 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-AI Loop Approach for Joint Keyword Discovery and Expectation Estimation in Micropost Event Detection
Paper and Code
Dec 02, 2019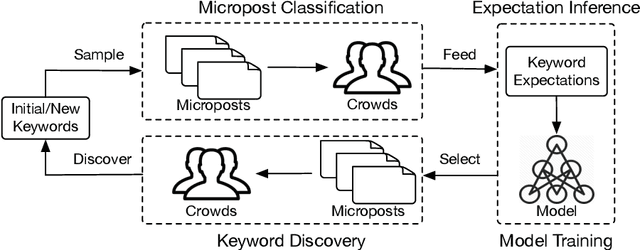

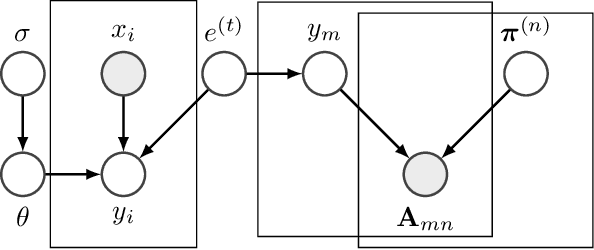
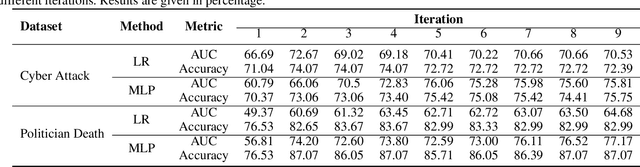
Microblogging platforms such as Twitter are increasingly being used in event detection. Existing approaches mainly use machine learning models and rely on event-related keywords to collect the data for model training. These approaches make strong assumptions on the distribution of the relevant micro-posts containing the keyword -- referred to as the expectation of the distribution -- and use it as a posterior regularization parameter during model training. Such approaches are, however, limited as they fail to reliably estimate the informativeness of a keyword and its expectation for model training. This paper introduces a Human-AI loop approach to jointly discover informative keywords for model training while estimating their expectation. Our approach iteratively leverages the crowd to estimate both keyword specific expectation and the disagreement between the crowd and the model in order to discover new keywords that are most beneficial for model training. These keywords and their expectation not only improve the resulting performance but also make the model training process more transparent. We empirically demonstrate the merits of our approach, both in terms of accuracy and interpretability, on multiple real-world datasets and show that our approach improves the state of the art by 24.3%.