficient approach to adapt VLP to unseen languages using MPLM. We utilize a cross-lingual contextualized token embeddings alignment approach to train text encoders for non-English languages. Our approach does not require image input and primarily uses machine translation, eliminating the need for target language data. Our evaluation across three distinct tasks (image-text retrieval, visual entailment, and natural language visual reasoning) demonstrates that this approach outperforms the state-of-the-art multilingual vision-language models without requiring large parallel corpora. Our code is available at https://github.com/Yasminekaroui/CliCoTea.
Revisiting Offline Compression: Going Beyond Factorization-based Methods for Transformer Language Models
Feb 08, 2023Recent transformer language models achieve outstanding results in many natural language processing (NLP) tasks. However, their enormous size often makes them impractical on memory-constrained devices, requiring practitioners to compress them to smaller networks. In this paper, we explore offline compression methods, meaning computationally-cheap approaches that do not require further fine-tuning of the compressed model. We challenge the classical matrix factorization methods by proposing a novel, better-performing autoencoder-based framework. We perform a comprehensive ablation study of our approach, examining its different aspects over a diverse set of evaluation settings. Moreover, we show that enabling collaboration between modules across layers by compressing certain modules together positively impacts the final model performance. Experiments on various NLP tasks demonstrate that our approach significantly outperforms commonly used factorization-based offline compression methods.
Beyond S-curves: Recurrent Neural Networks for Technology Forecasting
Nov 28, 2022



Because of the considerable heterogeneity and complexity of the technological landscape, building accurate models to forecast is a challenging endeavor. Due to their high prevalence in many complex systems, S-curves are a popular forecasting approach in previous work. However, their forecasting performance has not been directly compared to other technology forecasting approaches. Additionally, recent developments in time series forecasting that claim to improve forecasting accuracy are yet to be applied to technological development data. This work addresses both research gaps by comparing the forecasting performance of S-curves to a baseline and by developing an autencoder approach that employs recent advances in machine learning and time series forecasting. S-curves forecasts largely exhibit a mean average percentage error (MAPE) comparable to a simple ARIMA baseline. However, for a minority of emerging technologies, the MAPE increases by two magnitudes. Our autoencoder approach improves the MAPE by 13.5% on average over the second-best result. It forecasts established technologies with the same accuracy as the other approaches. However, it is especially strong at forecasting emerging technologies with a mean MAPE 18% lower than the next best result. Our results imply that a simple ARIMA model is preferable over the S-curve for technology forecasting. Practitioners looking for more accurate forecasts should opt for the presented autoencoder approach.