 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Data Contamination in LLMs via In-Context Learning
Oct 30, 2025We present Contamination Detection via Context (CoDeC), a practical and accurate method to detect and quantify training data contamination in large language models. CoDeC distinguishes between data memorized during training and data outside the training distribution by measuring how in-context learning affects model performance. We find that in-context examples typically boost confidence for unseen datasets but may reduce it when the dataset was part of training, due to disrupted memorization patterns. Experiments show that CoDeC produces interpretable contamination scores that clearly separate seen and unseen datasets, and reveals strong evidence of memorization in open-weight models with undisclosed training corpora. The method is simple, automated, and both model- and dataset-agnostic, making it easy to integrate with benchmark evaluations.
Minimal Ranks, Maximum Confidence: Parameter-efficient Uncertainty Quantification for LoRA
Feb 17, 2025Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of large language models by decomposing weight updates into low-rank matrices, significantly reducing storage and computational overhead. While effective, standard LoRA lacks mechanisms for uncertainty quantification, leading to overconfident and poorly calibrated models. Bayesian variants of LoRA address this limitation, but at the cost of a significantly increased number of trainable parameters, partially offsetting the original efficiency gains. Additionally, these models are harder to train and may suffer from unstable convergence. In this work, we propose a novel parameter-efficient Bayesian LoRA, demonstrating that effective uncertainty quantification can be achieved in very low-dimensional parameter spaces. The proposed method achieves strong performance with improved calibration and generalization while maintaining computational efficiency. Our empirical findings show that, with the appropriate projection of the weight space: (1) uncertainty can be effectively modeled in a low-dimensional space, and (2) weight covariances exhibit low ranks.
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
May 27, 2024The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
Exploiting Transformer Activation Sparsity with Dynamic Inference
Oct 06, 2023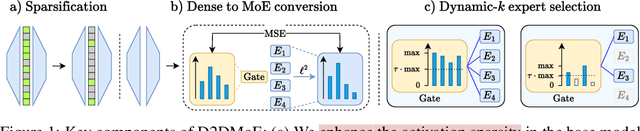
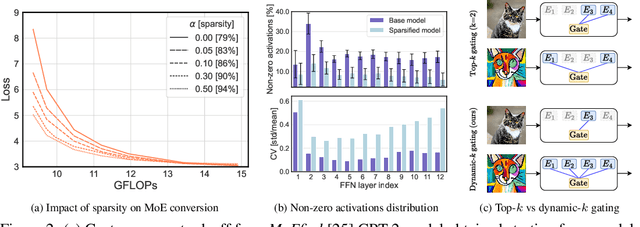
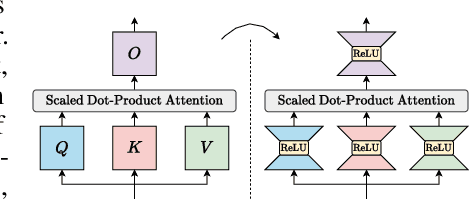
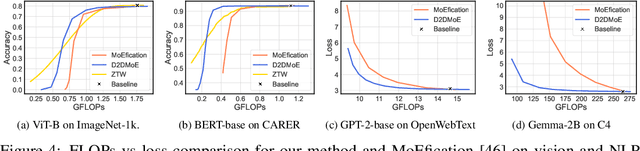
Transformer models, despite their impressive performance, often face practical limitations due to their high computational requirements. At the same time, previous studies have revealed significant activation sparsity in these models, indicating the presence of redundant computations. In this paper, we propose Dynamic Sparsified Transformer Inference (DSTI), a method that radically reduces the inference cost of Transformer models by enforcing activation sparsity and subsequently transforming a dense model into its sparse Mixture of Experts (MoE) version. We demonstrate that it is possible to train small gating networks that successfully predict the relative contribution of each expert during inference. Furthermore, we introduce a mechanism that dynamically determines the number of executed experts individually for each token. DSTI can be applied to any Transformer-based architecture and has negligible impact on the accuracy. For the BERT-base classification model, we reduce inference cost by almost 60%.
r-softmax: Generalized Softmax with Controllable Sparsity Rate
Apr 21, 2023



Nowadays artificial neural network models achieve remarkable results in many disciplines. Functions mapping the representation provided by the model to the probability distribution are the inseparable aspect of deep learning solutions. Although softmax is a commonly accepted probability mapping function in the machine learning community, it cannot return sparse outputs and always spreads the positive probability to all positions. In this paper, we propose r-softmax, a modification of the softmax, outputting sparse probability distribution with controllable sparsity rate. In contrast to the existing sparse probability mapping functions, we provide an intuitive mechanism for controlling the output sparsity level. We show on several multi-label datasets that r-softmax outperforms other sparse alternatives to softmax and is highly competitive with the original softmax. We also apply r-softmax to the self-attention module of a pre-trained transformer language model and demonstrate that it leads to improved performance when fine-tuning the model on different natural language processing tasks.
Step by Step Loss Goes Very Far: Multi-Step Quantization for Adversarial Text Attacks
Feb 10, 2023



We propose a novel gradient-based attack against transformer-based language models that searches for an adversarial example in a continuous space of token probabilities. Our algorithm mitigates the gap between adversarial loss for continuous and discrete text representations by performing multi-step quantization in a quantization-compensation loop. Experiments show that our method significantly outperforms other approaches on various natural language processing (NLP) tasks.
Revisiting Offline Compression: Going Beyond Factorization-based Methods for Transformer Language Models
Feb 08, 2023Recent transformer language models achieve outstanding results in many natural language processing (NLP) tasks. However, their enormous size often makes them impractical on memory-constrained devices, requiring practitioners to compress them to smaller networks. In this paper, we explore offline compression methods, meaning computationally-cheap approaches that do not require further fine-tuning of the compressed model. We challenge the classical matrix factorization methods by proposing a novel, better-performing autoencoder-based framework. We perform a comprehensive ablation study of our approach, examining its different aspects over a diverse set of evaluation settings. Moreover, we show that enabling collaboration between modules across layers by compressing certain modules together positively impacts the final model performance. Experiments on various NLP tasks demonstrate that our approach significantly outperforms commonly used factorization-based offline compression methods.
Direction is what you need: Improving Word Embedding Compression in Large Language Models
Jun 15, 2021


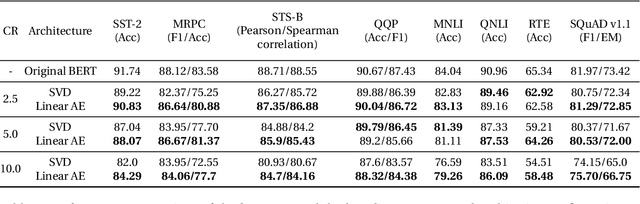
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
Zero Time Waste: Recycling Predictions in Early Exit Neural Networks
Jun 09, 2021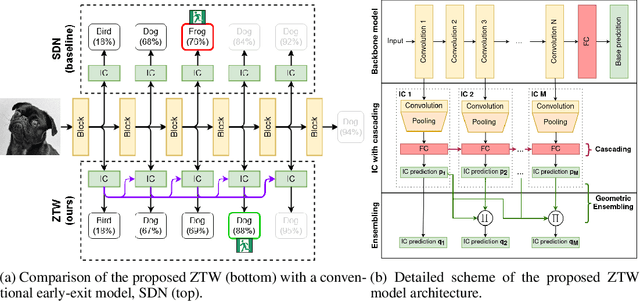
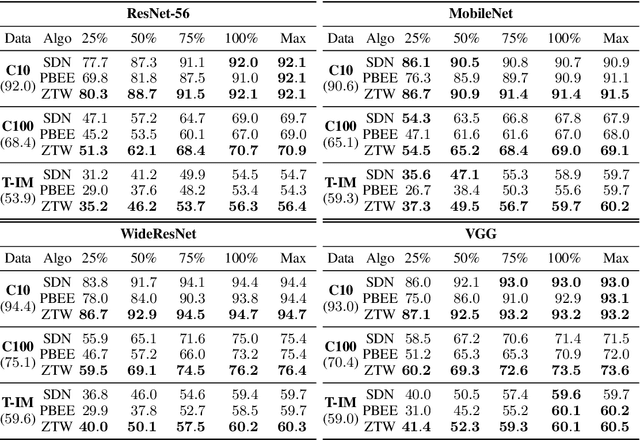
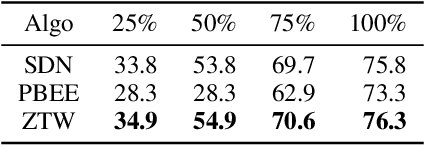
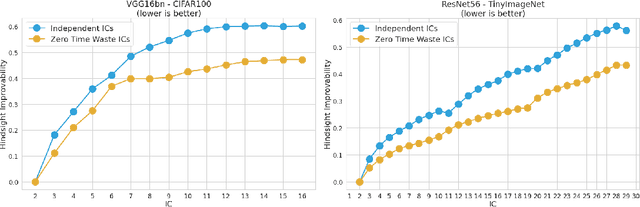
The problem of reducing processing time of large deep learning models is a fundamental challenge in many real-world applications. Early exit methods strive towards this goal by attaching additional Internal Classifiers (ICs) to intermediate layers of a neural network. ICs can quickly return predictions for easy examples and, as a result, reduce the average inference time of the whole model. However, if a particular IC does not decide to return an answer early, its predictions are discarded, with its computations effectively being wasted. To solve this issue, we introduce Zero Time Waste (ZTW), a novel approach in which each IC reuses predictions returned by its predecessors by (1) adding direct connections between ICs and (2) combining previous outputs in an ensemble-like manner. We conduct extensive experiments across various datasets and architectures to demonstrate that ZTW achieves a significantly better accuracy vs. inference time trade-off than other recently proposed early exit methods.
Finding the Optimal Network Depth in Classification Tasks
Apr 17, 2020
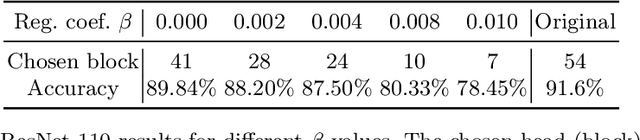

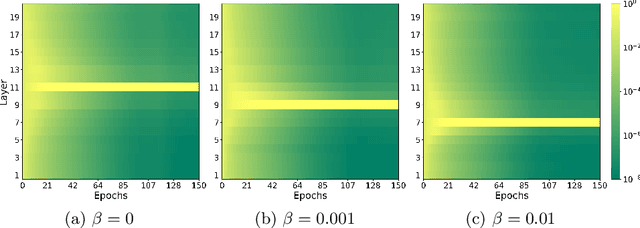
We develop a fast end-to-end method for training lightweight neural networks using multiple classifier heads. By allowing the model to determine the importance of each head and rewarding the choice of a single shallow classifier, we are able to detect and remove unneeded components of the network. This operation, which can be seen as finding the optimal depth of the model, significantly reduces the number of parameters and accelerates inference across different hardware processing units, which is not the case for many standard pruning methods. We show the performance of our method on multiple network architectures and datasets, analyze its optimization properties, and conduct ablation studies.