 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Answer Retrieval on Clinical Notes
Aug 02, 2021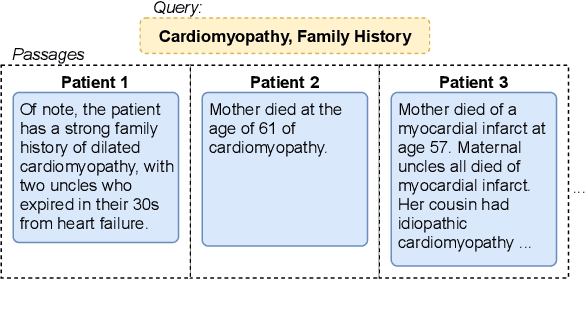
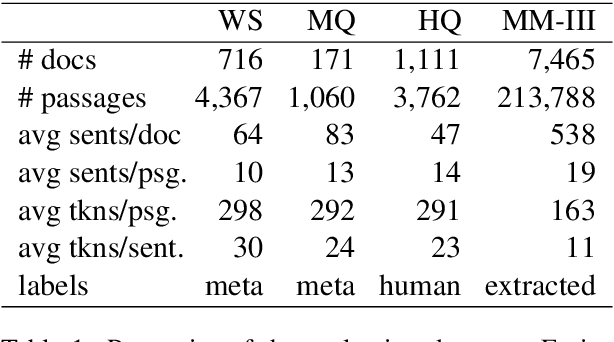
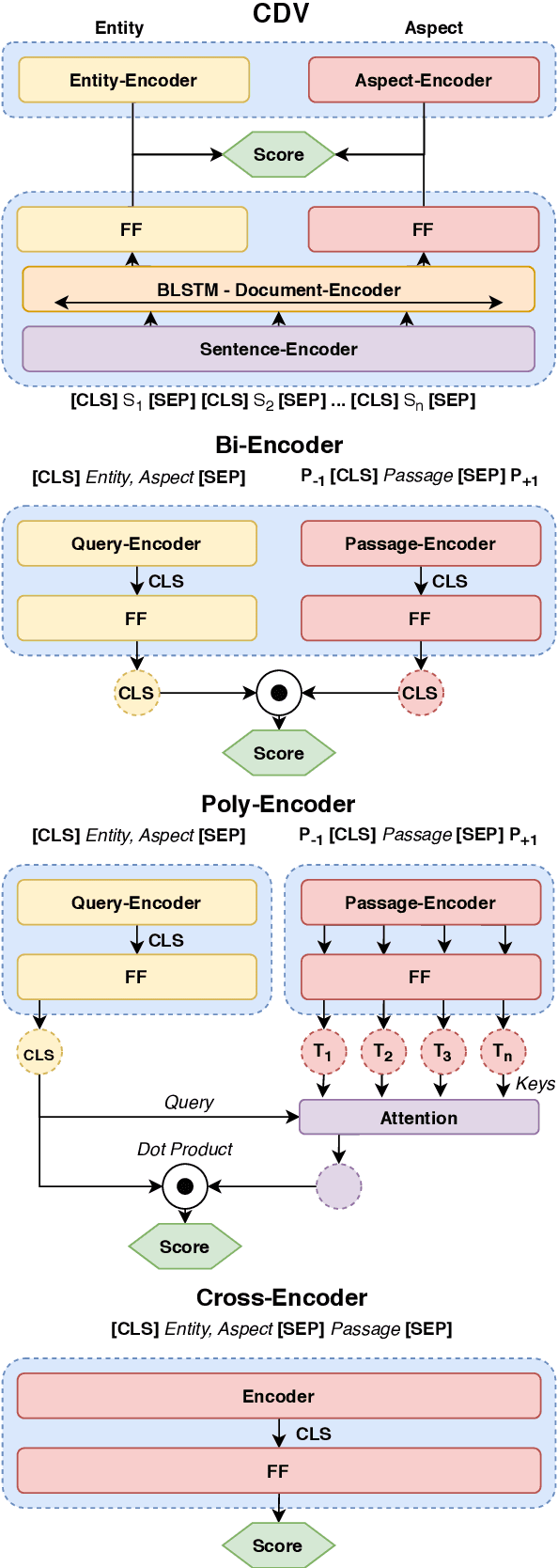
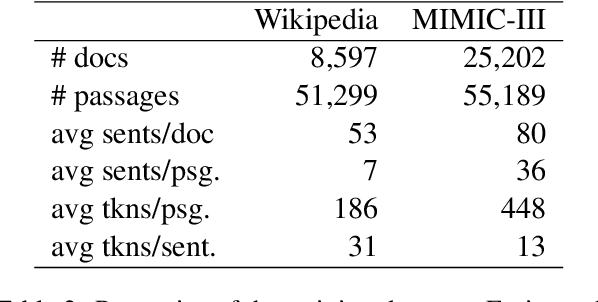
Retrieving answer passages from long documents is a complex task requiring semantic understanding of both discourse and document context. We approach this challenge specifically in a clinical scenario, where doctors retrieve cohorts of patients based on diagnoses and other latent medical aspects. We introduce CAPR, a rule-based self-supervision objective for training Transformer language models for domain-specific passage matching. In addition, we contribute a novel retrieval dataset based on clinical notes to simulate this scenario on a large corpus of clinical notes. We apply our objective in four Transformer-based architectures: Contextual Document Vectors, Bi-, Poly- and Cross-encoders. From our extensive evaluation on MIMIC-III and three other healthcare datasets, we report that CAPR outperforms strong baselines in the retrieval of domain-specific passages and effectively generalizes across rule-based and human-labeled passages. This makes the model powerful especially in zero-shot scenarios where only limited training data is available.
Learning Contextualized Document Representations for Healthcare Answer Retrieval
Feb 03, 2020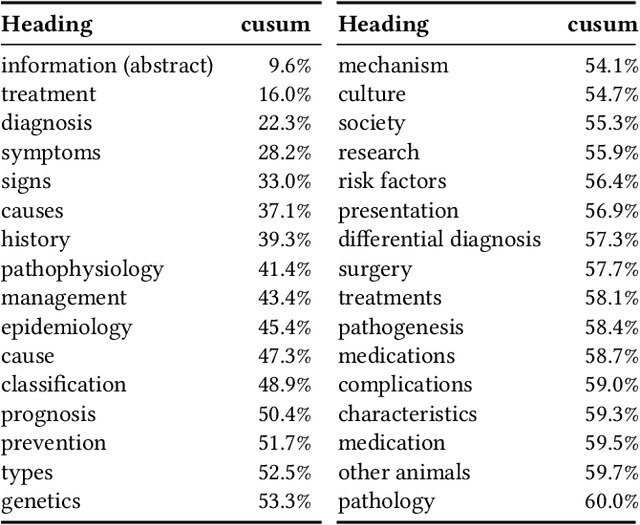
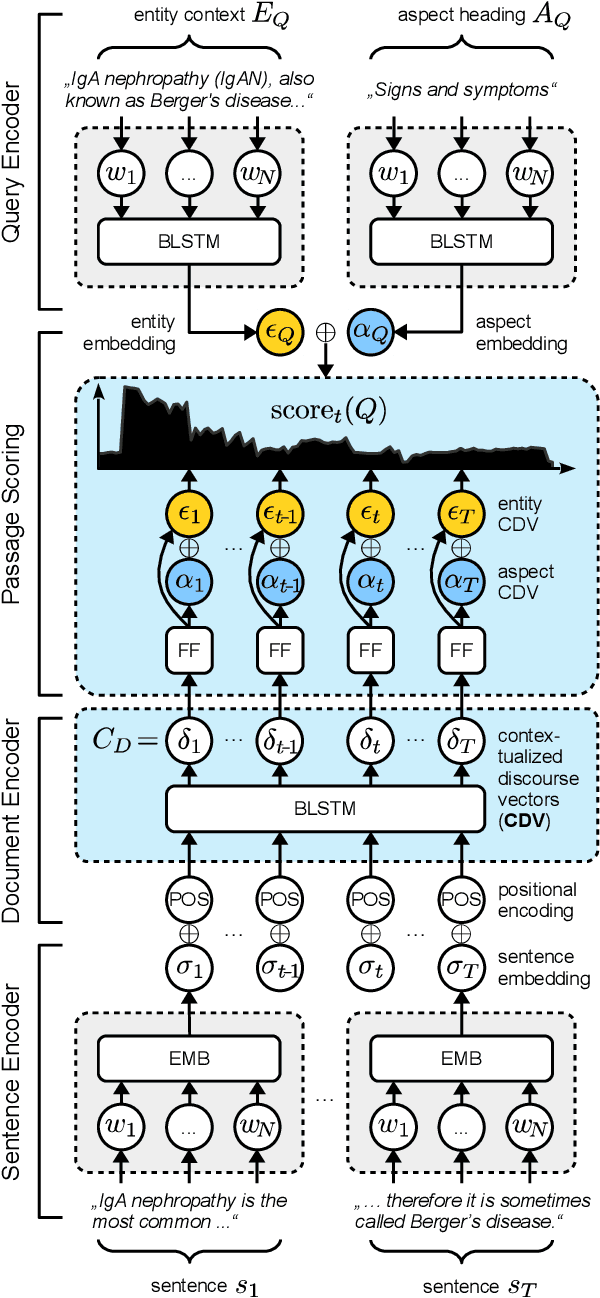
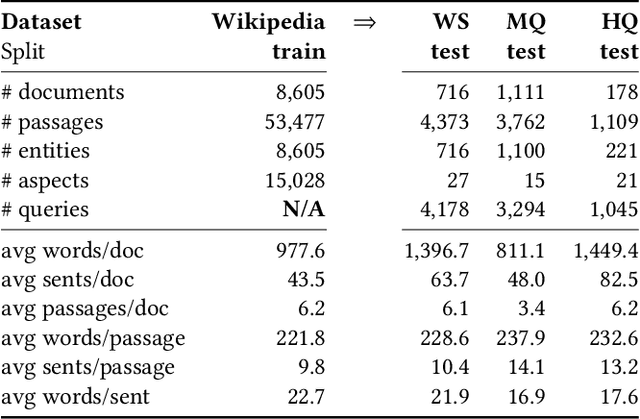
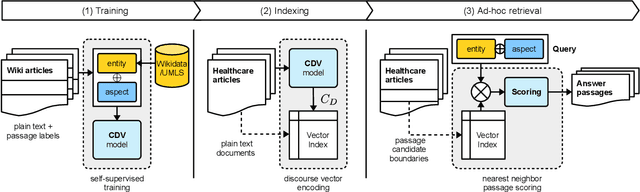
We present Contextual Discourse Vectors (CDV), a distributed document representation for efficient answer retrieval from long healthcare documents. Our approach is based on structured query tuples of entities and aspects from free text and medical taxonomies. Our model leverages a dual encoder architecture with hierarchical LSTM layers and multi-task training to encode the position of clinical entities and aspects alongside the document discourse. We use our continuous representations to resolve queries with short latency using approximate nearest neighbor search on sentence level. We apply the CDV model for retrieving coherent answer passages from nine English public health resources from the Web, addressing both patients and medical professionals. Because there is no end-to-end training data available for all application scenarios, we train our model with self-supervised data from Wikipedia. We show that our generalized model significantly outperforms several state-of-the-art baselines for healthcare passage ranking and is able to adapt to heterogeneous domains without additional fine-tuning.
SECTOR: A Neural Model for Coherent Topic Segmentation and Classification
Feb 13, 2019When searching for information, a human reader first glances over a document, spots relevant sections and then focuses on a few sentences for resolving her intention. However, the high variance of document structure complicates to identify the salient topic of a given section at a glance. To tackle this challenge, we present SECTOR, a model to support machine reading systems by segmenting documents into coherent sections and assigning topic labels to each section. Our deep neural network architecture learns a latent topic embedding over the course of a document. This can be leveraged to classify local topics from plain text and segment a document at topic shifts. In addition, we contribute WikiSection, a publicly available dataset with 242k labeled sections in English and German from two distinct domains: diseases and cities. From our extensive evaluation of 20 architectures, we report a highest score of 71.6% F1 for the segmentation and classification of 30 topics from the English city domain, scored by our SECTOR LSTM model with bloom filter embeddings and bidirectional segmentation. This is a significant improvement of 29.5 points F1 compared to state-of-the-art CNN classifiers with baseline segmentation.
Robust Named Entity Recognition in Idiosyncratic Domains
Aug 24, 2016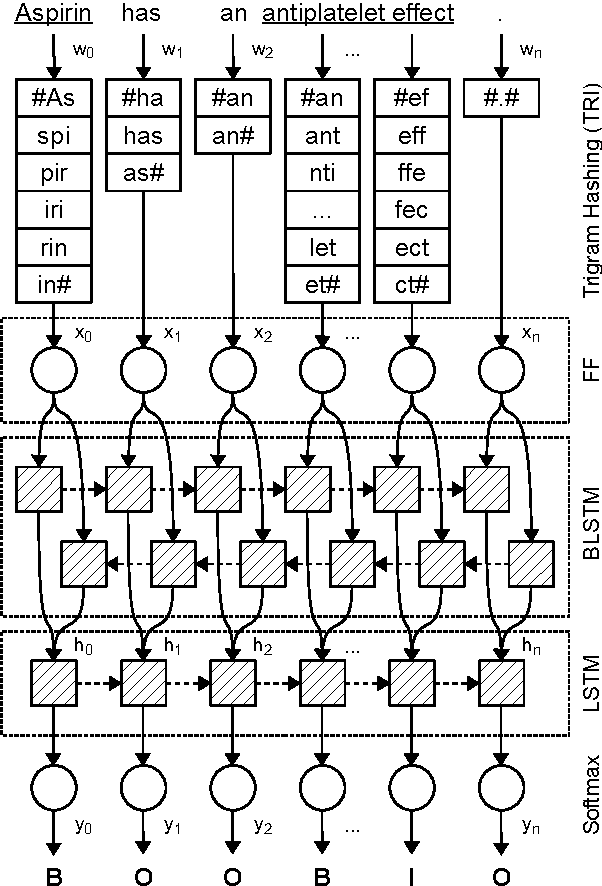
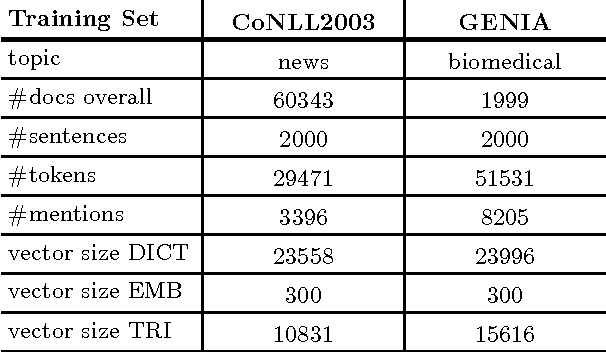
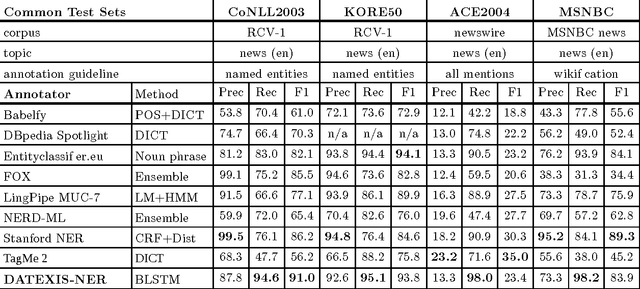
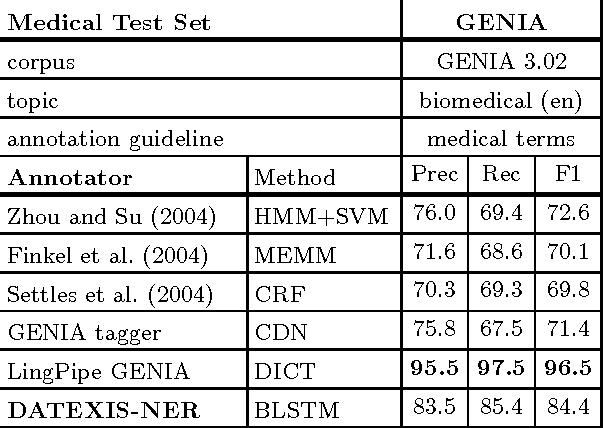
Named entity recognition often fails in idiosyncratic domains. That causes a problem for depending tasks, such as entity linking and relation extraction. We propose a generic and robust approach for high-recall named entity recognition. Our approach is easy to train and offers strong generalization over diverse domain-specific language, such as news documents (e.g. Reuters) or biomedical text (e.g. Medline). Our approach is based on deep contextual sequence learning and utilizes stacked bidirectional LSTM networks. Our model is trained with only few hundred labeled sentences and does not rely on further external knowledge. We report from our results F1 scores in the range of 84-94% on standard datasets.