 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Vector Space Models for Domain-Specific Applications
Sep 05, 2019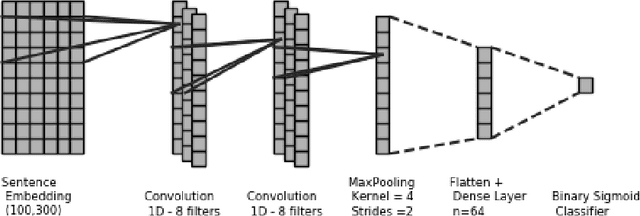
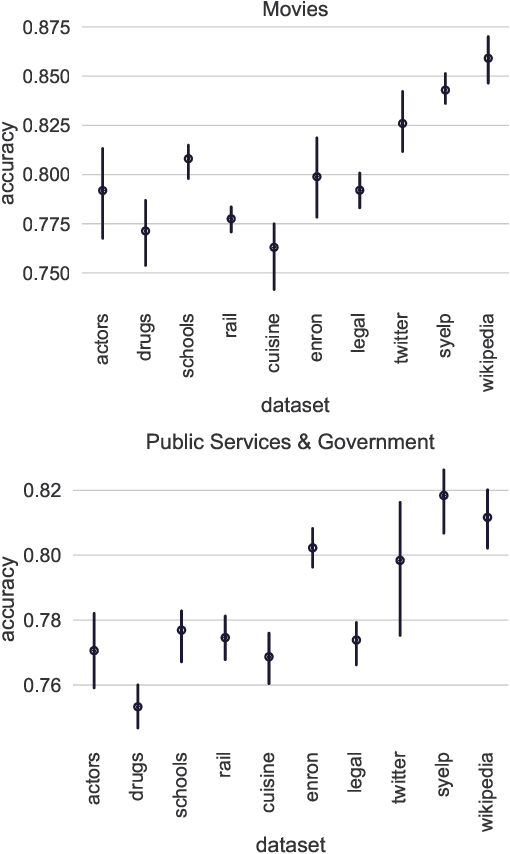
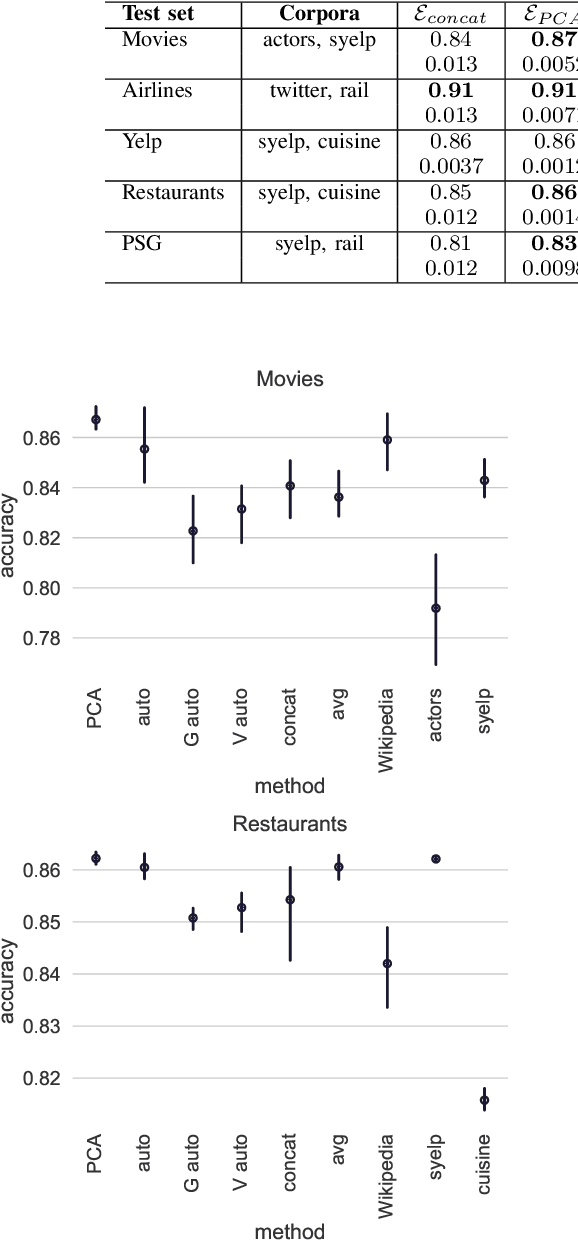
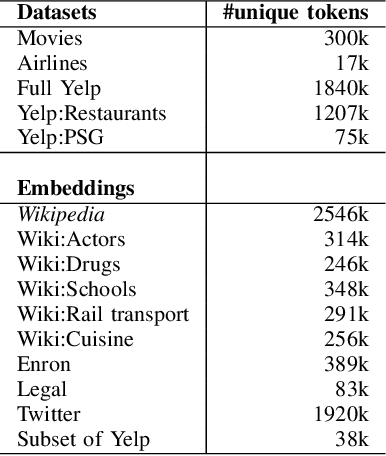
We address the problem of tuning word embeddings for specific use cases and domains. We propose a new method that automatically combines multiple domain-specific embeddings, selected from a wide range of pre-trained domain-specific embeddings, to improve their combined expressive power. Our approach relies on two key components: 1) a ranking function, based on a new embedding similarity measure, that selects the most relevant embeddings to use given a domain and 2) a dimensionality reduction method that combines the selected embeddings to produce a more compact and efficient encoding that preserves the expressiveness. We empirically show that our method produces effective domain-specific embeddings that consistently improve the performance of state-of-the-art machine learning algorithms on multiple tasks, compared to generic embeddings trained on large text corpora.