 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNAPSE: Framework for Neuron Analysis and Perturbation in Sequence Encoding
Mar 09, 2026In recent years, Artificial Intelligence has become a powerful partner for complex tasks such as data analysis, prediction, and problem-solving, yet its lack of transparency raises concerns about its reliability. In sensitive domains such as healthcare or cybersecurity, ensuring transparency, trustworthiness, and robustness is essential, since the consequences of wrong decisions or successful attacks can be severe. Prior neuron-level interpretability approaches are primarily descriptive, task-dependent, or require retraining, which limits their use as systematic, reusable tools for evaluating internal robustness across architectures and domains. To overcome these limitations, this work proposes SYNAPSE, a systematic, training-free framework for understanding and stress-testing the internal behavior of Transformer models across domains. It extracts per-layer [CLS] representations, trains a lightweight linear probe to obtain global and per-class neuron rankings, and applies forward-hook interventions during inference. This design enables controlled experiments on internal representations without altering the original model, thereby allowing weaknesses, stability patterns, and label-specific sensitivities to be measured and compared directly across tasks and architectures. Across all experiments, SYNAPSE reveals a consistent, domain-independent organization of internal representations, in which task-relevant information is encoded in broad, overlapping neuron subsets. This redundancy provides a strong degree of functional stability, while class-wise asymmetries expose heterogeneous specialization patterns and enable label-aware analysis. In contrast, small structured manipulations in weight or logit space are sufficient to redirect predictions, highlighting complementary vulnerability profiles and illustrating how SYNAPSE can guide the development of more robust Transformer models.
S-VOTE: Similarity-based Voting for Client Selection in Decentralized Federated Learning
Jan 31, 2025Decentralized Federated Learning (DFL) enables collaborative, privacy-preserving model training without relying on a central server. This decentralized approach reduces bottlenecks and eliminates single points of failure, enhancing scalability and resilience. However, DFL also introduces challenges such as suboptimal models with non-IID data distributions, increased communication overhead, and resource usage. Thus, this work proposes S-VOTE, a voting-based client selection mechanism that optimizes resource usage and enhances model performance in federations with non-IID data conditions. S-VOTE considers an adaptive strategy for spontaneous local training that addresses participation imbalance, allowing underutilized clients to contribute without significantly increasing resource costs. Extensive experiments on benchmark datasets demonstrate the S-VOTE effectiveness. More in detail, it achieves lower communication costs by up to 21%, 4-6% faster convergence, and improves local performance by 9-17% compared to baseline methods in some configurations, all while achieving a 14-24% energy consumption reduction. These results highlight the potential of S-VOTE to address DFL challenges in heterogeneous environments.
ProFe: Communication-Efficient Decentralized Federated Learning via Distillation and Prototypes
Dec 15, 2024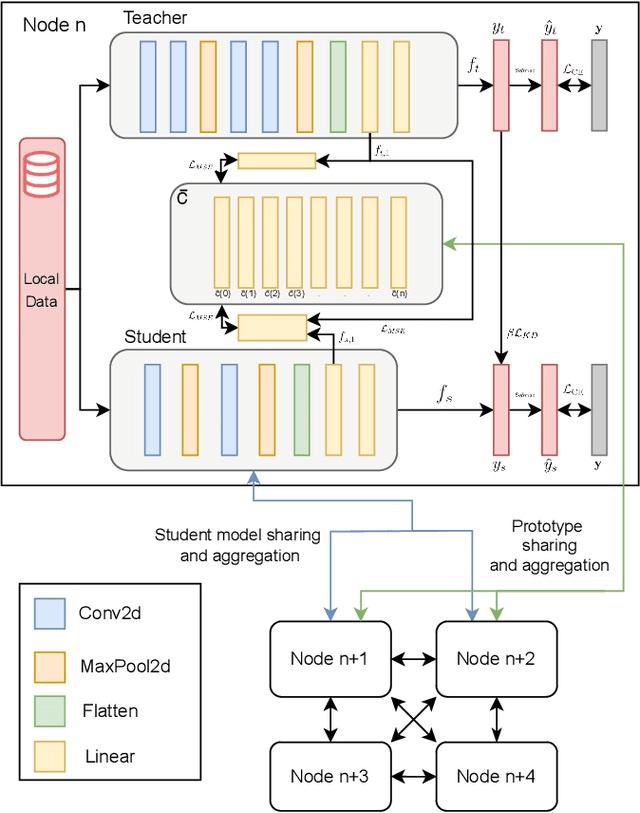
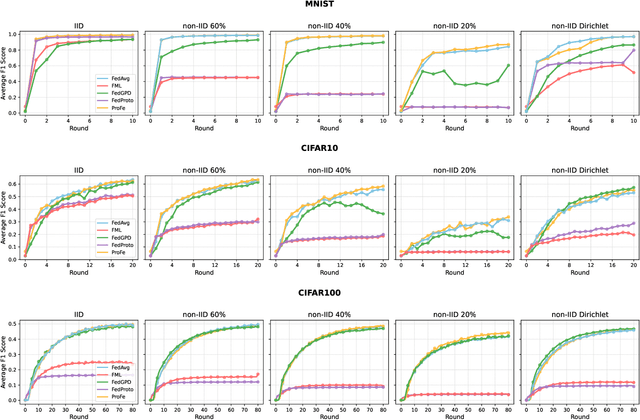
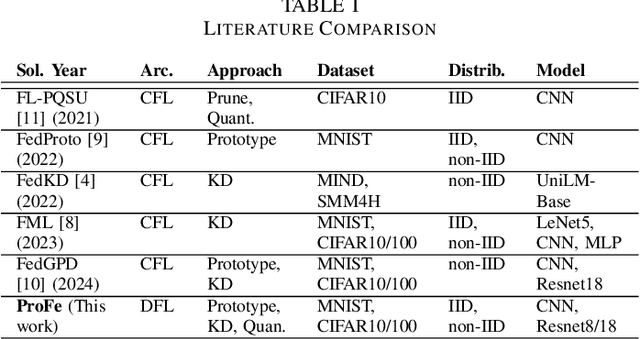

Decentralized Federated Learning (DFL) trains models in a collaborative and privacy-preserving manner while removing model centralization risks and improving communication bottlenecks. However, DFL faces challenges in efficient communication management and model aggregation within decentralized environments, especially with heterogeneous data distributions. Thus, this paper introduces ProFe, a novel communication optimization algorithm for DFL that combines knowledge distillation, prototype learning, and quantization techniques. ProFe utilizes knowledge from large local models to train smaller ones for aggregation, incorporates prototypes to better learn unseen classes, and applies quantization to reduce data transmitted during communication rounds. The performance of ProFe has been validated and compared to the literature by using benchmark datasets like MNIST, CIFAR10, and CIFAR100. Results showed that the proposed algorithm reduces communication costs by up to ~40-50% while maintaining or improving model performance. In addition, it adds ~20% training time due to increased complexity, generating a trade-off.
Mitigating Communications Threats in Decentralized Federated Learning through Moving Target Defense
Jul 21, 2023The rise of Decentralized Federated Learning (DFL) has enabled the training of machine learning models across federated participants, fostering decentralized model aggregation and reducing dependence on a server. However, this approach introduces unique communication security challenges that have yet to be thoroughly addressed in the literature. These challenges primarily originate from the decentralized nature of the aggregation process, the varied roles and responsibilities of the participants, and the absence of a central authority to oversee and mitigate threats. Addressing these challenges, this paper first delineates a comprehensive threat model, highlighting the potential risks of DFL communications. In response to these identified risks, this work introduces a security module designed for DFL platforms to counter communication-based attacks. The module combines security techniques such as symmetric and asymmetric encryption with Moving Target Defense (MTD) techniques, including random neighbor selection and IP/port switching. The security module is implemented in a DFL platform called Fedstellar, allowing the deployment and monitoring of the federation. A DFL scenario has been deployed, involving eight physical devices implementing three security configurations: (i) a baseline with no security, (ii) an encrypted configuration, and (iii) a configuration integrating both encryption and MTD techniques. The effectiveness of the security module is validated through experiments with the MNIST dataset and eclipse attacks. The results indicated an average F1 score of 95%, with moderate increases in CPU usage (up to 63.2% +-3.5%) and network traffic (230 MB +-15 MB) under the most secure configuration, mitigating the risks posed by eavesdropping or eclipse attacks.
Fedstellar: A Platform for Decentralized Federated Learning
Jun 16, 2023
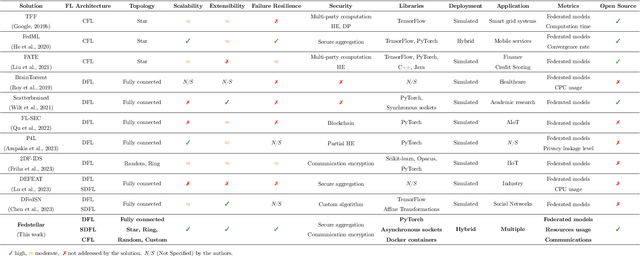
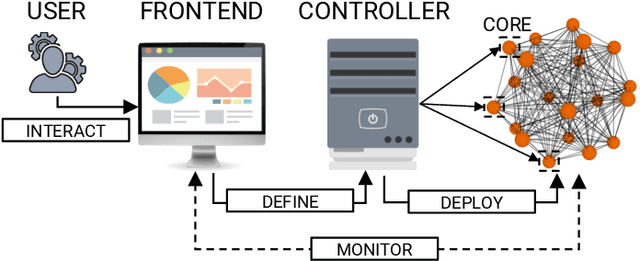
In 2016, Google proposed Federated Learning (FL) as a novel paradigm to train Machine Learning (ML) models across the participants of a federation while preserving data privacy. Since its birth, Centralized FL (CFL) has been the most used approach, where a central entity aggregates participants' models to create a global one. However, CFL presents limitations such as communication bottlenecks, single point of failure, and reliance on a central server. Decentralized Federated Learning (DFL) addresses these issues by enabling decentralized model aggregation and minimizing dependency on a central entity. Despite these advances, current platforms training DFL models struggle with key issues such as managing heterogeneous federation network topologies. To overcome these challenges, this paper presents Fedstellar, a novel platform designed to train FL models in a decentralized, semi-decentralized, and centralized fashion across diverse federations of physical or virtualized devices. The Fedstellar implementation encompasses a web application with an interactive graphical interface, a controller for deploying federations of nodes using physical or virtual devices, and a core deployed on each device which provides the logic needed to train, aggregate, and communicate in the network. The effectiveness of the platform has been demonstrated in two scenarios: a physical deployment involving single-board devices such as Raspberry Pis for detecting cyberattacks, and a virtualized deployment comparing various FL approaches in a controlled environment using MNIST and CIFAR-10 datasets. In both scenarios, Fedstellar demonstrated consistent performance and adaptability, achieving F1 scores of 91%, 98%, and 91.2% using DFL for detecting cyberattacks and classifying MNIST and CIFAR-10, respectively, reducing training time by 32% compared to centralized approaches.
Decentralized Federated Learning: Fundamentals, State-of-the-art, Frameworks, Trends, and Challenges
Nov 15, 2022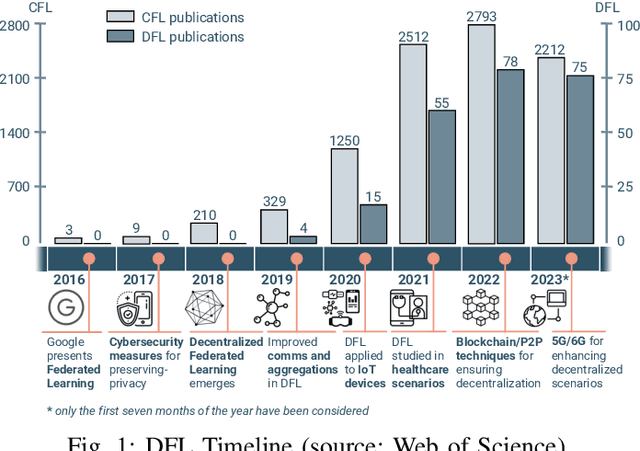
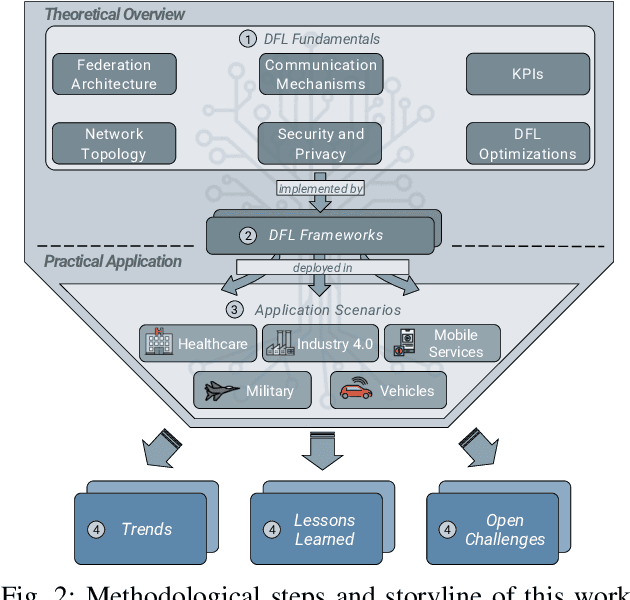
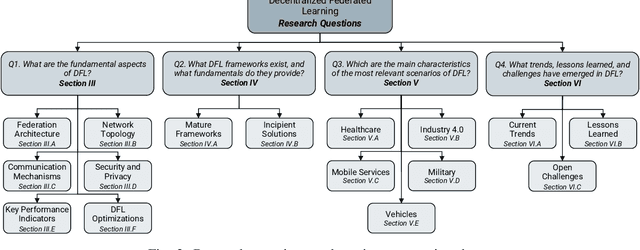
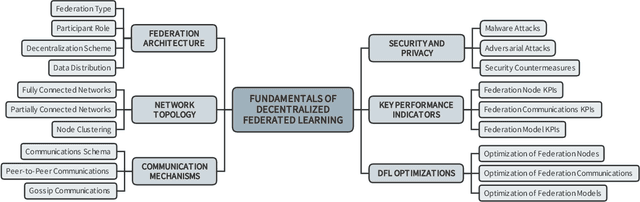
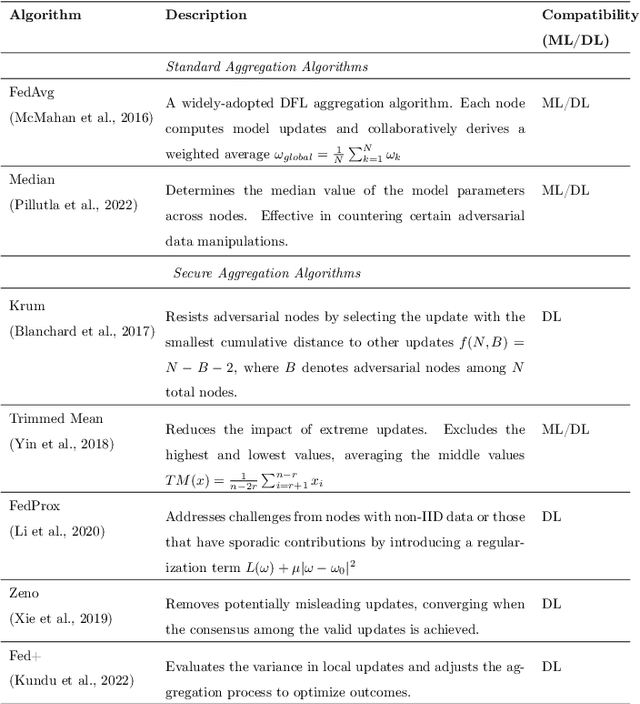
In the last decade, Federated Learning (FL) has gained relevance in training collaborative models without sharing sensitive data. Since its birth, Centralized FL (CFL) has been the most common approach in the literature, where a unique entity creates global models. However, using a centralized approach has the disadvantages of bottleneck at the server node, single point of failure, and trust needs. Decentralized Federated Learning (DFL) arose to solve these aspects by embracing the principles of data sharing minimization and decentralized model aggregation without relying on centralized architectures. However, despite the work done in DFL, the literature has not (i) studied the main fundamentals differentiating DFL and CFL; (ii) reviewed application scenarios and solutions using DFL; and (iii) analyzed DFL frameworks to create and evaluate new solutions. To this end, this article identifies and analyzes the main fundamentals of DFL in terms of federation architectures, topologies, communication mechanisms, security approaches, and key performance indicators. Additionally, the paper at hand explores existing mechanisms to optimize critical DFL fundamentals. Then, this work analyzes and compares the most used DFL application scenarios and solutions according to the fundamentals previously defined. After that, the most relevant features of the current DFL frameworks are reviewed and compared. Finally, the evolution of existing DFL solutions is analyzed to provide a list of trends, lessons learned, and open challenges.
Studying Drowsiness Detection Performance while Driving through Scalable Machine Learning Models using Electroencephalography
Sep 08, 2022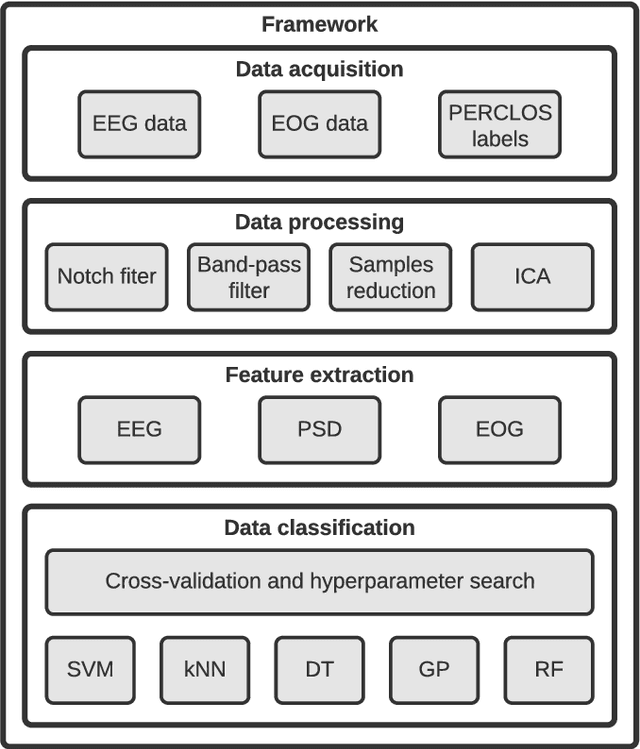
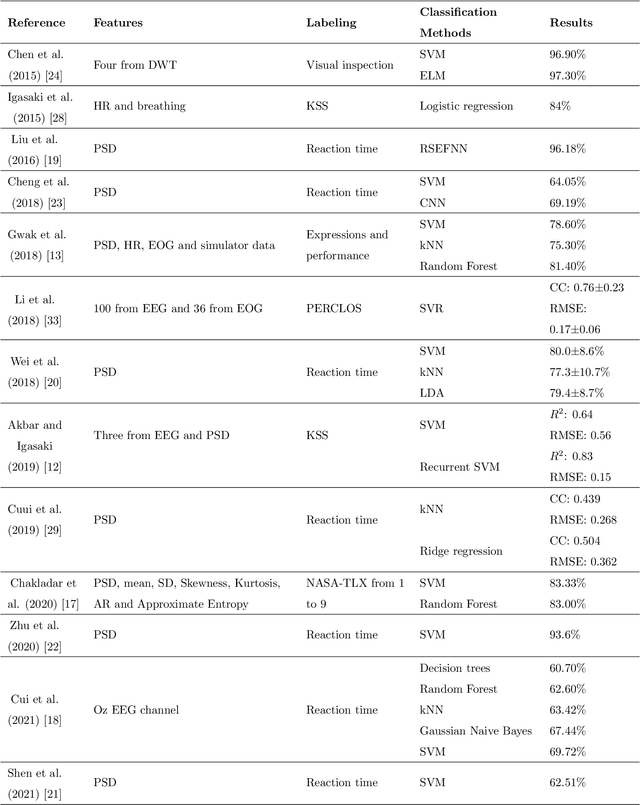

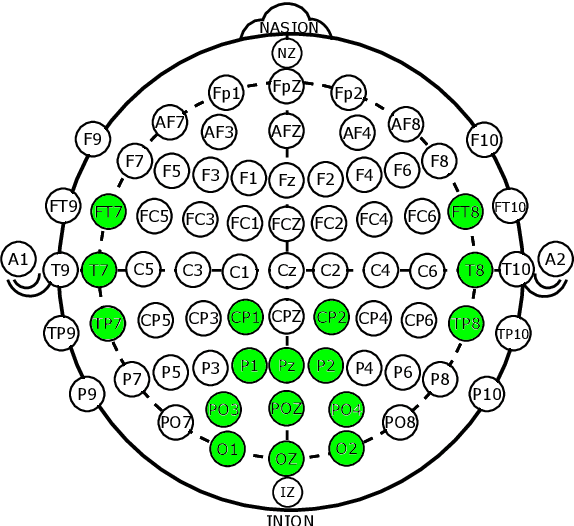
Drowsiness is a major concern for drivers and one of the leading causes of traffic accidents. Advances in Cognitive Neuroscience and Computer Science have enabled the detection of drivers' drowsiness by using Brain-Computer Interfaces (BCIs) and Machine Learning (ML). Nevertheless, several challenges remain open and should be faced. First, a comprehensive enough evaluation of drowsiness detection performance using a heterogeneous set of ML algorithms is missing in the literature. Last, it is needed to study the detection performance of scalable ML models suitable for groups of subjects and compare it with the individual models proposed in the literature. To improve these limitations, this work presents an intelligent framework that employs BCIs and features based on electroencephalography (EEG) for detecting drowsiness in driving scenarios. The SEED-VIG dataset is used to feed different ML regressors and three-class classifiers and then evaluate, analyze, and compare the best-performing models for individual subjects and groups of them. More in detail, regarding individual models, Random Forest (RF) obtained a 78% f1-score, improving the 58% obtained by models used in the literature such as Support Vector Machine (SVM). Concerning scalable models, RF reached a 79% f1-score, demonstrating the effectiveness of these approaches. The lessons learned can be summarized as follows: i) not only SVM but also other models not sufficiently explored in the literature are relevant for drowsiness detection, and ii) scalable approaches suitable for groups of subjects are effective to detect drowsiness, even when new subjects that are not included in the models training are evaluated.