 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Big Data Architecture for Early Identification and Categorization of Dark Web Sites
Jan 24, 2024The dark web has become notorious for its association with illicit activities and there is a growing need for systems to automate the monitoring of this space. This paper proposes an end-to-end scalable architecture for the early identification of new Tor sites and the daily analysis of their content. The solution is built using an Open Source Big Data stack for data serving with Kubernetes, Kafka, Kubeflow, and MinIO, continuously discovering onion addresses in different sources (threat intelligence, code repositories, web-Tor gateways, and Tor repositories), downloading the HTML from Tor and deduplicating the content using MinHash LSH, and categorizing with the BERTopic modeling (SBERT embedding, UMAP dimensionality reduction, HDBSCAN document clustering and c-TF-IDF topic keywords). In 93 days, the system identified 80,049 onion services and characterized 90% of them, addressing the challenge of Tor volatility. A disproportionate amount of repeated content is found, with only 6.1% unique sites. From the HTML files of the dark sites, 31 different low-topics are extracted, manually labeled, and grouped into 11 high-level topics. The five most popular included sexual and violent content, repositories, search engines, carding, cryptocurrencies, and marketplaces. During the experiments, we identified 14 sites with 13,946 clones that shared a suspiciously similar mirroring rate per day, suggesting an extensive common phishing network. Among the related works, this study is the most representative characterization of onion services based on topics to date.
Case-Based Reasoning with Language Models for Classification of Logical Fallacies
Jan 27, 2023



The ease and the speed of spreading misinformation and propaganda on the Web motivate the need to develop trustworthy technology for detecting fallacies in natural language arguments. However, state-of-the-art language modeling methods exhibit a lack of robustness on tasks like logical fallacy classification that require complex reasoning. In this paper, we propose a Case-Based Reasoning method that classifies new cases of logical fallacy by language-modeling-driven retrieval and adaptation of historical cases. We design four complementary strategies to enrich the input representation for our model, based on external information about goals, explanations, counterarguments, and argument structure. Our experiments in in-domain and out-of-domain settings indicate that Case-Based Reasoning improves the accuracy and generalizability of language models. Our ablation studies confirm that the representations of similar cases have a strong impact on the model performance, that models perform well with fewer retrieved cases, and that the size of the case database has a negligible effect on the performance. Finally, we dive deeper into the relationship between the properties of the retrieved cases and the model performance.
Robust and Explainable Identification of Logical Fallacies in Natural Language Arguments
Dec 12, 2022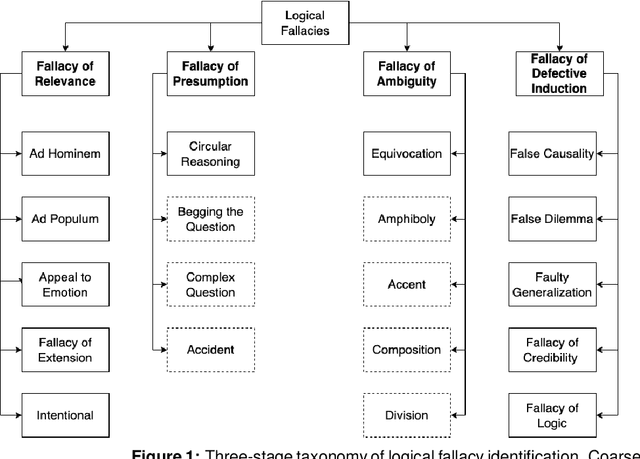
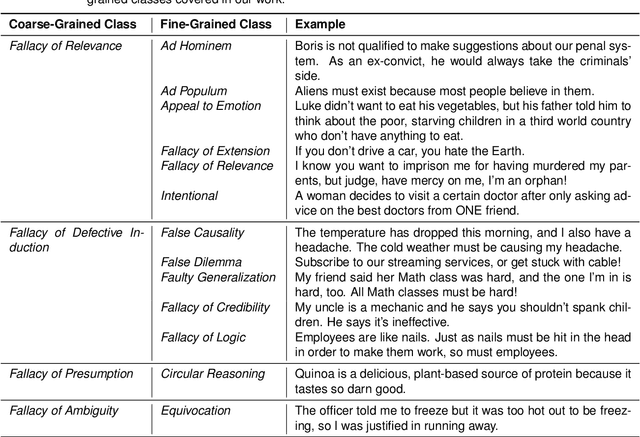
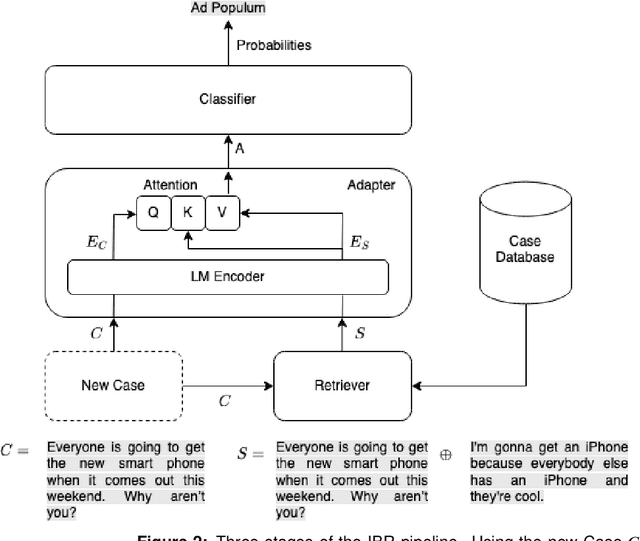
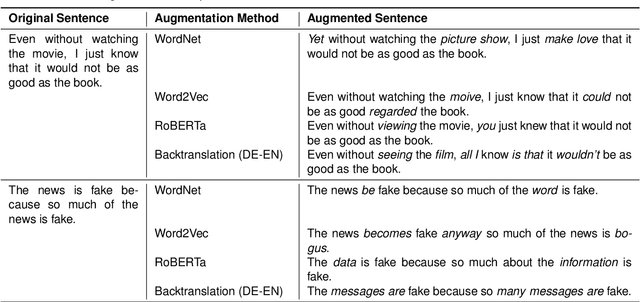
The spread of misinformation, propaganda, and flawed argumentation has been amplified in the Internet era. Given the volume of data and the subtlety of identifying violations of argumentation norms, supporting information analytics tasks, like content moderation, with trustworthy methods that can identify logical fallacies is essential. In this paper, we formalize prior theoretical work on logical fallacies into a comprehensive three-stage evaluation framework of detection, coarse-grained, and fine-grained classification. We adapt existing evaluation datasets for each stage of the evaluation. We devise three families of robust and explainable methods based on prototype reasoning, instance-based reasoning, and knowledge injection. The methods are designed to combine language models with background knowledge and explainable mechanisms. Moreover, we address data sparsity with strategies for data augmentation and curriculum learning. Our three-stage framework natively consolidates prior datasets and methods from existing tasks, like propaganda detection, serving as an overarching evaluation testbed. We extensively evaluate these methods on our datasets, focusing on their robustness and explainability. Our results provide insight into the strengths and weaknesses of the methods on different components and fallacy classes, indicating that fallacy identification is a challenging task that may require specialized forms of reasoning to capture various classes. We share our open-source code and data on GitHub to support further work on logical fallacy identification.
A Study of Slang Representation Methods
Dec 11, 2022



Warning: this paper contains content that may be offensive or upsetting. Considering the large amount of content created online by the minute, slang-aware automatic tools are critically needed to promote social good, and assist policymakers and moderators in restricting the spread of offensive language, abuse, and hate speech. Despite the success of large language models and the spontaneous emergence of slang dictionaries, it is unclear how far their combination goes in terms of slang understanding for downstream social good tasks. In this paper, we provide a framework to study different combinations of representation learning models and knowledge resources for a variety of downstream tasks that rely on slang understanding. Our experiments show the superiority of models that have been pre-trained on social media data, while the impact of dictionaries is positive only for static word embeddings. Our error analysis identifies core challenges for slang representation learning, including out-of-vocabulary words, polysemy, variance, and annotation disagreements, which can be traced to characteristics of slang as a quickly evolving and highly subjective language.
Multimodal and Explainable Internet Meme Classification
Dec 11, 2022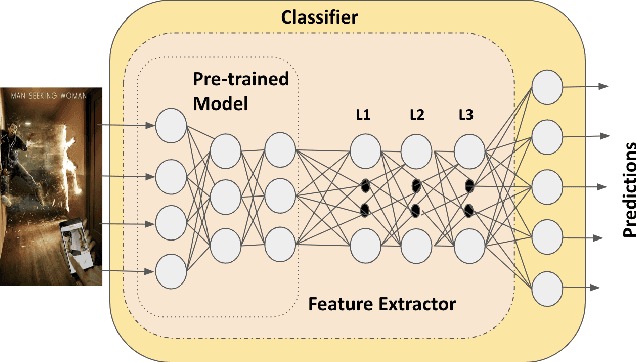

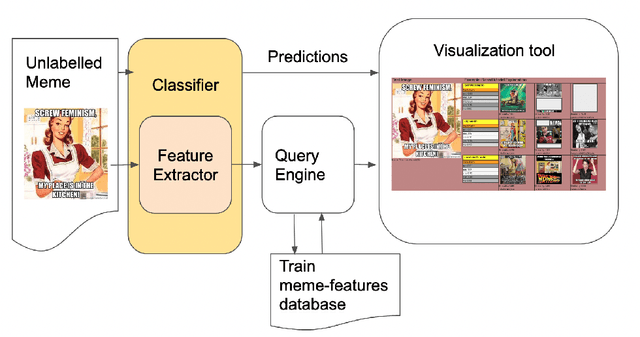

Warning: this paper contains content that may be offensive or upsetting. In the current context where online platforms have been effectively weaponized in a variety of geo-political events and social issues, Internet memes make fair content moderation at scale even more difficult. Existing work on meme classification and tracking has focused on black-box methods that do not explicitly consider the semantics of the memes or the context of their creation. In this paper, we pursue a modular and explainable architecture for Internet meme understanding. We design and implement multimodal classification methods that perform example- and prototype-based reasoning over training cases, while leveraging both textual and visual SOTA models to represent the individual cases. We study the relevance of our modular and explainable models in detecting harmful memes on two existing tasks: Hate Speech Detection and Misogyny Classification. We compare the performance between example- and prototype-based methods, and between text, vision, and multimodal models, across different categories of harmfulness (e.g., stereotype and objectification). We devise a user-friendly interface that facilitates the comparative analysis of examples retrieved by all of our models for any given meme, informing the community about the strengths and limitations of these explainable methods.