 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMPA: Model Poisoning Attacks on Decentralized Federated Learning for Model Differences
Feb 07, 2025
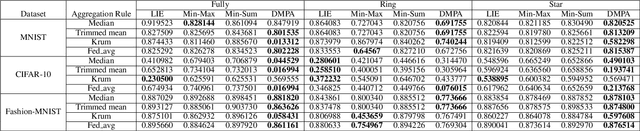
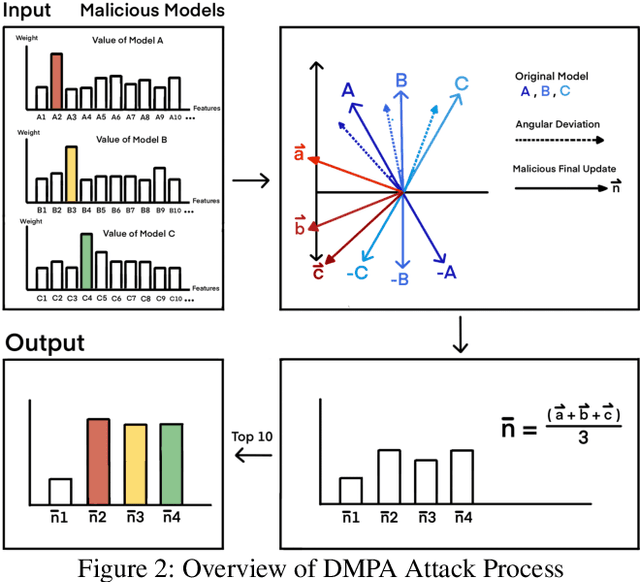
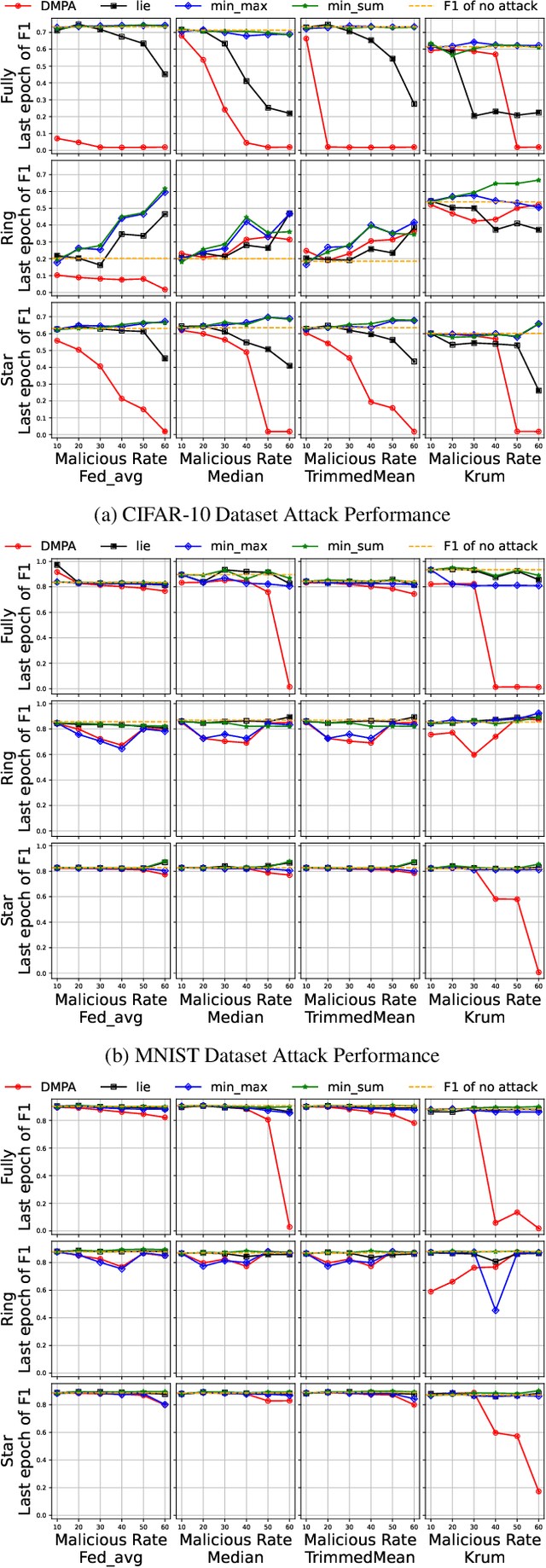
Federated learning (FL) has garnered significant attention as a prominent privacy-preserving Machine Learning (ML) paradigm. Decentralized FL (DFL) eschews traditional FL's centralized server architecture, enhancing the system's robustness and scalability. However, these advantages of DFL also create new vulnerabilities for malicious participants to execute adversarial attacks, especially model poisoning attacks. In model poisoning attacks, malicious participants aim to diminish the performance of benign models by creating and disseminating the compromised model. Existing research on model poisoning attacks has predominantly concentrated on undermining global models within the Centralized FL (CFL) paradigm, while there needs to be more research in DFL. To fill the research gap, this paper proposes an innovative model poisoning attack called DMPA. This attack calculates the differential characteristics of multiple malicious client models and obtains the most effective poisoning strategy, thereby orchestrating a collusive attack by multiple participants. The effectiveness of this attack is validated across multiple datasets, with results indicating that the DMPA approach consistently surpasses existing state-of-the-art FL model poisoning attack strategies.
S-VOTE: Similarity-based Voting for Client Selection in Decentralized Federated Learning
Jan 31, 2025Decentralized Federated Learning (DFL) enables collaborative, privacy-preserving model training without relying on a central server. This decentralized approach reduces bottlenecks and eliminates single points of failure, enhancing scalability and resilience. However, DFL also introduces challenges such as suboptimal models with non-IID data distributions, increased communication overhead, and resource usage. Thus, this work proposes S-VOTE, a voting-based client selection mechanism that optimizes resource usage and enhances model performance in federations with non-IID data conditions. S-VOTE considers an adaptive strategy for spontaneous local training that addresses participation imbalance, allowing underutilized clients to contribute without significantly increasing resource costs. Extensive experiments on benchmark datasets demonstrate the S-VOTE effectiveness. More in detail, it achieves lower communication costs by up to 21%, 4-6% faster convergence, and improves local performance by 9-17% compared to baseline methods in some configurations, all while achieving a 14-24% energy consumption reduction. These results highlight the potential of S-VOTE to address DFL challenges in heterogeneous environments.
ProFe: Communication-Efficient Decentralized Federated Learning via Distillation and Prototypes
Dec 15, 2024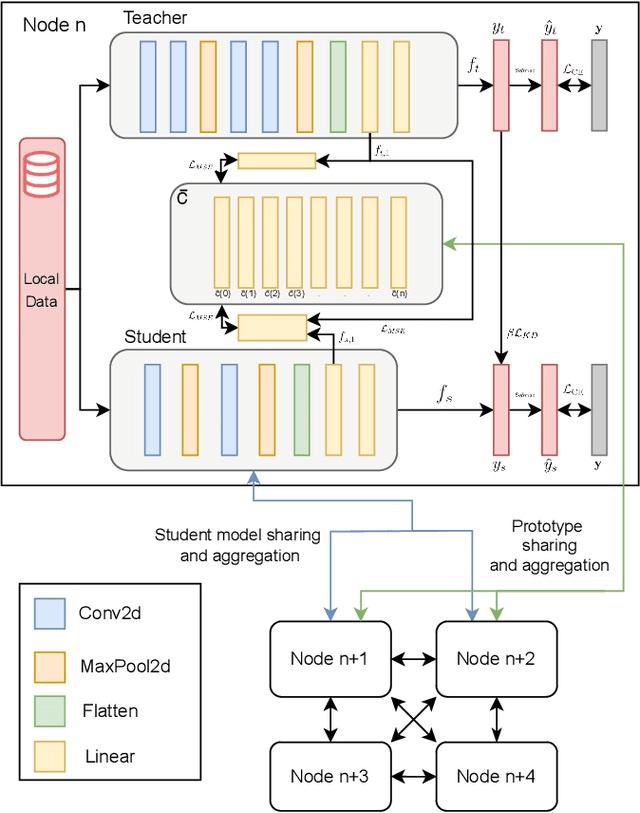
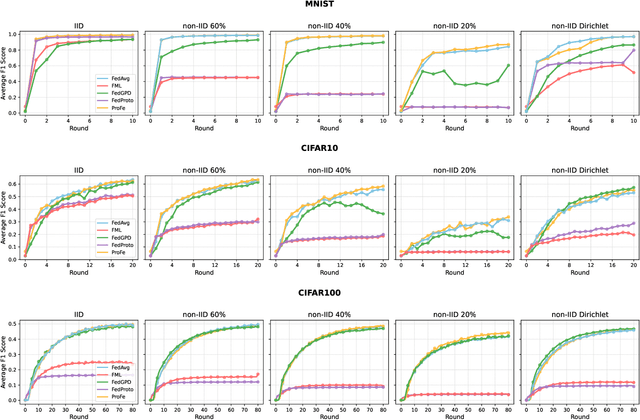
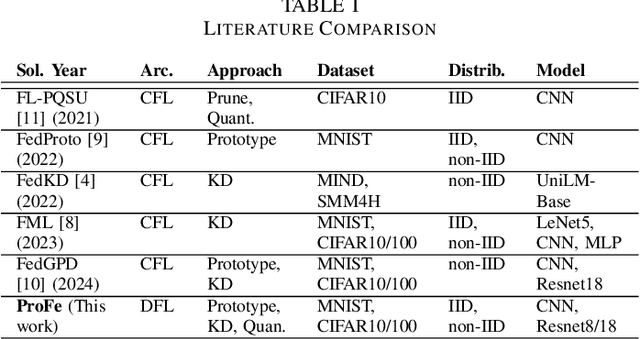

Decentralized Federated Learning (DFL) trains models in a collaborative and privacy-preserving manner while removing model centralization risks and improving communication bottlenecks. However, DFL faces challenges in efficient communication management and model aggregation within decentralized environments, especially with heterogeneous data distributions. Thus, this paper introduces ProFe, a novel communication optimization algorithm for DFL that combines knowledge distillation, prototype learning, and quantization techniques. ProFe utilizes knowledge from large local models to train smaller ones for aggregation, incorporates prototypes to better learn unseen classes, and applies quantization to reduce data transmitted during communication rounds. The performance of ProFe has been validated and compared to the literature by using benchmark datasets like MNIST, CIFAR10, and CIFAR100. Results showed that the proposed algorithm reduces communication costs by up to ~40-50% while maintaining or improving model performance. In addition, it adds ~20% training time due to increased complexity, generating a trade-off.
FedEP: Tailoring Attention to Heterogeneous Data Distribution with Entropy Pooling for Decentralized Federated Learning
Oct 10, 2024



Federated Learning (FL) performance is highly influenced by data distribution across clients, and non-Independent and Identically Distributed (non-IID) leads to a slower convergence of the global model and a decrease in model effectiveness. The existing algorithms for solving the non-IID problem are focused on the traditional centralized FL (CFL), where a central server is used for model aggregation. However, in decentralized FL (DFL), nodes lack the overall vision of the federation. To address the non-IID problem in DFL, this paper proposes a novel DFL aggregation algorithm, Federated Entropy Pooling (FedEP). FedEP mitigates the client drift problem by incorporating the statistical characteristics of local distributions instead of any actual data. Prior to training, each client conducts a local distribution fitting using a Gaussian Mixture Model (GMM) and shares the resulting statistical characteristics with its neighbors. After receiving the statistical characteristics shared by its neighbors, each node tries to fit the global data distribution. In the aggregation phase, each node calculates the Kullback-Leibler (KL) divergences of the local data distribution over the fitted global data distribution, giving the weights to generate the aggregated model. Extensive experiments have demonstrated that FedEP can achieve faster convergence and show higher test performance than state-of-the-art approaches.
Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
Jun 21, 2024Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
Transfer Learning in Pre-Trained Large Language Models for Malware Detection Based on System Calls
May 15, 2024In the current cybersecurity landscape, protecting military devices such as communication and battlefield management systems against sophisticated cyber attacks is crucial. Malware exploits vulnerabilities through stealth methods, often evading traditional detection mechanisms such as software signatures. The application of ML/DL in vulnerability detection has been extensively explored in the literature. However, current ML/DL vulnerability detection methods struggle with understanding the context and intent behind complex attacks. Integrating large language models (LLMs) with system call analysis offers a promising approach to enhance malware detection. This work presents a novel framework leveraging LLMs to classify malware based on system call data. The framework uses transfer learning to adapt pre-trained LLMs for malware detection. By retraining LLMs on a dataset of benign and malicious system calls, the models are refined to detect signs of malware activity. Experiments with a dataset of over 1TB of system calls demonstrate that models with larger context sizes, such as BigBird and Longformer, achieve superior accuracy and F1-Score of approximately 0.86. The results highlight the importance of context size in improving detection rates and underscore the trade-offs between computational complexity and performance. This approach shows significant potential for real-time detection in high-stakes environments, offering a robust solution to evolving cyber threats.
A Big Data Architecture for Early Identification and Categorization of Dark Web Sites
Jan 24, 2024The dark web has become notorious for its association with illicit activities and there is a growing need for systems to automate the monitoring of this space. This paper proposes an end-to-end scalable architecture for the early identification of new Tor sites and the daily analysis of their content. The solution is built using an Open Source Big Data stack for data serving with Kubernetes, Kafka, Kubeflow, and MinIO, continuously discovering onion addresses in different sources (threat intelligence, code repositories, web-Tor gateways, and Tor repositories), downloading the HTML from Tor and deduplicating the content using MinHash LSH, and categorizing with the BERTopic modeling (SBERT embedding, UMAP dimensionality reduction, HDBSCAN document clustering and c-TF-IDF topic keywords). In 93 days, the system identified 80,049 onion services and characterized 90% of them, addressing the challenge of Tor volatility. A disproportionate amount of repeated content is found, with only 6.1% unique sites. From the HTML files of the dark sites, 31 different low-topics are extracted, manually labeled, and grouped into 11 high-level topics. The five most popular included sexual and violent content, repositories, search engines, carding, cryptocurrencies, and marketplaces. During the experiments, we identified 14 sites with 13,946 clones that shared a suspiciously similar mirroring rate per day, suggesting an extensive common phishing network. Among the related works, this study is the most representative characterization of onion services based on topics to date.
Mitigating Communications Threats in Decentralized Federated Learning through Moving Target Defense
Jul 21, 2023The rise of Decentralized Federated Learning (DFL) has enabled the training of machine learning models across federated participants, fostering decentralized model aggregation and reducing dependence on a server. However, this approach introduces unique communication security challenges that have yet to be thoroughly addressed in the literature. These challenges primarily originate from the decentralized nature of the aggregation process, the varied roles and responsibilities of the participants, and the absence of a central authority to oversee and mitigate threats. Addressing these challenges, this paper first delineates a comprehensive threat model, highlighting the potential risks of DFL communications. In response to these identified risks, this work introduces a security module designed for DFL platforms to counter communication-based attacks. The module combines security techniques such as symmetric and asymmetric encryption with Moving Target Defense (MTD) techniques, including random neighbor selection and IP/port switching. The security module is implemented in a DFL platform called Fedstellar, allowing the deployment and monitoring of the federation. A DFL scenario has been deployed, involving eight physical devices implementing three security configurations: (i) a baseline with no security, (ii) an encrypted configuration, and (iii) a configuration integrating both encryption and MTD techniques. The effectiveness of the security module is validated through experiments with the MNIST dataset and eclipse attacks. The results indicated an average F1 score of 95%, with moderate increases in CPU usage (up to 63.2% +-3.5%) and network traffic (230 MB +-15 MB) under the most secure configuration, mitigating the risks posed by eavesdropping or eclipse attacks.
RansomAI: AI-powered Ransomware for Stealthy Encryption
Jun 27, 2023Cybersecurity solutions have shown promising performance when detecting ransomware samples that use fixed algorithms and encryption rates. However, due to the current explosion of Artificial Intelligence (AI), sooner than later, ransomware (and malware in general) will incorporate AI techniques to intelligently and dynamically adapt its encryption behavior to be undetected. It might result in ineffective and obsolete cybersecurity solutions, but the literature lacks AI-powered ransomware to verify it. Thus, this work proposes RansomAI, a Reinforcement Learning-based framework that can be integrated into existing ransomware samples to adapt their encryption behavior and stay stealthy while encrypting files. RansomAI presents an agent that learns the best encryption algorithm, rate, and duration that minimizes its detection (using a reward mechanism and a fingerprinting intelligent detection system) while maximizing its damage function. The proposed framework was validated in a ransomware, Ransomware-PoC, that infected a Raspberry Pi 4, acting as a crowdsensor. A pool of experiments with Deep Q-Learning and Isolation Forest (deployed on the agent and detection system, respectively) has demonstrated that RansomAI evades the detection of Ransomware-PoC affecting the Raspberry Pi 4 in a few minutes with >90% accuracy.
Fedstellar: A Platform for Decentralized Federated Learning
Jun 16, 2023
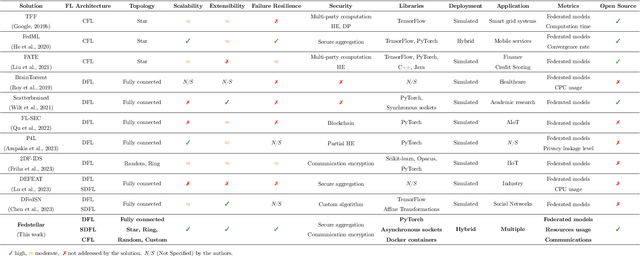
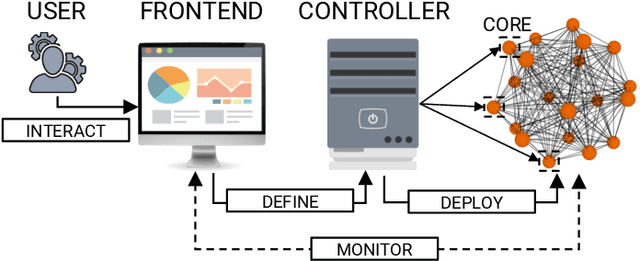
In 2016, Google proposed Federated Learning (FL) as a novel paradigm to train Machine Learning (ML) models across the participants of a federation while preserving data privacy. Since its birth, Centralized FL (CFL) has been the most used approach, where a central entity aggregates participants' models to create a global one. However, CFL presents limitations such as communication bottlenecks, single point of failure, and reliance on a central server. Decentralized Federated Learning (DFL) addresses these issues by enabling decentralized model aggregation and minimizing dependency on a central entity. Despite these advances, current platforms training DFL models struggle with key issues such as managing heterogeneous federation network topologies. To overcome these challenges, this paper presents Fedstellar, a novel platform designed to train FL models in a decentralized, semi-decentralized, and centralized fashion across diverse federations of physical or virtualized devices. The Fedstellar implementation encompasses a web application with an interactive graphical interface, a controller for deploying federations of nodes using physical or virtual devices, and a core deployed on each device which provides the logic needed to train, aggregate, and communicate in the network. The effectiveness of the platform has been demonstrated in two scenarios: a physical deployment involving single-board devices such as Raspberry Pis for detecting cyberattacks, and a virtualized deployment comparing various FL approaches in a controlled environment using MNIST and CIFAR-10 datasets. In both scenarios, Fedstellar demonstrated consistent performance and adaptability, achieving F1 scores of 91%, 98%, and 91.2% using DFL for detecting cyberattacks and classifying MNIST and CIFAR-10, respectively, reducing training time by 32% compared to centralized approaches.