 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemo: A Practical Testbed for Decentralized Federated Learning on Physical Edge Devices
May 12, 2025Federated Learning (FL) enables collaborative model training without sharing raw data, preserving participant privacy. Decentralized FL (DFL) eliminates reliance on a central server, mitigating the single point of failure inherent in the traditional FL paradigm, while introducing deployment challenges on resource-constrained devices. To evaluate real-world applicability, this work designs and deploys a physical testbed using edge devices such as Raspberry Pi and Jetson Nano. The testbed is built upon a DFL training platform, NEBULA, and extends it with a power monitoring module to measure energy consumption during training. Experiments across multiple datasets show that model performance is influenced by the communication topology, with denser topologies leading to better outcomes in DFL settings.
AugMixCloak: A Defense against Membership Inference Attacks via Image Transformation
May 11, 2025



Traditional machine learning (ML) raises serious privacy concerns, while federated learning (FL) mitigates the risk of data leakage by keeping data on local devices. However, the training process of FL can still leak sensitive information, which adversaries may exploit to infer private data. One of the most prominent threats is the membership inference attack (MIA), where the adversary aims to determine whether a particular data record was part of the training set. This paper addresses this problem through a two-stage defense called AugMixCloak. The core idea is to apply data augmentation and principal component analysis (PCA)-based information fusion to query images, which are detected by perceptual hashing (pHash) as either identical to or highly similar to images in the training set. Experimental results show that AugMixCloak successfully defends against both binary classifier-based MIA and metric-based MIA across five datasets and various decentralized FL (DFL) topologies. Compared with regularization-based defenses, AugMixCloak demonstrates stronger protection. Compared with confidence score masking, AugMixCloak exhibits better generalization.
DMPA: Model Poisoning Attacks on Decentralized Federated Learning for Model Differences
Feb 07, 2025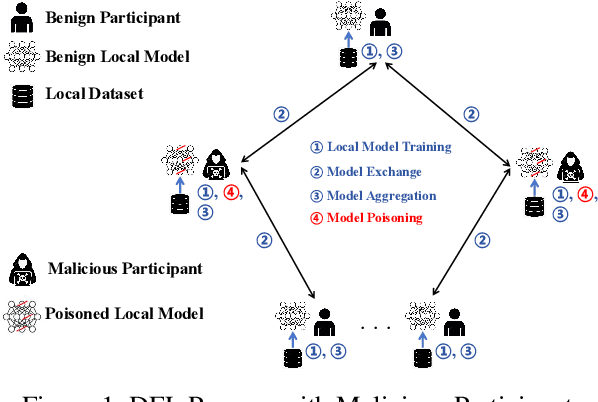
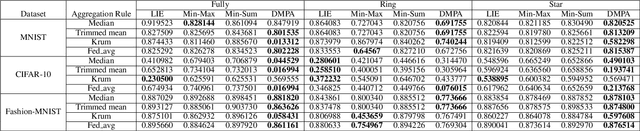
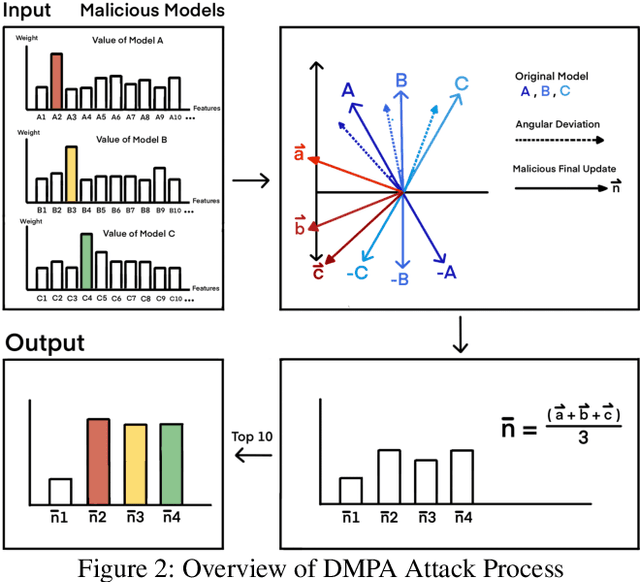
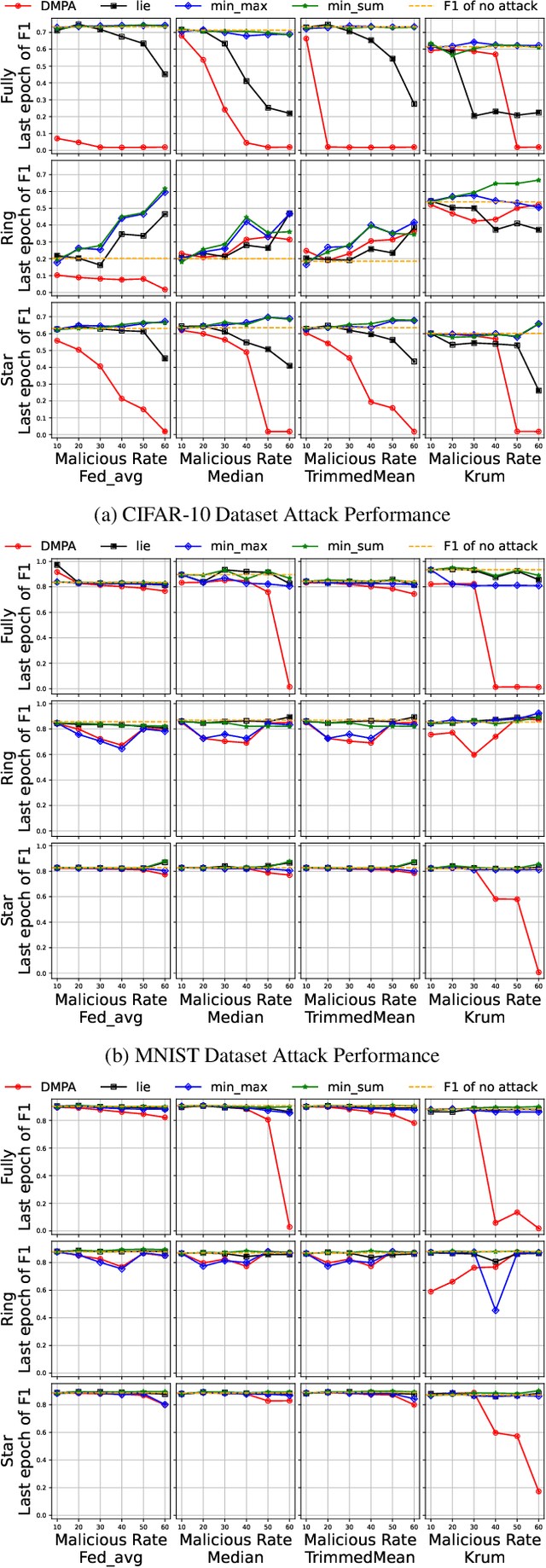
Federated learning (FL) has garnered significant attention as a prominent privacy-preserving Machine Learning (ML) paradigm. Decentralized FL (DFL) eschews traditional FL's centralized server architecture, enhancing the system's robustness and scalability. However, these advantages of DFL also create new vulnerabilities for malicious participants to execute adversarial attacks, especially model poisoning attacks. In model poisoning attacks, malicious participants aim to diminish the performance of benign models by creating and disseminating the compromised model. Existing research on model poisoning attacks has predominantly concentrated on undermining global models within the Centralized FL (CFL) paradigm, while there needs to be more research in DFL. To fill the research gap, this paper proposes an innovative model poisoning attack called DMPA. This attack calculates the differential characteristics of multiple malicious client models and obtains the most effective poisoning strategy, thereby orchestrating a collusive attack by multiple participants. The effectiveness of this attack is validated across multiple datasets, with results indicating that the DMPA approach consistently surpasses existing state-of-the-art FL model poisoning attack strategies.
ColNet: Collaborative Optimization in Decentralized Federated Multi-task Learning Systems
Jan 17, 2025
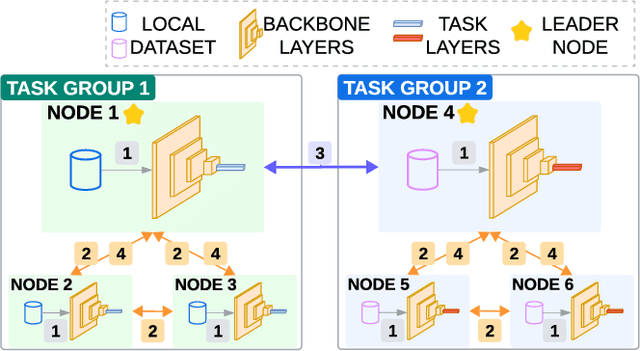


The integration of Federated Learning (FL) and Multi-Task Learning (MTL) has been explored to address client heterogeneity, with Federated Multi-Task Learning (FMTL) treating each client as a distinct task. However, most existing research focuses on data heterogeneity (e.g., addressing non-IID data) rather than task heterogeneity, where clients solve fundamentally different tasks. Additionally, much of the work relies on centralized settings with a server managing the federation, leaving the more challenging domain of decentralized FMTL largely unexplored. Thus, this work bridges this gap by proposing ColNet, a framework designed for heterogeneous tasks in decentralized federated environments. ColNet divides models into the backbone and task-specific layers, forming groups of similar clients, with group leaders performing conflict-averse cross-group aggregation. A pool of experiments with different federations demonstrated ColNet outperforms the compared aggregation schemes in decentralized settings with label and task heterogeneity scenarios.
From Models to Network Topologies: A Topology Inference Attack in Decentralized Federated Learning
Jan 06, 2025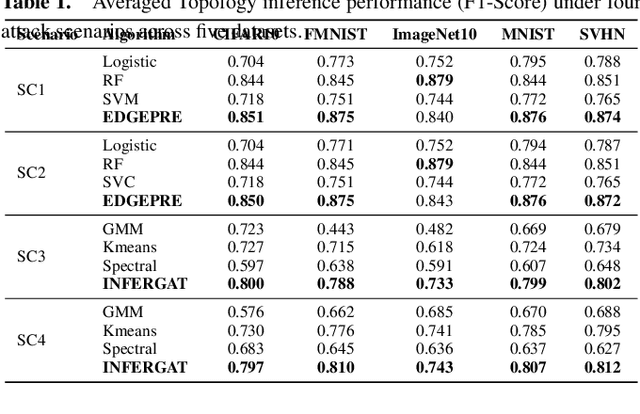
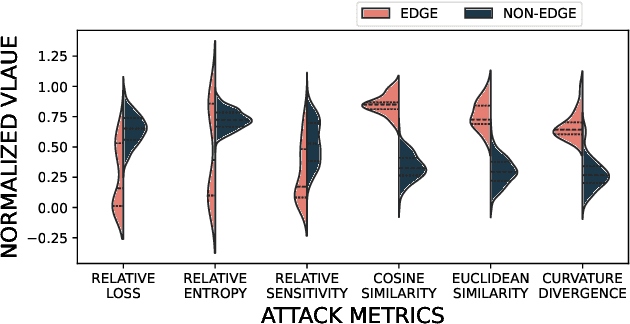
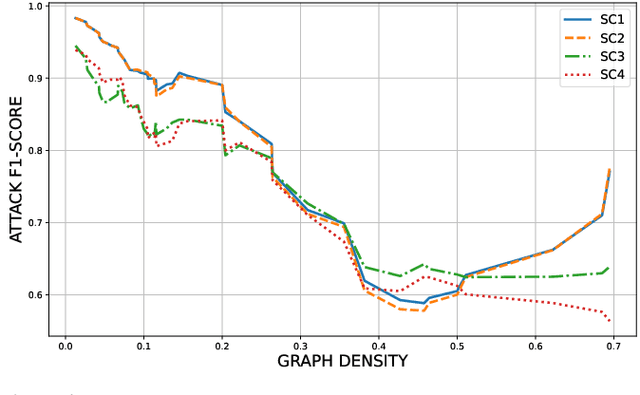
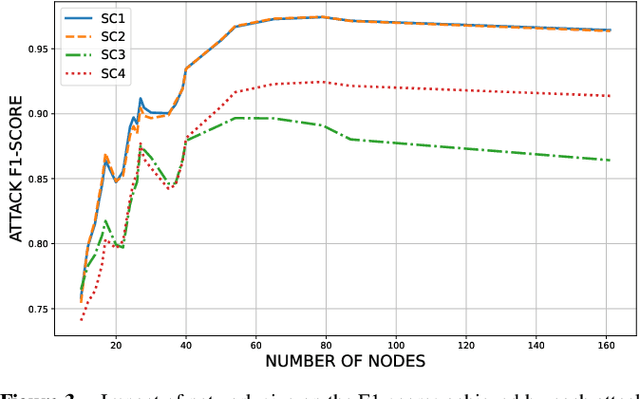
Federated Learning (FL) is widely recognized as a privacy-preserving machine learning paradigm due to its model-sharing mechanism that avoids direct data exchange. However, model training inevitably leaves exploitable traces that can be used to infer sensitive information. In Decentralized FL (DFL), the overlay topology significantly influences its models' convergence, robustness, and security. This study explores the feasibility of inferring the overlay topology of DFL systems based solely on model behavior, introducing a novel Topology Inference Attack. A taxonomy of topology inference attacks is proposed, categorizing them by the attacker's capabilities and knowledge. Practical attack strategies are developed for different scenarios, and quantitative experiments are conducted to identify key factors influencing the attack effectiveness. Experimental results demonstrate that analyzing only the public models of individual nodes can accurately infer the DFL topology, underscoring the risk of sensitive information leakage in DFL systems. This finding offers valuable insights for improving privacy preservation in decentralized learning environments.
FedEP: Tailoring Attention to Heterogeneous Data Distribution with Entropy Pooling for Decentralized Federated Learning
Oct 10, 2024



Federated Learning (FL) performance is highly influenced by data distribution across clients, and non-Independent and Identically Distributed (non-IID) leads to a slower convergence of the global model and a decrease in model effectiveness. The existing algorithms for solving the non-IID problem are focused on the traditional centralized FL (CFL), where a central server is used for model aggregation. However, in decentralized FL (DFL), nodes lack the overall vision of the federation. To address the non-IID problem in DFL, this paper proposes a novel DFL aggregation algorithm, Federated Entropy Pooling (FedEP). FedEP mitigates the client drift problem by incorporating the statistical characteristics of local distributions instead of any actual data. Prior to training, each client conducts a local distribution fitting using a Gaussian Mixture Model (GMM) and shares the resulting statistical characteristics with its neighbors. After receiving the statistical characteristics shared by its neighbors, each node tries to fit the global data distribution. In the aggregation phase, each node calculates the Kullback-Leibler (KL) divergences of the local data distribution over the fitted global data distribution, giving the weights to generate the aggregated model. Extensive experiments have demonstrated that FedEP can achieve faster convergence and show higher test performance than state-of-the-art approaches.
De-VertiFL: A Solution for Decentralized Vertical Federated Learning
Oct 08, 2024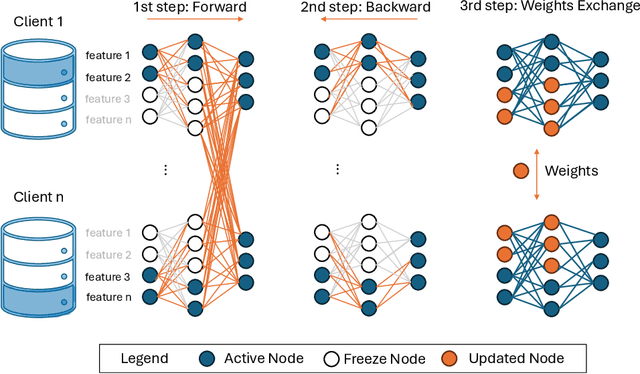

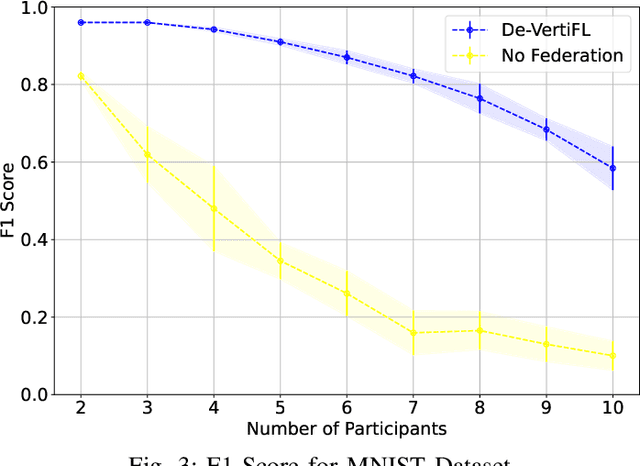
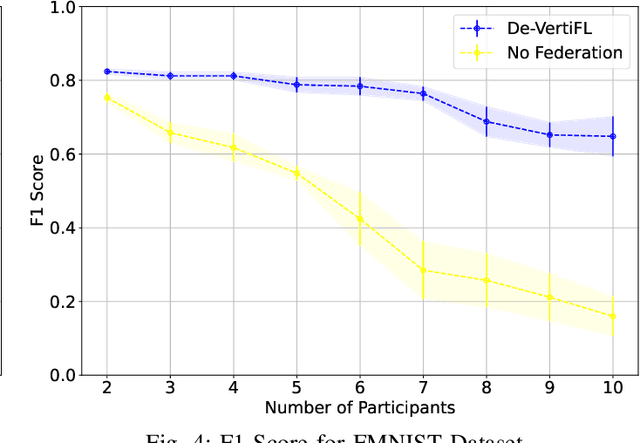
Federated Learning (FL), introduced in 2016, was designed to enhance data privacy in collaborative model training environments. Among the FL paradigm, horizontal FL, where clients share the same set of features but different data samples, has been extensively studied in both centralized and decentralized settings. In contrast, Vertical Federated Learning (VFL), which is crucial in real-world decentralized scenarios where clients possess different, yet sensitive, data about the same entity, remains underexplored. Thus, this work introduces De-VertiFL, a novel solution for training models in a decentralized VFL setting. De-VertiFL contributes by introducing a new network architecture distribution, an innovative knowledge exchange scheme, and a distributed federated training process. Specifically, De-VertiFL enables the sharing of hidden layer outputs among federation clients, allowing participants to benefit from intermediate computations, thereby improving learning efficiency. De-VertiFL has been evaluated using a variety of well-known datasets, including both image and tabular data, across binary and multiclass classification tasks. The results demonstrate that De-VertiFL generally surpasses state-of-the-art methods in F1-score performance, while maintaining a decentralized and privacy-preserving framework.
Sentinel: An Aggregation Function to Secure Decentralized Federated Learning
Oct 14, 2023The rapid integration of Federated Learning (FL) into networking encompasses various aspects such as network management, quality of service, and cybersecurity while preserving data privacy. In this context, Decentralized Federated Learning (DFL) emerges as an innovative paradigm to train collaborative models, addressing the single point of failure limitation. However, the security and trustworthiness of FL and DFL are compromised by poisoning attacks, negatively impacting its performance. Existing defense mechanisms have been designed for centralized FL and they do not adequately exploit the particularities of DFL. Thus, this work introduces Sentinel, a defense strategy to counteract poisoning attacks in DFL. Sentinel leverages the accessibility of local data and defines a three-step aggregation protocol consisting of similarity filtering, bootstrap validation, and normalization to safeguard against malicious model updates. Sentinel has been evaluated with diverse datasets and various poisoning attack types and threat levels, improving the state-of-the-art performance against both untargeted and targeted poisoning attacks.
CyberForce: A Federated Reinforcement Learning Framework for Malware Mitigation
Aug 11, 2023The expansion of the Internet-of-Things (IoT) paradigm is inevitable, but vulnerabilities of IoT devices to malware incidents have become an increasing concern. Recent research has shown that the integration of Reinforcement Learning with Moving Target Defense (MTD) mechanisms can enhance cybersecurity in IoT devices. Nevertheless, the numerous new malware attacks and the time that agents take to learn and select effective MTD techniques make this approach impractical for real-world IoT scenarios. To tackle this issue, this work presents CyberForce, a framework that employs Federated Reinforcement Learning (FRL) to collectively and privately determine suitable MTD techniques for mitigating diverse zero-day attacks. CyberForce integrates device fingerprinting and anomaly detection to reward or penalize MTD mechanisms chosen by an FRL-based agent. The framework has been evaluated in a federation consisting of ten devices of a real IoT platform. A pool of experiments with six malware samples affecting the devices has demonstrated that CyberForce can precisely learn optimum MTD mitigation strategies. When all clients are affected by all attacks, the FRL agent exhibits high accuracy and reduced training time when compared to a centralized RL agent. In cases where different clients experience distinct attacks, the CyberForce clients gain benefits through the transfer of knowledge from other clients and similar attack behavior. Additionally, CyberForce showcases notable robustness against data poisoning attacks.
RCVaR: an Economic Approach to Estimate Cyberattacks Costs using Data from Industry Reports
Jul 20, 2023



Digitization increases business opportunities and the risk of companies being victims of devastating cyberattacks. Therefore, managing risk exposure and cybersecurity strategies is essential for digitized companies that want to survive in competitive markets. However, understanding company-specific risks and quantifying their associated costs is not trivial. Current approaches fail to provide individualized and quantitative monetary estimations of cybersecurity impacts. Due to limited resources and technical expertise, SMEs and even large companies are affected and struggle to quantify their cyberattack exposure. Therefore, novel approaches must be placed to support the understanding of the financial loss due to cyberattacks. This article introduces the Real Cyber Value at Risk (RCVaR), an economical approach for estimating cybersecurity costs using real-world information from public cybersecurity reports. RCVaR identifies the most significant cyber risk factors from various sources and combines their quantitative results to estimate specific cyberattacks costs for companies. Furthermore, RCVaR extends current methods to achieve cost and risk estimations based on historical real-world data instead of only probability-based simulations. The evaluation of the approach on unseen data shows the accuracy and efficiency of the RCVaR in predicting and managing cyber risks. Thus, it shows that the RCVaR is a valuable addition to cybersecurity planning and risk management processes.