 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Identification of Logical Fallacies in Natural Language Arguments
Paper and Code
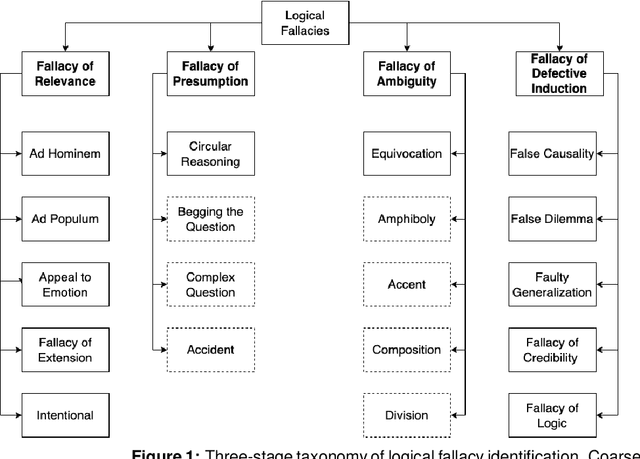
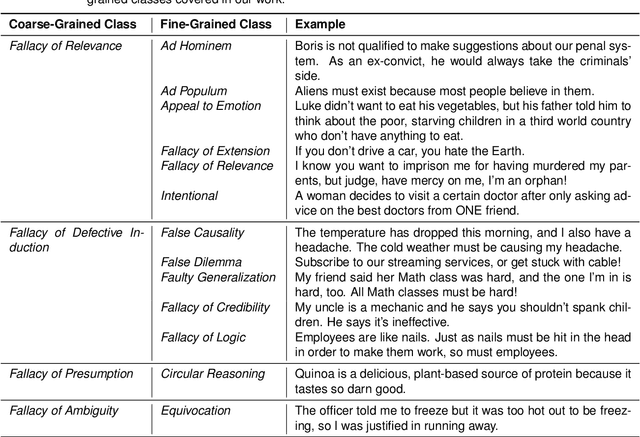
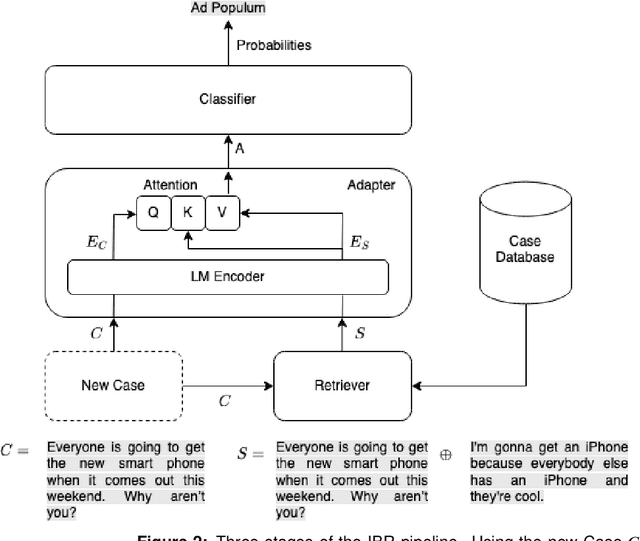
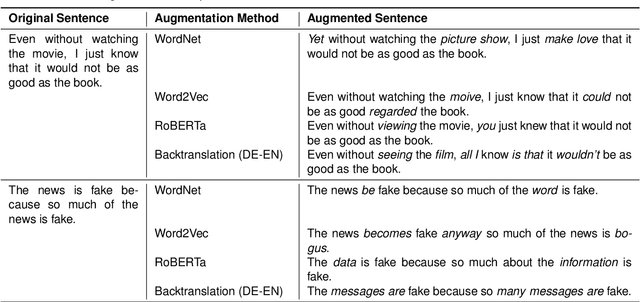
The spread of misinformation, propaganda, and flawed argumentation has been amplified in the Internet era. Given the volume of data and the subtlety of identifying violations of argumentation norms, supporting information analytics tasks, like content moderation, with trustworthy methods that can identify logical fallacies is essential. In this paper, we formalize prior theoretical work on logical fallacies into a comprehensive three-stage evaluation framework of detection, coarse-grained, and fine-grained classification. We adapt existing evaluation datasets for each stage of the evaluation. We devise three families of robust and explainable methods based on prototype reasoning, instance-based reasoning, and knowledge injection. The methods are designed to combine language models with background knowledge and explainable mechanisms. Moreover, we address data sparsity with strategies for data augmentation and curriculum learning. Our three-stage framework natively consolidates prior datasets and methods from existing tasks, like propaganda detection, serving as an overarching evaluation testbed. We extensively evaluate these methods on our datasets, focusing on their robustness and explainability. Our results provide insight into the strengths and weaknesses of the methods on different components and fallacy classes, indicating that fallacy identification is a challenging task that may require specialized forms of reasoning to capture various classes. We share our open-source code and data on GitHub to support further work on logical fallacy identification.