 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Technological Convergence in Encryption Technologies with Proximity Indices: A Text Mining and Bibliometric Analysis using OpenAlex
Mar 03, 2024



Identifying technological convergence among emerging technologies in cybersecurity is crucial for advancing science and fostering innovation. Unlike previous studies focusing on the binary relationship between a paper and the concept it attributes to technology, our approach utilizes attribution scores to enhance the relationships between research papers, combining keywords, citation rates, and collaboration status with specific technological concepts. The proposed method integrates text mining and bibliometric analyses to formulate and predict technological proximity indices for encryption technologies using the "OpenAlex" catalog. Our case study findings highlight a significant convergence between blockchain and public-key cryptography, evidenced by the increasing proximity indices. These results offer valuable strategic insights for those contemplating investments in these domains.
LLMs Perform Poorly at Concept Extraction in Cyber-security Research Literature
Dec 12, 2023



The cybersecurity landscape evolves rapidly and poses threats to organizations. To enhance resilience, one needs to track the latest developments and trends in the domain. It has been demonstrated that standard bibliometrics approaches show their limits in such a fast-evolving domain. For this purpose, we use large language models (LLMs) to extract relevant knowledge entities from cybersecurity-related texts. We use a subset of arXiv preprints on cybersecurity as our data and compare different LLMs in terms of entity recognition (ER) and relevance. The results suggest that LLMs do not produce good knowledge entities that reflect the cybersecurity context, but our results show some potential for noun extractors. For this reason, we developed a noun extractor boosted with some statistical analysis to extract specific and relevant compound nouns from the domain. Later, we tested our model to identify trends in the LLM domain. We observe some limitations, but it offers promising results to monitor the evolution of emergent trends.
Fundamentals of Generative Large Language Models and Perspectives in Cyber-Defense
Mar 21, 2023Generative Language Models gained significant attention in late 2022 / early 2023, notably with the introduction of models refined to act consistently with users' expectations of interactions with AI (conversational models). Arguably the focal point of public attention has been such a refinement of the GPT3 model -- the ChatGPT and its subsequent integration with auxiliary capabilities, including search as part of Microsoft Bing. Despite extensive prior research invested in their development, their performance and applicability to a range of daily tasks remained unclear and niche. However, their wider utilization without a requirement for technical expertise, made in large part possible through conversational fine-tuning, revealed the extent of their true capabilities in a real-world environment. This has garnered both public excitement for their potential applications and concerns about their capabilities and potential malicious uses. This review aims to provide a brief overview of the history, state of the art, and implications of Generative Language Models in terms of their principles, abilities, limitations, and future prospects -- especially in the context of cyber-defense, with a focus on the Swiss operational environment.
Case-Based Reasoning with Language Models for Classification of Logical Fallacies
Jan 27, 2023



The ease and the speed of spreading misinformation and propaganda on the Web motivate the need to develop trustworthy technology for detecting fallacies in natural language arguments. However, state-of-the-art language modeling methods exhibit a lack of robustness on tasks like logical fallacy classification that require complex reasoning. In this paper, we propose a Case-Based Reasoning method that classifies new cases of logical fallacy by language-modeling-driven retrieval and adaptation of historical cases. We design four complementary strategies to enrich the input representation for our model, based on external information about goals, explanations, counterarguments, and argument structure. Our experiments in in-domain and out-of-domain settings indicate that Case-Based Reasoning improves the accuracy and generalizability of language models. Our ablation studies confirm that the representations of similar cases have a strong impact on the model performance, that models perform well with fewer retrieved cases, and that the size of the case database has a negligible effect on the performance. Finally, we dive deeper into the relationship between the properties of the retrieved cases and the model performance.
Robust and Explainable Identification of Logical Fallacies in Natural Language Arguments
Dec 12, 2022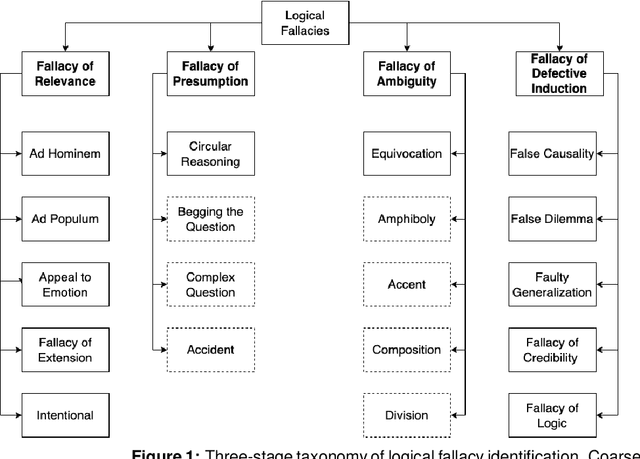
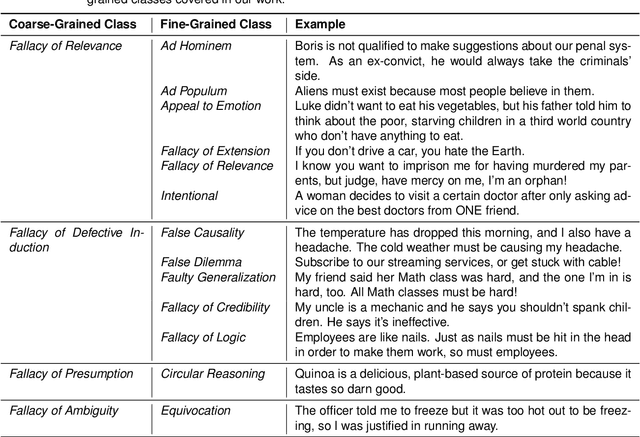
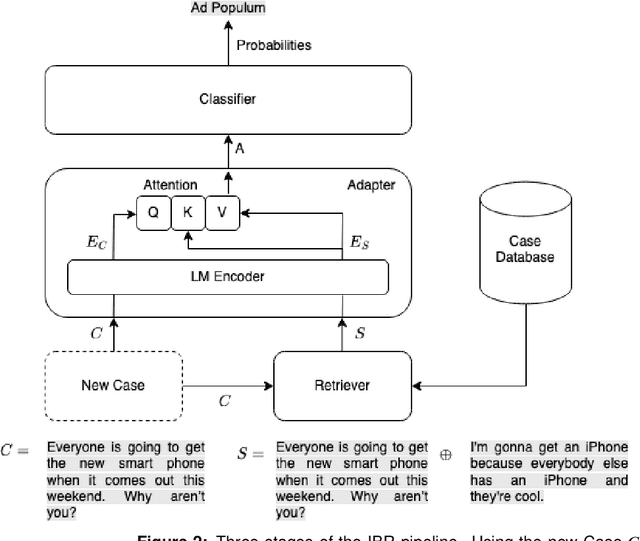
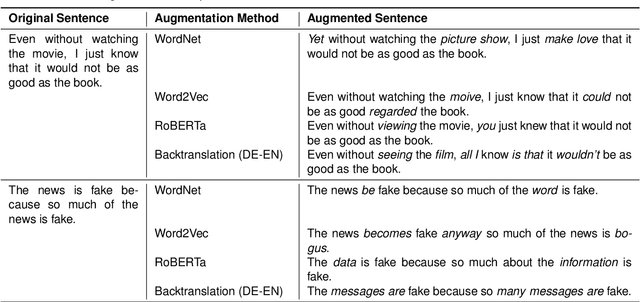
The spread of misinformation, propaganda, and flawed argumentation has been amplified in the Internet era. Given the volume of data and the subtlety of identifying violations of argumentation norms, supporting information analytics tasks, like content moderation, with trustworthy methods that can identify logical fallacies is essential. In this paper, we formalize prior theoretical work on logical fallacies into a comprehensive three-stage evaluation framework of detection, coarse-grained, and fine-grained classification. We adapt existing evaluation datasets for each stage of the evaluation. We devise three families of robust and explainable methods based on prototype reasoning, instance-based reasoning, and knowledge injection. The methods are designed to combine language models with background knowledge and explainable mechanisms. Moreover, we address data sparsity with strategies for data augmentation and curriculum learning. Our three-stage framework natively consolidates prior datasets and methods from existing tasks, like propaganda detection, serving as an overarching evaluation testbed. We extensively evaluate these methods on our datasets, focusing on their robustness and explainability. Our results provide insight into the strengths and weaknesses of the methods on different components and fallacy classes, indicating that fallacy identification is a challenging task that may require specialized forms of reasoning to capture various classes. We share our open-source code and data on GitHub to support further work on logical fallacy identification.
Multimodal and Explainable Internet Meme Classification
Dec 11, 2022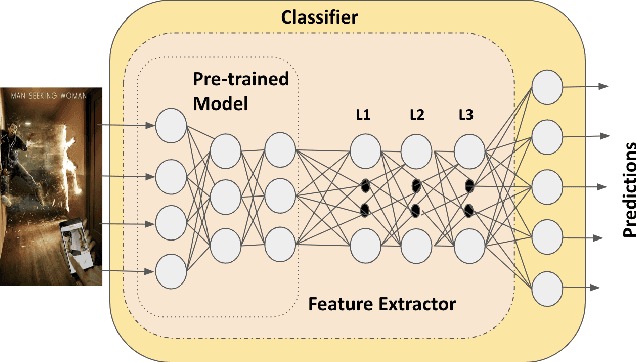

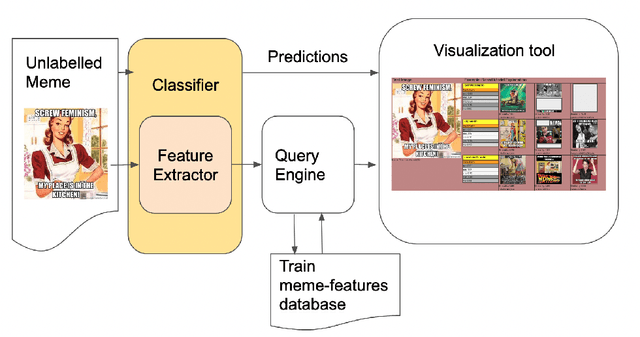

Warning: this paper contains content that may be offensive or upsetting. In the current context where online platforms have been effectively weaponized in a variety of geo-political events and social issues, Internet memes make fair content moderation at scale even more difficult. Existing work on meme classification and tracking has focused on black-box methods that do not explicitly consider the semantics of the memes or the context of their creation. In this paper, we pursue a modular and explainable architecture for Internet meme understanding. We design and implement multimodal classification methods that perform example- and prototype-based reasoning over training cases, while leveraging both textual and visual SOTA models to represent the individual cases. We study the relevance of our modular and explainable models in detecting harmful memes on two existing tasks: Hate Speech Detection and Misogyny Classification. We compare the performance between example- and prototype-based methods, and between text, vision, and multimodal models, across different categories of harmfulness (e.g., stereotype and objectification). We devise a user-friendly interface that facilitates the comparative analysis of examples retrieved by all of our models for any given meme, informing the community about the strengths and limitations of these explainable methods.
A Study of Slang Representation Methods
Dec 11, 2022



Warning: this paper contains content that may be offensive or upsetting. Considering the large amount of content created online by the minute, slang-aware automatic tools are critically needed to promote social good, and assist policymakers and moderators in restricting the spread of offensive language, abuse, and hate speech. Despite the success of large language models and the spontaneous emergence of slang dictionaries, it is unclear how far their combination goes in terms of slang understanding for downstream social good tasks. In this paper, we provide a framework to study different combinations of representation learning models and knowledge resources for a variety of downstream tasks that rely on slang understanding. Our experiments show the superiority of models that have been pre-trained on social media data, while the impact of dictionaries is positive only for static word embeddings. Our error analysis identifies core challenges for slang representation learning, including out-of-vocabulary words, polysemy, variance, and annotation disagreements, which can be traced to characteristics of slang as a quickly evolving and highly subjective language.
Beyond S-curves: Recurrent Neural Networks for Technology Forecasting
Nov 28, 2022



Because of the considerable heterogeneity and complexity of the technological landscape, building accurate models to forecast is a challenging endeavor. Due to their high prevalence in many complex systems, S-curves are a popular forecasting approach in previous work. However, their forecasting performance has not been directly compared to other technology forecasting approaches. Additionally, recent developments in time series forecasting that claim to improve forecasting accuracy are yet to be applied to technological development data. This work addresses both research gaps by comparing the forecasting performance of S-curves to a baseline and by developing an autencoder approach that employs recent advances in machine learning and time series forecasting. S-curves forecasts largely exhibit a mean average percentage error (MAPE) comparable to a simple ARIMA baseline. However, for a minority of emerging technologies, the MAPE increases by two magnitudes. Our autoencoder approach improves the MAPE by 13.5% on average over the second-best result. It forecasts established technologies with the same accuracy as the other approaches. However, it is especially strong at forecasting emerging technologies with a mean MAPE 18% lower than the next best result. Our results imply that a simple ARIMA model is preferable over the S-curve for technology forecasting. Practitioners looking for more accurate forecasts should opt for the presented autoencoder approach.
Orchestrating Collaborative Cybersecurity: A Secure Framework for Distributed Privacy-Preserving Threat Intelligence Sharing
Sep 06, 2022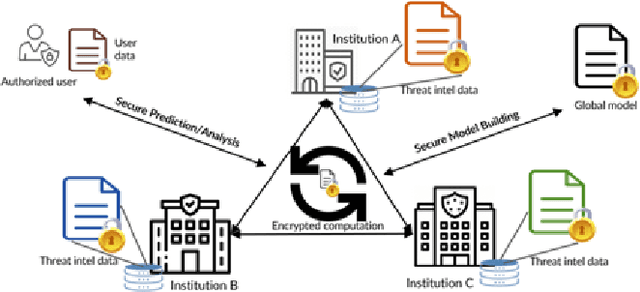

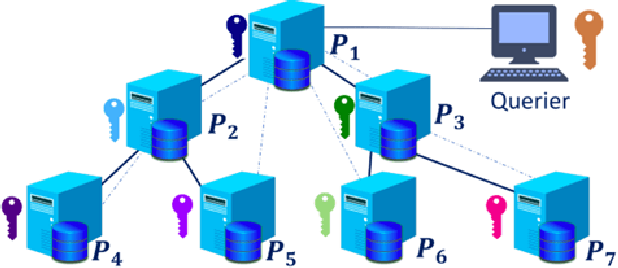
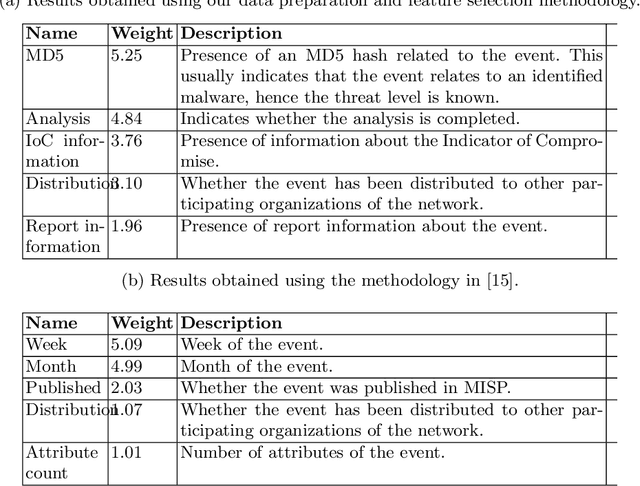
Cyber Threat Intelligence (CTI) sharing is an important activity to reduce information asymmetries between attackers and defenders. However, this activity presents challenges due to the tension between data sharing and confidentiality, that result in information retention often leading to a free-rider problem. Therefore, the information that is shared represents only the tip of the iceberg. Current literature assumes access to centralized databases containing all the information, but this is not always feasible, due to the aforementioned tension. This results in unbalanced or incomplete datasets, requiring the use of techniques to expand them; we show how these techniques lead to biased results and misleading performance expectations. We propose a novel framework for extracting CTI from distributed data on incidents, vulnerabilities and indicators of compromise, and demonstrate its use in several practical scenarios, in conjunction with the Malware Information Sharing Platforms (MISP). Policy implications for CTI sharing are presented and discussed. The proposed system relies on an efficient combination of privacy enhancing technologies and federated processing. This lets organizations stay in control of their CTI and minimize the risks of exposure or leakage, while enabling the benefits of sharing, more accurate and representative results, and more effective predictive and preventive defenses.
From Scattered Sources to Comprehensive Technology Landscape: A Recommendation-based Retrieval Approach
Dec 09, 2021
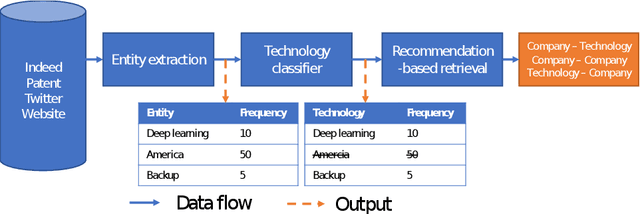
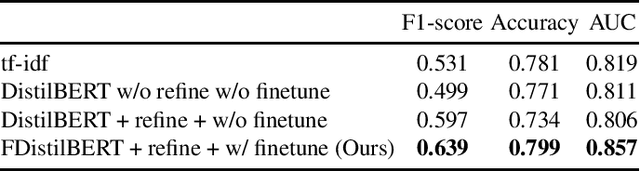
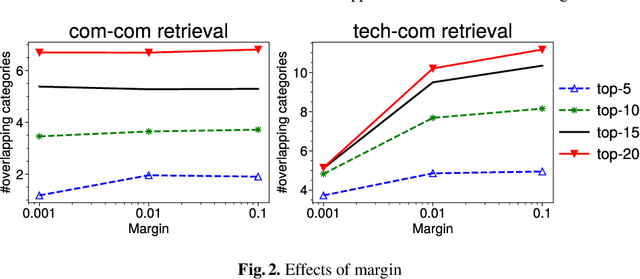
Mapping the technology landscape is crucial for market actors to take informed investment decisions. However, given the large amount of data on the Web and its subsequent information overload, manually retrieving information is a seemingly ineffective and incomplete approach. In this work, we propose an end-to-end recommendation based retrieval approach to support automatic retrieval of technologies and their associated companies from raw Web data. This is a two-task setup involving (i) technology classification of entities extracted from company corpus, and (ii) technology and company retrieval based on classified technologies. Our proposed framework approaches the first task by leveraging DistilBERT which is a state-of-the-art language model. For the retrieval task, we introduce a recommendation-based retrieval technique to simultaneously support retrieving related companies, technologies related to a specific company and companies relevant to a technology. To evaluate these tasks, we also construct a data set that includes company documents and entities extracted from these documents together with company categories and technology labels. Experiments show that our approach is able to return 4 times more relevant companies while outperforming traditional retrieval baseline in retrieving technologies.