 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Technological Convergence in Encryption Technologies with Proximity Indices: A Text Mining and Bibliometric Analysis using OpenAlex
Mar 03, 2024



Identifying technological convergence among emerging technologies in cybersecurity is crucial for advancing science and fostering innovation. Unlike previous studies focusing on the binary relationship between a paper and the concept it attributes to technology, our approach utilizes attribution scores to enhance the relationships between research papers, combining keywords, citation rates, and collaboration status with specific technological concepts. The proposed method integrates text mining and bibliometric analyses to formulate and predict technological proximity indices for encryption technologies using the "OpenAlex" catalog. Our case study findings highlight a significant convergence between blockchain and public-key cryptography, evidenced by the increasing proximity indices. These results offer valuable strategic insights for those contemplating investments in these domains.
LLMs Perform Poorly at Concept Extraction in Cyber-security Research Literature
Dec 12, 2023



The cybersecurity landscape evolves rapidly and poses threats to organizations. To enhance resilience, one needs to track the latest developments and trends in the domain. It has been demonstrated that standard bibliometrics approaches show their limits in such a fast-evolving domain. For this purpose, we use large language models (LLMs) to extract relevant knowledge entities from cybersecurity-related texts. We use a subset of arXiv preprints on cybersecurity as our data and compare different LLMs in terms of entity recognition (ER) and relevance. The results suggest that LLMs do not produce good knowledge entities that reflect the cybersecurity context, but our results show some potential for noun extractors. For this reason, we developed a noun extractor boosted with some statistical analysis to extract specific and relevant compound nouns from the domain. Later, we tested our model to identify trends in the LLM domain. We observe some limitations, but it offers promising results to monitor the evolution of emergent trends.
Fundamentals of Generative Large Language Models and Perspectives in Cyber-Defense
Mar 21, 2023Generative Language Models gained significant attention in late 2022 / early 2023, notably with the introduction of models refined to act consistently with users' expectations of interactions with AI (conversational models). Arguably the focal point of public attention has been such a refinement of the GPT3 model -- the ChatGPT and its subsequent integration with auxiliary capabilities, including search as part of Microsoft Bing. Despite extensive prior research invested in their development, their performance and applicability to a range of daily tasks remained unclear and niche. However, their wider utilization without a requirement for technical expertise, made in large part possible through conversational fine-tuning, revealed the extent of their true capabilities in a real-world environment. This has garnered both public excitement for their potential applications and concerns about their capabilities and potential malicious uses. This review aims to provide a brief overview of the history, state of the art, and implications of Generative Language Models in terms of their principles, abilities, limitations, and future prospects -- especially in the context of cyber-defense, with a focus on the Swiss operational environment.
Beyond S-curves: Recurrent Neural Networks for Technology Forecasting
Nov 28, 2022



Because of the considerable heterogeneity and complexity of the technological landscape, building accurate models to forecast is a challenging endeavor. Due to their high prevalence in many complex systems, S-curves are a popular forecasting approach in previous work. However, their forecasting performance has not been directly compared to other technology forecasting approaches. Additionally, recent developments in time series forecasting that claim to improve forecasting accuracy are yet to be applied to technological development data. This work addresses both research gaps by comparing the forecasting performance of S-curves to a baseline and by developing an autencoder approach that employs recent advances in machine learning and time series forecasting. S-curves forecasts largely exhibit a mean average percentage error (MAPE) comparable to a simple ARIMA baseline. However, for a minority of emerging technologies, the MAPE increases by two magnitudes. Our autoencoder approach improves the MAPE by 13.5% on average over the second-best result. It forecasts established technologies with the same accuracy as the other approaches. However, it is especially strong at forecasting emerging technologies with a mean MAPE 18% lower than the next best result. Our results imply that a simple ARIMA model is preferable over the S-curve for technology forecasting. Practitioners looking for more accurate forecasts should opt for the presented autoencoder approach.
From Scattered Sources to Comprehensive Technology Landscape: A Recommendation-based Retrieval Approach
Dec 09, 2021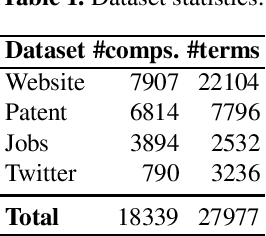
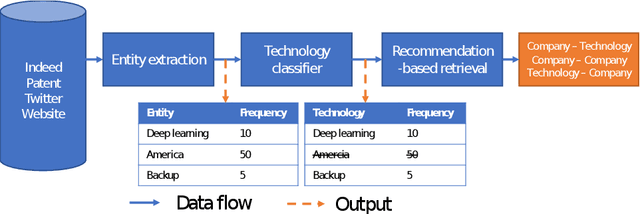
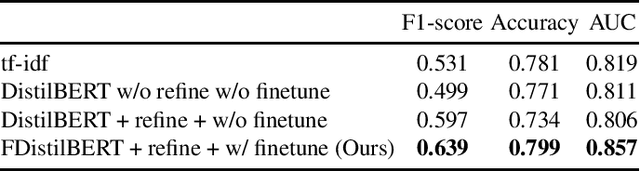
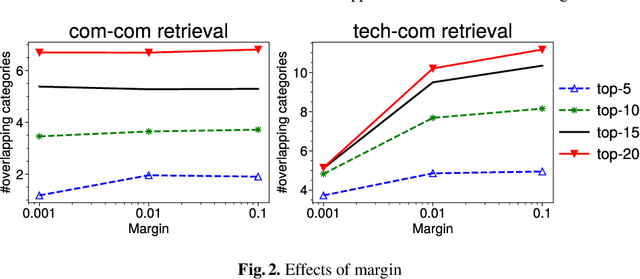
Mapping the technology landscape is crucial for market actors to take informed investment decisions. However, given the large amount of data on the Web and its subsequent information overload, manually retrieving information is a seemingly ineffective and incomplete approach. In this work, we propose an end-to-end recommendation based retrieval approach to support automatic retrieval of technologies and their associated companies from raw Web data. This is a two-task setup involving (i) technology classification of entities extracted from company corpus, and (ii) technology and company retrieval based on classified technologies. Our proposed framework approaches the first task by leveraging DistilBERT which is a state-of-the-art language model. For the retrieval task, we introduce a recommendation-based retrieval technique to simultaneously support retrieving related companies, technologies related to a specific company and companies relevant to a technology. To evaluate these tasks, we also construct a data set that includes company documents and entities extracted from these documents together with company categories and technology labels. Experiments show that our approach is able to return 4 times more relevant companies while outperforming traditional retrieval baseline in retrieving technologies.