 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFe: Communication-Efficient Decentralized Federated Learning via Distillation and Prototypes
Paper and Code
Dec 15, 2024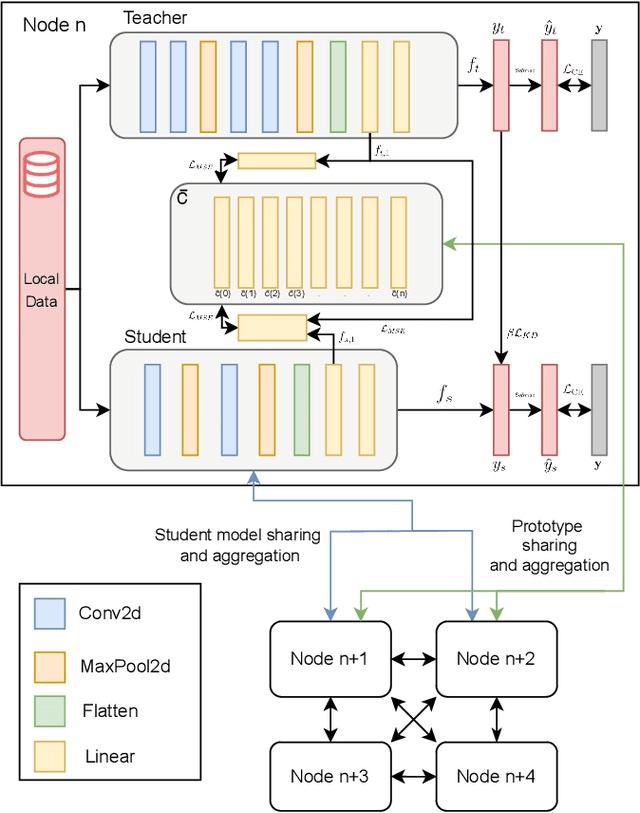
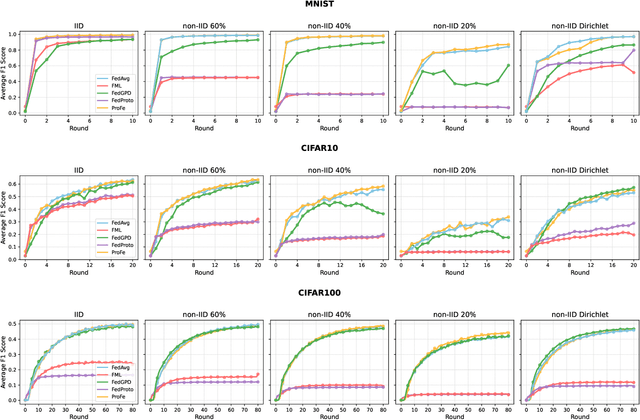
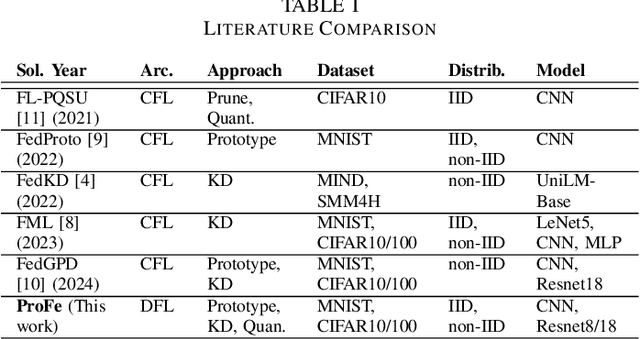

Decentralized Federated Learning (DFL) trains models in a collaborative and privacy-preserving manner while removing model centralization risks and improving communication bottlenecks. However, DFL faces challenges in efficient communication management and model aggregation within decentralized environments, especially with heterogeneous data distributions. Thus, this paper introduces ProFe, a novel communication optimization algorithm for DFL that combines knowledge distillation, prototype learning, and quantization techniques. ProFe utilizes knowledge from large local models to train smaller ones for aggregation, incorporates prototypes to better learn unseen classes, and applies quantization to reduce data transmitted during communication rounds. The performance of ProFe has been validated and compared to the literature by using benchmark datasets like MNIST, CIFAR10, and CIFAR100. Results showed that the proposed algorithm reduces communication costs by up to ~40-50% while maintaining or improving model performance. In addition, it adds ~20% training time due to increased complexity, generating a trade-off.