 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Multi-label Completion for Semantic Document Labelling with Taxonomy-Aware Parallel Learning
Dec 18, 2024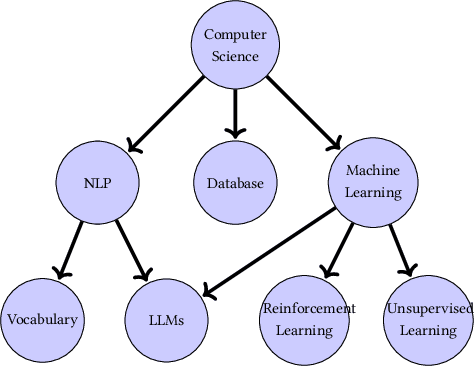
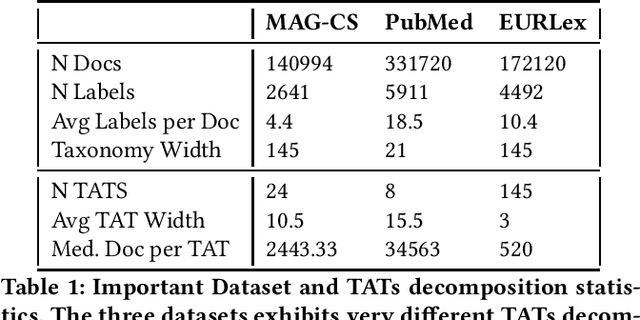
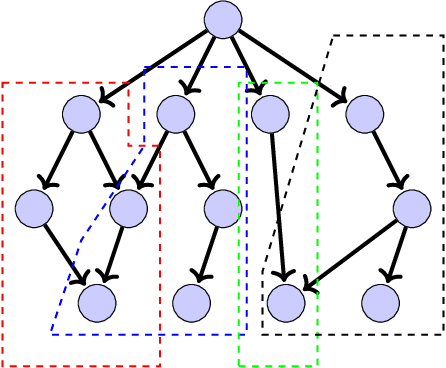
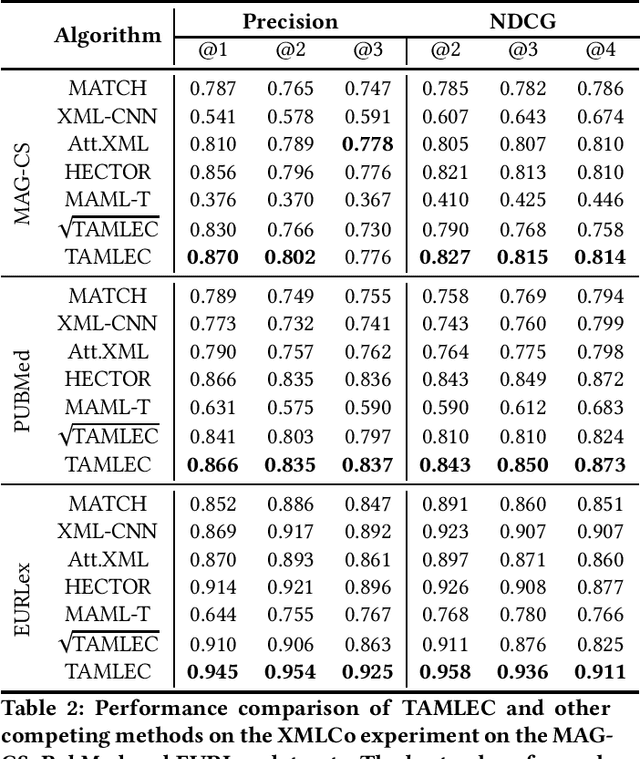
In Extreme Multi Label Completion (XMLCo), the objective is to predict the missing labels of a collection of documents. Together with XML Classification, XMLCo is arguably one of the most challenging document classification tasks, as the very high number of labels (at least ten of thousands) is generally very large compared to the number of available labelled documents in the training dataset. Such a task is often accompanied by a taxonomy that encodes the labels organic relationships, and many methods have been proposed to leverage this hierarchy to improve the results of XMLCo algorithms. In this paper, we propose a new approach to this problem, TAMLEC (Taxonomy-Aware Multi-task Learning for Extreme multi-label Completion). TAMLEC divides the problem into several Taxonomy-Aware Tasks, i.e. subsets of labels adapted to the hierarchical paths of the taxonomy, and trains on these tasks using a dynamic Parallel Feature sharing approach, where some parts of the model are shared between tasks while others are task-specific. Then, at inference time, TAMLEC uses the labels available in a document to infer the appropriate tasks and to predict missing labels. To achieve this result, TAMLEC uses a modified transformer architecture that predicts ordered sequences of labels on a Weak-Semilattice structure that is naturally induced by the tasks. This approach yields multiple advantages. First, our experiments on real-world datasets show that TAMLEC outperforms state-of-the-art methods for various XMLCo problems. Second, TAMLEC is by construction particularly suited for few-shots XML tasks, where new tasks or labels are introduced with only few examples, and extensive evaluations highlight its strong performance compared to existing methods.
Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
Jun 21, 2024Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
Spider4SPARQL: A Complex Benchmark for Evaluating Knowledge Graph Question Answering Systems
Sep 28, 2023



With the recent spike in the number and availability of Large Language Models (LLMs), it has become increasingly important to provide large and realistic benchmarks for evaluating Knowledge Graph Question Answering (KBQA) systems. So far the majority of benchmarks rely on pattern-based SPARQL query generation approaches. The subsequent natural language (NL) question generation is conducted through crowdsourcing or other automated methods, such as rule-based paraphrasing or NL question templates. Although some of these datasets are of considerable size, their pitfall lies in their pattern-based generation approaches, which do not always generalize well to the vague and linguistically diverse questions asked by humans in real-world contexts. In this paper, we introduce Spider4SPARQL - a new SPARQL benchmark dataset featuring 9,693 previously existing manually generated NL questions and 4,721 unique, novel, and complex SPARQL queries of varying complexity. In addition to the NL/SPARQL pairs, we also provide their corresponding 166 knowledge graphs and ontologies, which cover 138 different domains. Our complex benchmark enables novel ways of evaluating the strengths and weaknesses of modern KGQA systems. We evaluate the system with state-of-the-art KGQA systems as well as LLMs, which achieve only up to 45\% execution accuracy, demonstrating that Spider4SPARQL is a challenging benchmark for future research.
Bridging the Gap between Community and Node Representations: Graph Embedding via Community Detection
Dec 17, 2019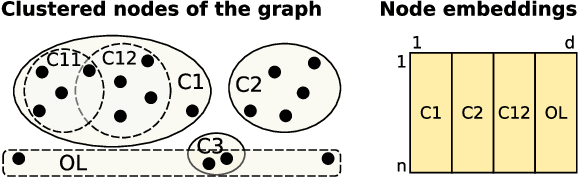
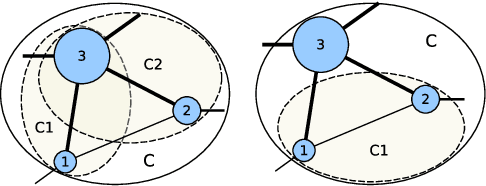
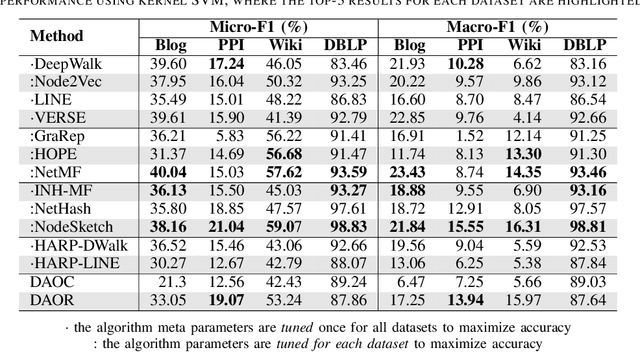
Graph embedding has become a key component of many data mining and analysis systems. Current graph embedding approaches either sample a large number of node pairs from a graph to learn node embeddings via stochastic optimization or factorize a high-order proximity/adjacency matrix of the graph via computationally expensive matrix factorization techniques. These approaches typically require significant resources for the learning process and rely on multiple parameters, which limits their applicability in practice. Moreover, most of the existing graph embedding techniques operate effectively in one specific metric space only (e.g., the one produced with cosine similarity), do not preserve higher-order structural features of the input graph and cannot automatically determine a meaningful number of embedding dimensions. Typically, the produced embeddings are not easily interpretable, which complicates further analyses and limits their applicability. To address these issues, we propose DAOR, a highly efficient and parameter-free graph embedding technique producing metric space-robust, compact and interpretable embeddings without any manual tuning. Compared to a dozen state-of-the-art graph embedding algorithms, DAOR yields competitive results on both node classification (which benefits form high-order proximity) and link prediction (which relies on low-order proximity mostly). Unlike existing techniques, however, DAOR does not require any parameter tuning and improves the embeddings generation speed by several orders of magnitude. Our approach has hence the ambition to greatly simplify and speed up data analysis tasks involving graph representation learning.
A Human-AI Loop Approach for Joint Keyword Discovery and Expectation Estimation in Micropost Event Detection
Dec 02, 2019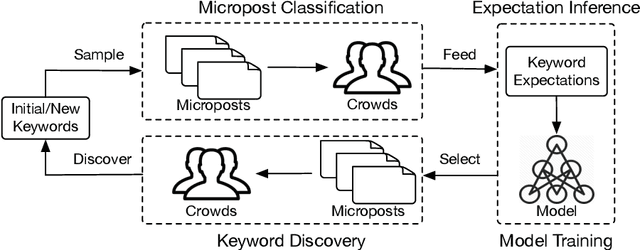

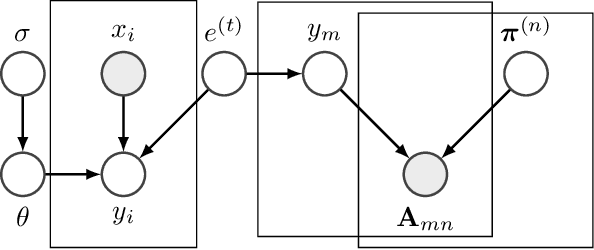
Microblogging platforms such as Twitter are increasingly being used in event detection. Existing approaches mainly use machine learning models and rely on event-related keywords to collect the data for model training. These approaches make strong assumptions on the distribution of the relevant micro-posts containing the keyword -- referred to as the expectation of the distribution -- and use it as a posterior regularization parameter during model training. Such approaches are, however, limited as they fail to reliably estimate the informativeness of a keyword and its expectation for model training. This paper introduces a Human-AI loop approach to jointly discover informative keywords for model training while estimating their expectation. Our approach iteratively leverages the crowd to estimate both keyword specific expectation and the disagreement between the crowd and the model in order to discover new keywords that are most beneficial for model training. These keywords and their expectation not only improve the resulting performance but also make the model training process more transparent. We empirically demonstrate the merits of our approach, both in terms of accuracy and interpretability, on multiple real-world datasets and show that our approach improves the state of the art by 24.3%.
* Accepted at AAAI, 2020
DAOC: Stable Clustering of Large Networks
Sep 19, 2019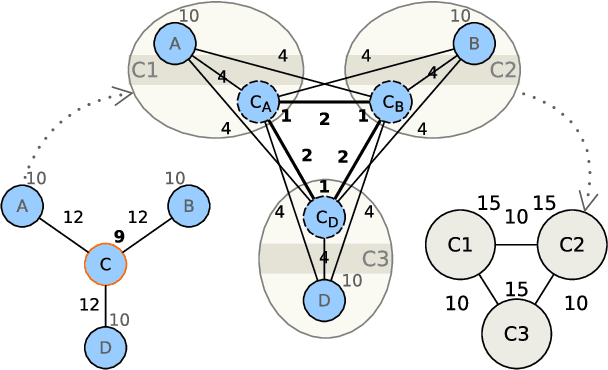
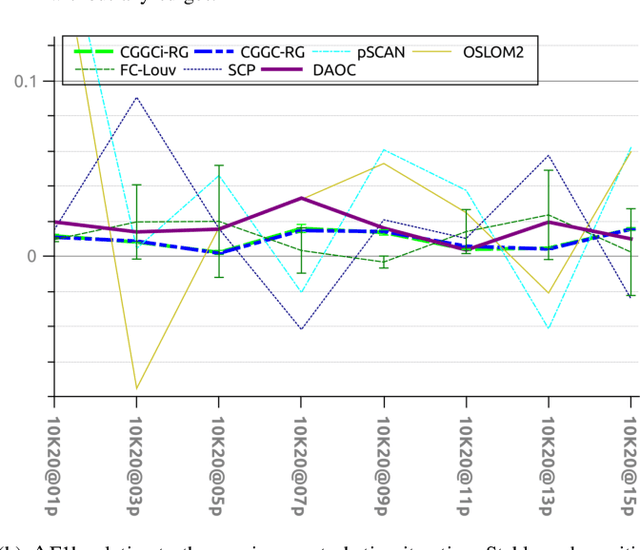
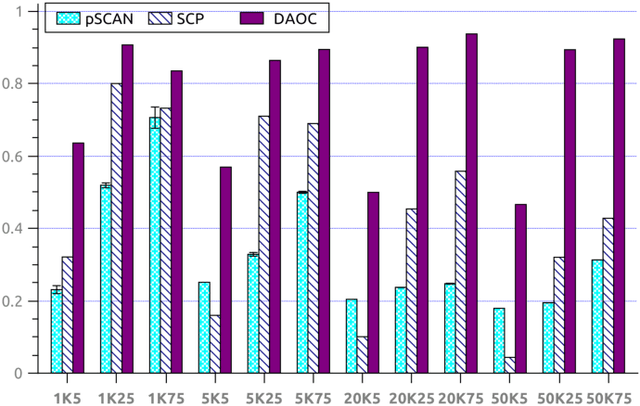
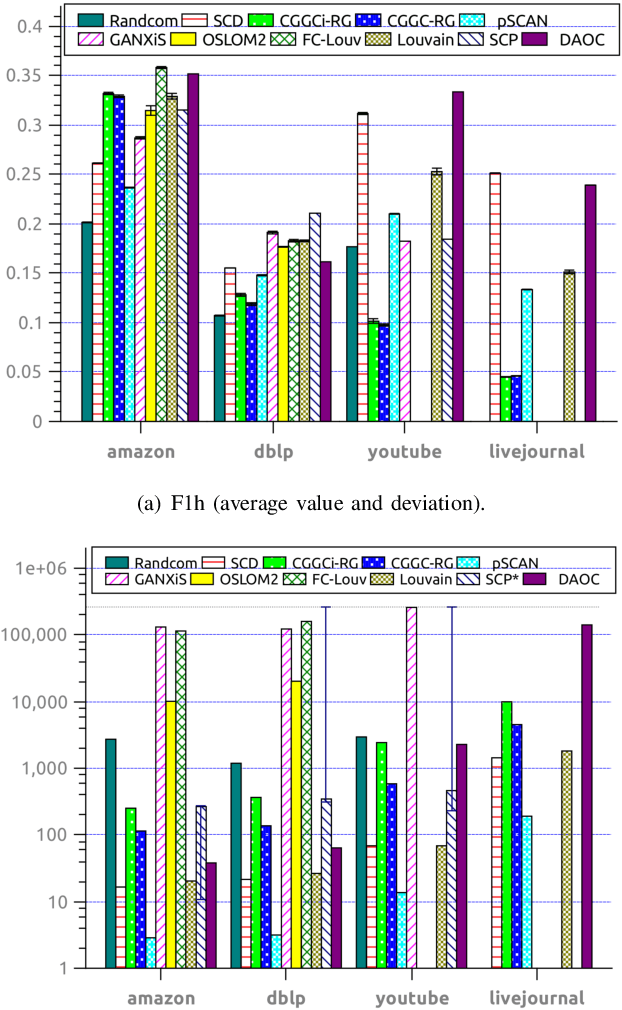
Clustering is a crucial component of many data mining systems involving the analysis and exploration of various data. Data diversity calls for clustering algorithms to be accurate while providing stable (i.e., deterministic and robust) results on arbitrary input networks. Moreover, modern systems often operate with large datasets, which implicitly constrains the complexity of the clustering algorithm. Existing clustering techniques are only partially stable, however, as they guarantee either determinism or robustness. To address this issue, we introduce DAOC, a Deterministic and Agglomerative Overlapping Clustering algorithm. DAOC leverages a new technique called Overlap Decomposition to identify fine-grained clusters in a deterministic way capturing multiple optima. In addition, it leverages a novel consensus approach, Mutual Maximal Gain, to ensure robustness and further improve the stability of the results while still being capable of identifying micro-scale clusters. Our empirical results on both synthetic and real-world networks show that DAOC yields stable clusters while being on average 25% more accurate than state-of-the-art deterministic algorithms without requiring any tuning. Our approach has the ambition to greatly simplify and speed up data analysis tasks involving iterative processing (need for determinism) as well as data fluctuations (need for robustness) and to provide accurate and reproducible results.
Fusing Vector Space Models for Domain-Specific Applications
Sep 05, 2019
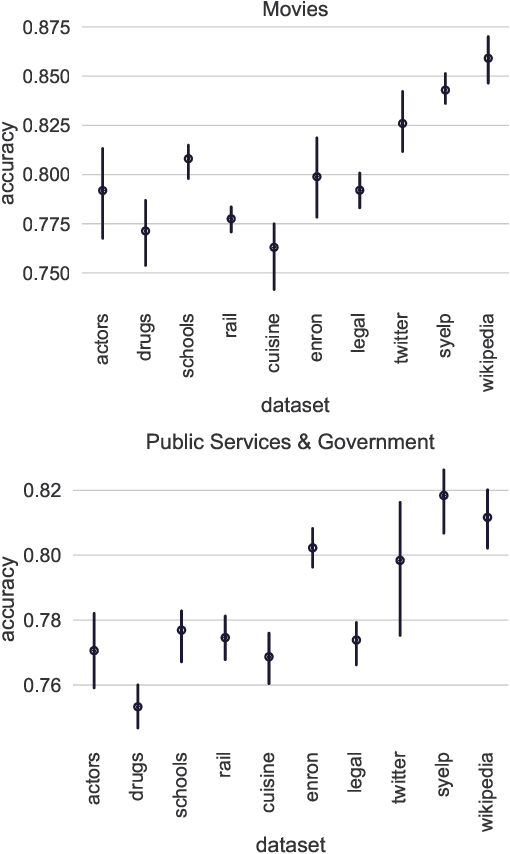
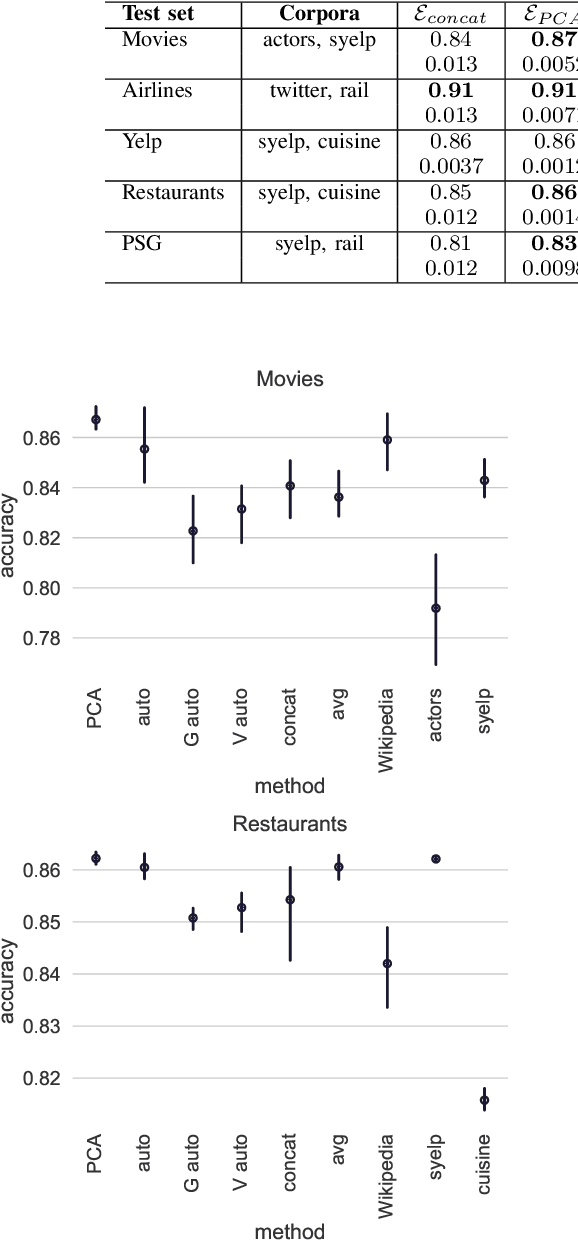
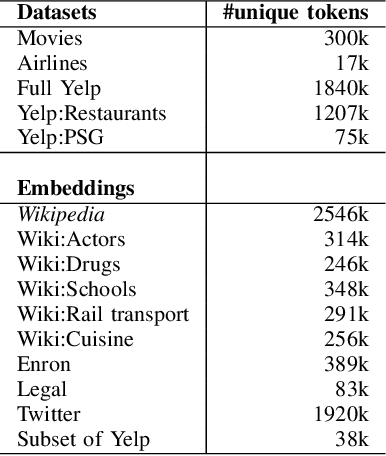
We address the problem of tuning word embeddings for specific use cases and domains. We propose a new method that automatically combines multiple domain-specific embeddings, selected from a wide range of pre-trained domain-specific embeddings, to improve their combined expressive power. Our approach relies on two key components: 1) a ranking function, based on a new embedding similarity measure, that selects the most relevant embeddings to use given a domain and 2) a dimensionality reduction method that combines the selected embeddings to produce a more compact and efficient encoding that preserves the expressiveness. We empirically show that our method produces effective domain-specific embeddings that consistently improve the performance of state-of-the-art machine learning algorithms on multiple tasks, compared to generic embeddings trained on large text corpora.
SECTOR: A Neural Model for Coherent Topic Segmentation and Classification
Feb 13, 2019When searching for information, a human reader first glances over a document, spots relevant sections and then focuses on a few sentences for resolving her intention. However, the high variance of document structure complicates to identify the salient topic of a given section at a glance. To tackle this challenge, we present SECTOR, a model to support machine reading systems by segmenting documents into coherent sections and assigning topic labels to each section. Our deep neural network architecture learns a latent topic embedding over the course of a document. This can be leveraged to classify local topics from plain text and segment a document at topic shifts. In addition, we contribute WikiSection, a publicly available dataset with 242k labeled sections in English and German from two distinct domains: diseases and cities. From our extensive evaluation of 20 architectures, we report a highest score of 71.6% F1 for the segmentation and classification of 30 topics from the English city domain, scored by our SECTOR LSTM model with bloom filter embeddings and bidirectional segmentation. This is a significant improvement of 29.5 points F1 compared to state-of-the-art CNN classifiers with baseline segmentation.