 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-AI Loop Approach for Joint Keyword Discovery and Expectation Estimation in Micropost Event Detection
Dec 02, 2019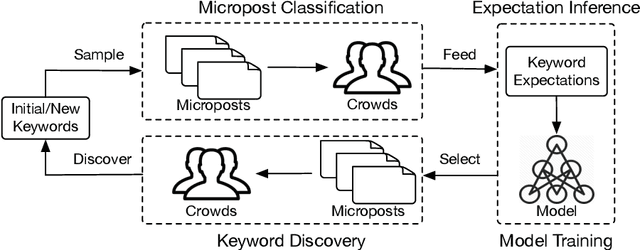

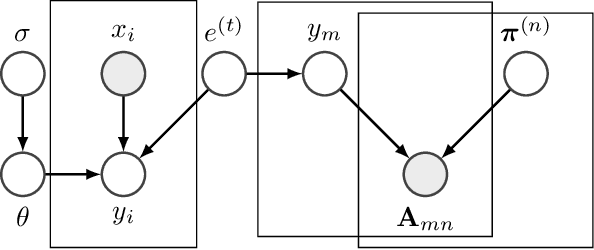
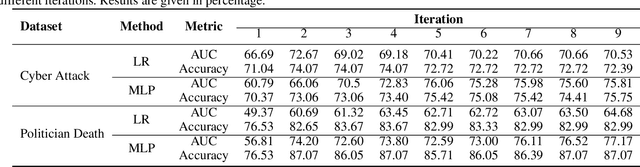
Microblogging platforms such as Twitter are increasingly being used in event detection. Existing approaches mainly use machine learning models and rely on event-related keywords to collect the data for model training. These approaches make strong assumptions on the distribution of the relevant micro-posts containing the keyword -- referred to as the expectation of the distribution -- and use it as a posterior regularization parameter during model training. Such approaches are, however, limited as they fail to reliably estimate the informativeness of a keyword and its expectation for model training. This paper introduces a Human-AI loop approach to jointly discover informative keywords for model training while estimating their expectation. Our approach iteratively leverages the crowd to estimate both keyword specific expectation and the disagreement between the crowd and the model in order to discover new keywords that are most beneficial for model training. These keywords and their expectation not only improve the resulting performance but also make the model training process more transparent. We empirically demonstrate the merits of our approach, both in terms of accuracy and interpretability, on multiple real-world datasets and show that our approach improves the state of the art by 24.3%.
* Accepted at AAAI, 2020
SentiCite: An Approach for Publication Sentiment Analysis
Oct 07, 2019
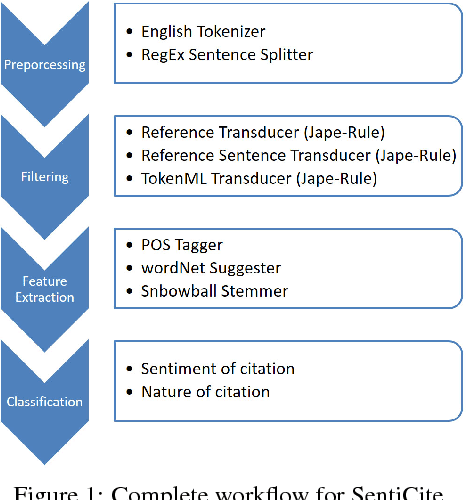
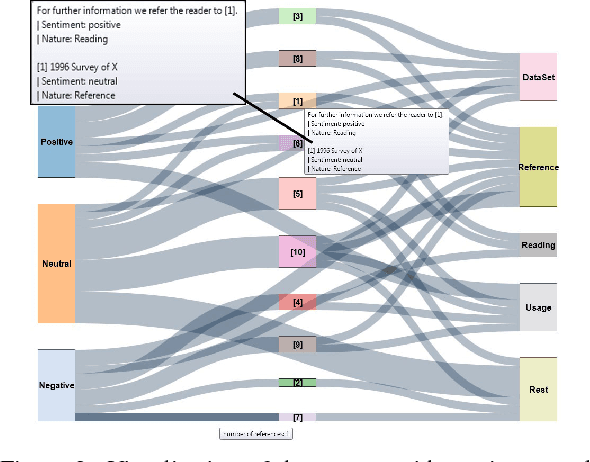

With the rapid growth in the number of scientific publications, year after year, it is becoming increasingly difficult to identify quality authoritative work on a single topic. Though there is an availability of scientometric measures which promise to offer a solution to this problem, these measures are mostly quantitative and rely, for instance, only on the number of times an article is cited. With this approach, it becomes irrelevant if an article is cited 10 times in a positive, negative or neutral way. In this context, it is quite important to study the qualitative aspect of a citation to understand its significance. This paper presents a novel system for sentiment analysis of citations in scientific documents (SentiCite) and is also capable of detecting nature of citations by targeting the motivation behind a citation, e.g., reference to a dataset, reading reference. Furthermore, the paper also presents two datasets (SentiCiteDB and IntentCiteDB) containing about 2,600 citations with their ground truth for sentiment and nature of citation. SentiCite along with other state-of-the-art methods for sentiment analysis are evaluated on the presented datasets. Evaluation results reveal that SentiCite outperforms state-of-the-art methods for sentiment analysis in scientific publications by achieving a F1-measure of 0.71.