 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scattered Sources to Comprehensive Technology Landscape: A Recommendation-based Retrieval Approach
Dec 09, 2021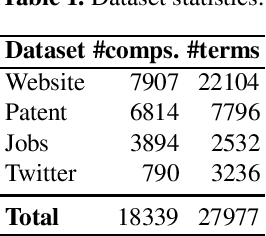
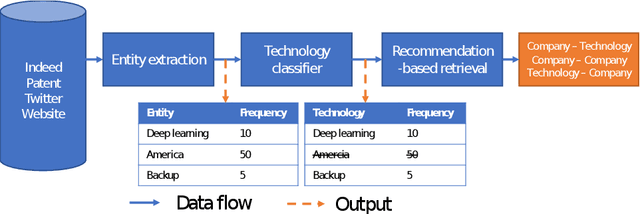
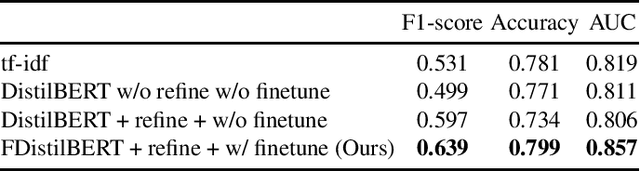
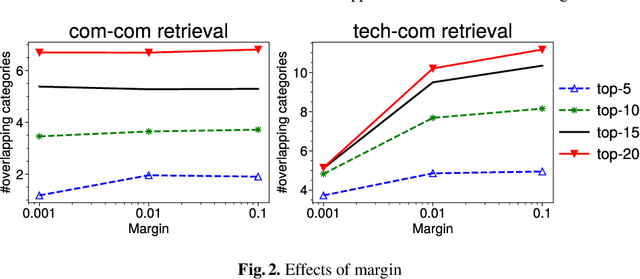
Mapping the technology landscape is crucial for market actors to take informed investment decisions. However, given the large amount of data on the Web and its subsequent information overload, manually retrieving information is a seemingly ineffective and incomplete approach. In this work, we propose an end-to-end recommendation based retrieval approach to support automatic retrieval of technologies and their associated companies from raw Web data. This is a two-task setup involving (i) technology classification of entities extracted from company corpus, and (ii) technology and company retrieval based on classified technologies. Our proposed framework approaches the first task by leveraging DistilBERT which is a state-of-the-art language model. For the retrieval task, we introduce a recommendation-based retrieval technique to simultaneously support retrieving related companies, technologies related to a specific company and companies relevant to a technology. To evaluate these tasks, we also construct a data set that includes company documents and entities extracted from these documents together with company categories and technology labels. Experiments show that our approach is able to return 4 times more relevant companies while outperforming traditional retrieval baseline in retrieving technologies.
On Node Features for Graph Neural Networks
Nov 20, 2019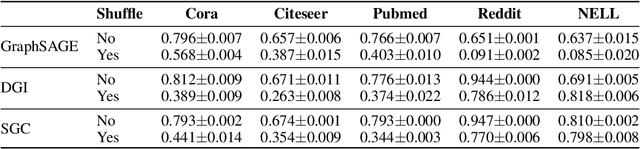
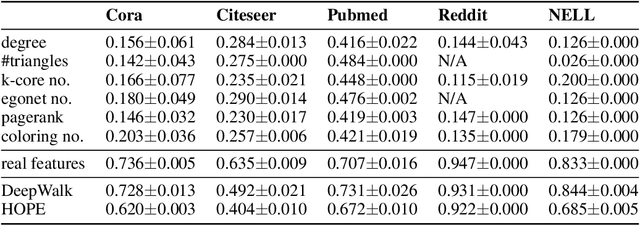
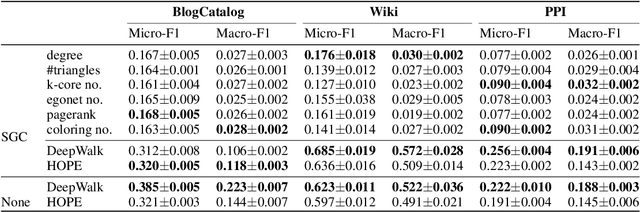
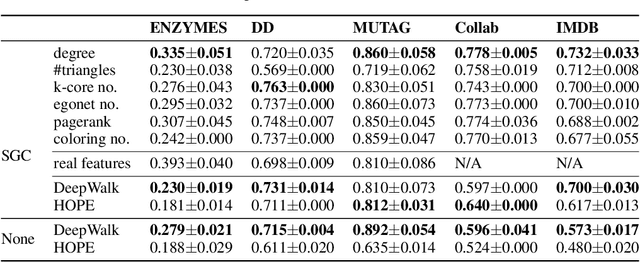
Graph neural network (GNN) is a deep model for graph representation learning. One advantage of graph neural network is its ability to incorporate node features into the learning process. However, this prevents graph neural network from being applied into featureless graphs. In this paper, we first analyze the effects of node features on the performance of graph neural network. We show that GNNs work well if there is a strong correlation between node features and node labels. Based on these results, we propose new feature initialization methods that allows to apply graph neural network to non-attributed graphs. Our experimental results show that the artificial features are highly competitive with real features.
Parallel Computation of Graph Embeddings
Sep 06, 2019
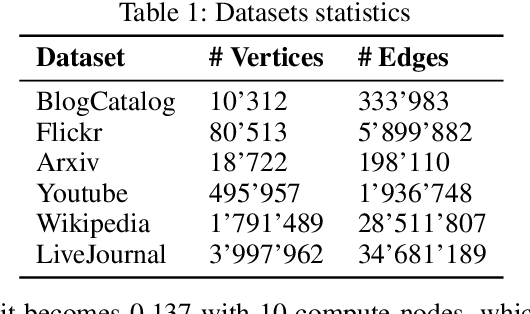
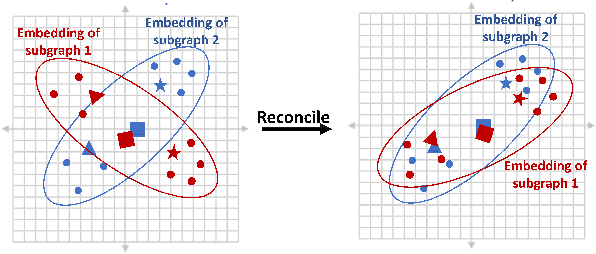
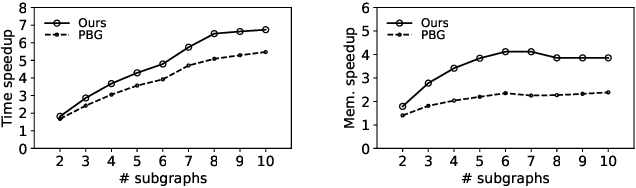
Graph embedding aims at learning a vector-based representation of vertices that incorporates the structure of the graph. This representation then enables inference of graph properties. Existing graph embedding techniques, however, do not scale well to large graphs. We therefore propose a framework for parallel computation of a graph embedding using a cluster of compute nodes with resource constraints. We show how to distribute any existing embedding technique by first splitting a graph for any given set of constrained compute nodes and then reconciling the embedding spaces derived for these subgraphs. We also propose a new way to evaluate the quality of graph embeddings that is independent of a specific inference task. Based thereon, we give a formal bound on the difference between the embeddings derived by centralised and parallel computation. Experimental results illustrate that our approach for parallel computation scales well, while largely maintaining the embedding quality.
Multimodal Classification for Analysing Social Media
Aug 07, 2017
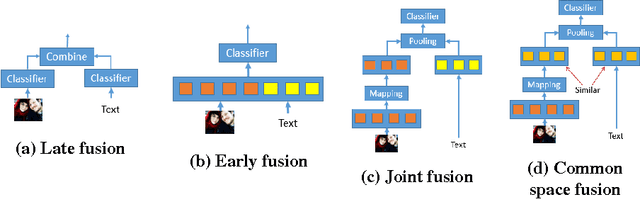
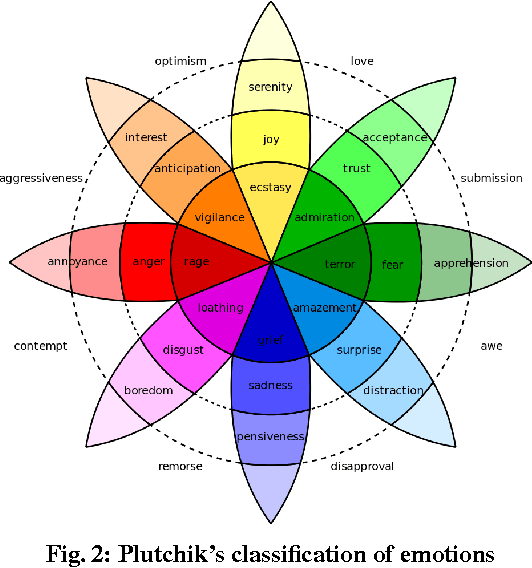
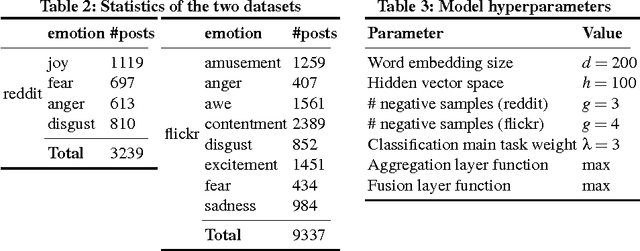
Classification of social media data is an important approach in understanding user behavior on the Web. Although information on social media can be of different modalities such as texts, images, audio or videos, traditional approaches in classification usually leverage only one prominent modality. Techniques that are able to leverage multiple modalities are often complex and susceptible to the absence of some modalities. In this paper, we present simple models that combine information from different modalities to classify social media content and are able to handle the above problems with existing techniques. Our models combine information from different modalities using a pooling layer and an auxiliary learning task is used to learn a common feature space. We demonstrate the performance of our models and their robustness to the missing of some modalities in the emotion classification domain. Our approaches, although being simple, can not only achieve significantly higher accuracies than traditional fusion approaches but also have comparable results when only one modality is available.